









1、安装:使用pip install scrapy;
假如使用了Fiddler作为代理服务器进行调试分析,为了避免该软件的影响:
打开Fiddler,进入“Tools——>Fiddler Options——>Connections”,将“Act as system proxy on startup”和“Monitor all connections”的勾选取消。
2、(1)、使用命令“scrapy startproject 项目名”创建一个项目;
--logfile=FILE 参数指定日志文件,在startproject和项目名之间
--loglevel=LEVEL 主要控制日志信息的等级
从高到低依次为CRICAL(生严重的错误),ERROR(发生了必须立即处理的错误),WARNING(出现了一些警告信息,即存在潜在的错误),INFO(输出一些提示信息),DEBUG(输出一些调试信息,常用于开发阶段)
--nolog参数可以控制不输出日志信息
(2)、命令“cd 爬虫项目所在目录”,使用genspider命令创建Scrapy爬虫文件steve,定义爬取www.sina.com。
scrapy genspider -t basic steve www.sina.com爬虫模版有:basic、crawl、csvfeed、xmlfeed。

3、项目目录结构:
scrapy.cfg 是爬虫项目的配置文件
items.py 爬虫项目的数据容器文件,定义我们获取的数据
pipelines.py 管道文件,对items中定义的数据进一步加工与处理
setting.py 设置文件
spider文件夹下放置爬虫部分文件
(1)在items中数据以字典形式储存
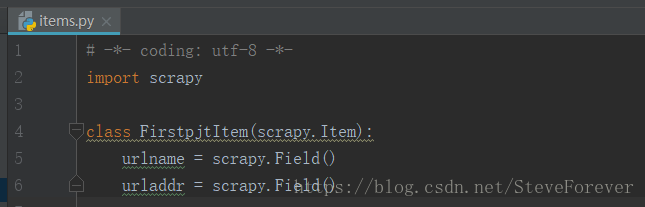
(2)spider中的常用属性和方法:
start_requests() 该方法默认读取start_urls属性中定义的网址,为每一个网址生成一个Request请求对象,并返回迭代对象
make_requests_from_url(url) 该方法会被start_requests() 调用,负责实现生成Request请求对象
closed(reason) 关闭Spider时,该方法被调用
3、Spider的编写
(1)、
#steve.py
import scrapy
from firstpjt.items import FirstpjtItem
class SteveSpider(scrapy.Spider):
name = 'steve'
allowed_domains = ['www.sina.com']
start_urls = (
'http://news.sina.com.cn/c/2018-08-12/doc-ihhqtawx1023013.shtml',
'http://sports.sina.com.cn/basketball/nba/2018-08-12/doc-ihhqtawx1782775.shtml',
'http://news.sina.com.cn/w/2018-08-12/doc-ihhqtawx0403181.shtml'
)
def parse(self, response):
item = FirstpjtItem()
item["urlname"]=response.xpath("/html/head/title/text()")
print(item["urlname"])
运行结果:

(2)、start_urls为默认的起始网址,通过重写start_requests()方法实现自定义起始网址:
# steve.py
# -*- coding: utf-8 -*-
import scrapy
from firstpjt.items import FirstpjtItem
class SteveSpider(scrapy.Spider):
name = 'steve'
#allowed_domains = ['www.sina.com']
start_urls = (
'http://news.sina.com.cn/c/2018-08-12/doc-ihhqtawx1023013.shtml',
'http://sports.sina.com.cn/basketball/nba/2018-08-12/doc-ihhqtawx1782775.shtml',
'http://news.sina.com.cn/w/2018-08-12/doc-ihhqtawx0403181.shtml'
)
# 自定义起始网址
urls2 = (
'https://www.csdn.net/',
'http://www.ifeng.com/',
'https://www.suning.com/?utm_source=hao123&utm_medium=mingzhan'
)
# 重写start_requests()方法
def start_requests(self):
for url in self.urls2:
# 调用默认self.make_requests_from_url(url)方法生成具体请求并通过yield返回
yield self.make_requests_from_url(url)
def parse(self, response):
item = FirstpjtItem()
item["urlname"] = response.xpath("/html/head/title/text()")
print(item["urlname"])
运行结果:















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









