






创建项目:
在所需创建的位置,shift+右键选择打开Powershell。
输入“scrapy startproject 项目名称”
例:
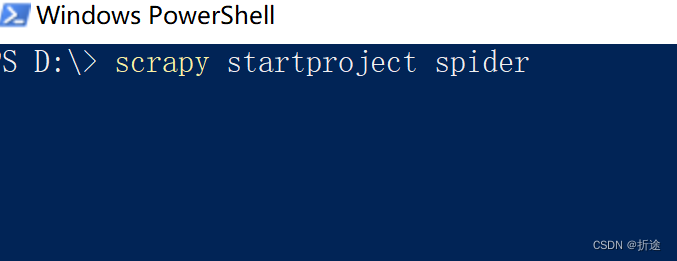
找到路径下与项目名称名字相同的文件夹,用IDE打开。
在终端(记得切换到项目文件夹下)输入“scrapy genspider 爬虫名称 所访问的域名”
例:
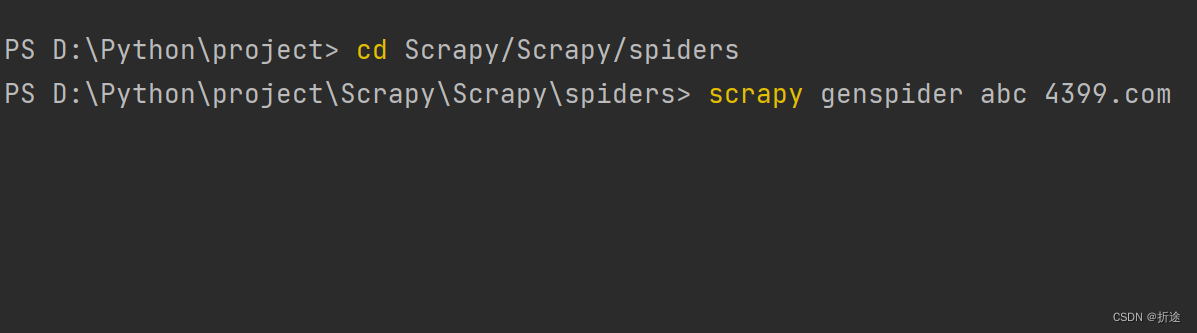
然后就会出现一个py文件。
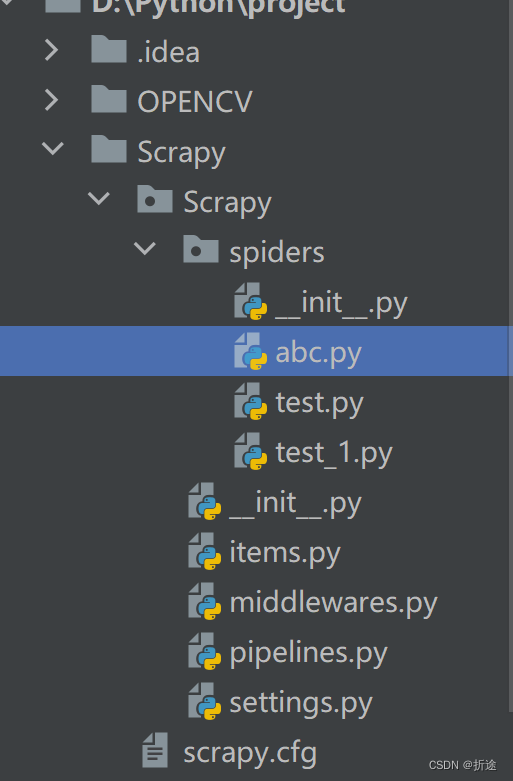
创建爬虫文件不是只有这种格式“scrapy genspider 爬虫名称 所访问的域名”.
终端输入"scrapy genspider -l"可查看所有的模板.
例:

所演示的是创建basic模板的.(基本够用)
若要创建crawl模板则输入
scrapy genspider -t crawl 爬虫名 域名crawl比basic多了个网页链接提取规则,即可提取所访问页面中所有符合规则的网页链接,适用于爬取有规律的网站.
启动爬虫:
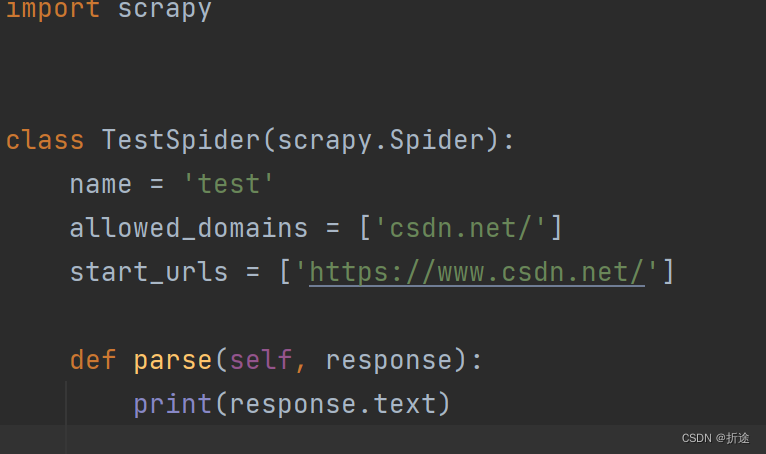
在爬虫名称文件下的parse中设置要爬取的内容或者要进行的操作.
其中"response"表示所爬取到的全部内容.
例:
在终端中输入"scrapy crawl 爬虫名"启动爬虫.
例:

