







DOM模型
DOM树
DOM结构构成的基本要素为”节点”,而文档的DOM结构就是有层次化的节点组成,在DOM模型中,节点的概念很宽泛,整个文档(Document)就是一个节点,称为文档节点,HTML中的标记(Tag)也是一种节点,成为元素节点,还有一些其他类型的节点,例如属性节点,Entity节点,CDataSection节点,注释(Comment)节点等。由于DOM的定义是与语言无关的,所以标准中所有这些都是接口,同时,因为支持不同类型的语言,所以没有对内存的管理机制做任何方面的规定,同时这些不同语言的不同实现只需要符合标准定义的接口即可,而实现者通常可以把这些实现细节隐藏起来。
DOM中Document的IDL接口定义如下:
interface Document : Node {
readonly attribute DocumentType doctype;
readonly attribute DOMImplementation implementation;
readonly attribute Element documentElement;
Element createElement(in DOMString tagName) raises(DOMException);
DocumentFragment createDocumentFragment();
Text createTextNode(in DOMString data);
Comment createComment(in DOMString data);
CDATASection createCDataSection(in DOMString data) raises(DOMException);
ProcessingInstruction createProcessingInstruction(in DOMString target, in DOMString data) raises(DOMException);
Attr createAttribute(in DOMString name) raises(DOMException);
EntityReference createEntityReference(in DOMString name) raises (DOMException);
NodeList getElementsByTagName(in DOMString tagname);
};其中重点关注的HTML文档继承自文档接口,同时又有些自己的扩展,包括新的属性和接口,这些都跟HTML文档的具体应用有关,具体接口如下:
interface HTMLDocument : Document {
attribute DOMString title;
readonly attribute DOMString referrer;
readonly attribute DOMString domain;
readonly attribute DOMString URL;
attribute HTMLElement body;
readonly attribute HTMLCollection images;
readonly attribute HTMLCollection applets;
readonly attribute HTMLCollection links;
readonly attribute HTMLCollection forms;
readonly attribute HTMLCollection anchors;
attribute DOMString cookie;
void open();
void close();
void write(in DOMString text);
void writeln(in DOMString text);
Element getElementById(in DOMString elementId);
NodeList getElementByName(in DOMString elementName);
};DOM树
将DOM节点和各种子节点按照层次结构组织构成一个DOM树行结构,举例如下:
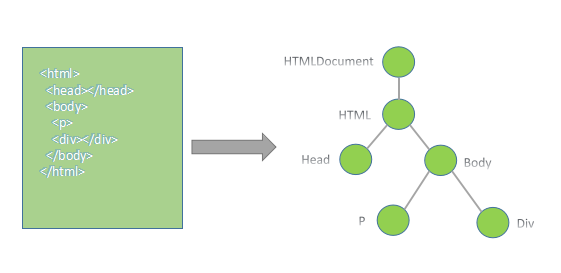
DOM树的根就是HTMLDocument,HTML网页中的标签则被转换成一个个的元素节点,同数据结构中树形结构类似,这些节点之间也存在着对应的父子和兄弟关系。
HTML解释器
解释过程