得到结果:
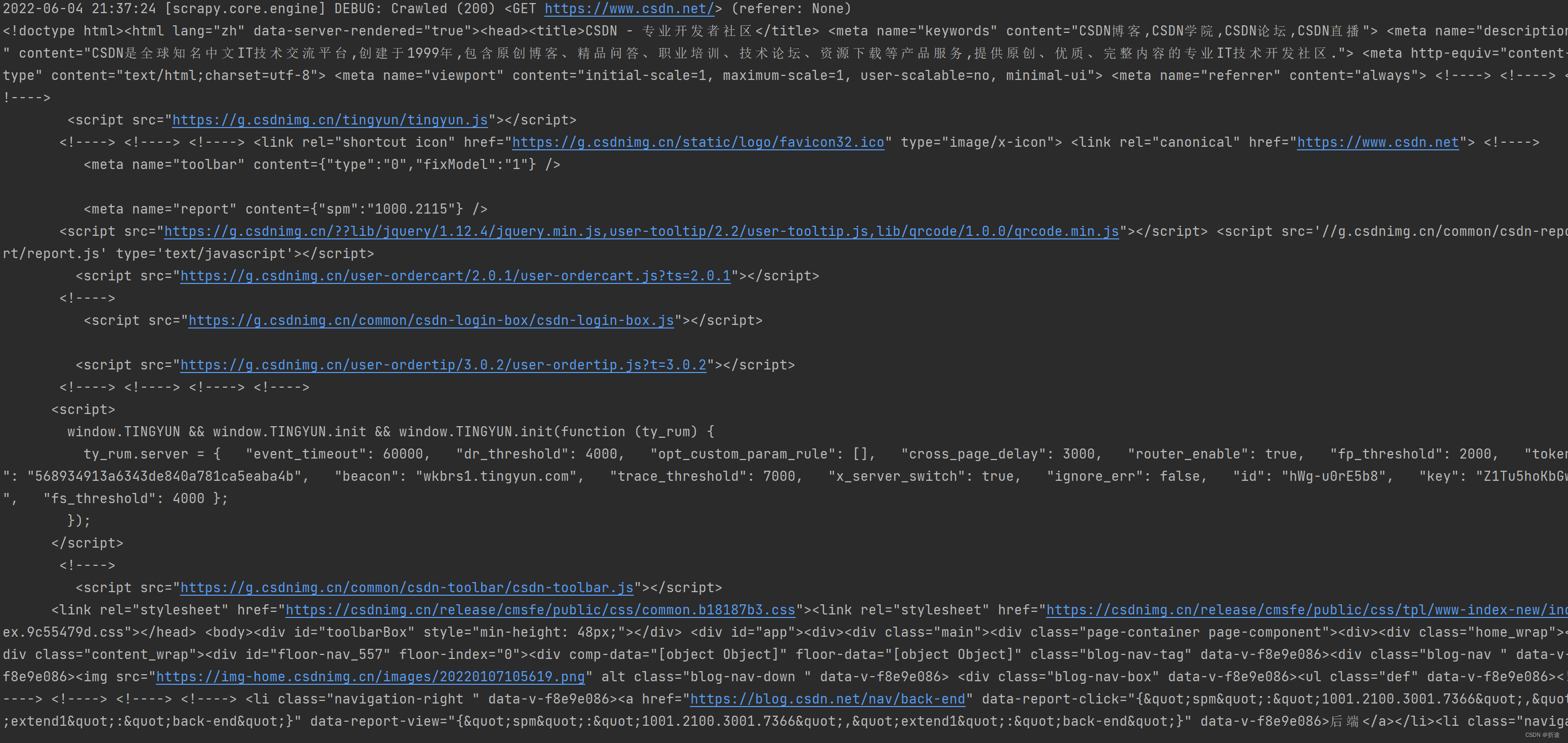















 2999
2999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









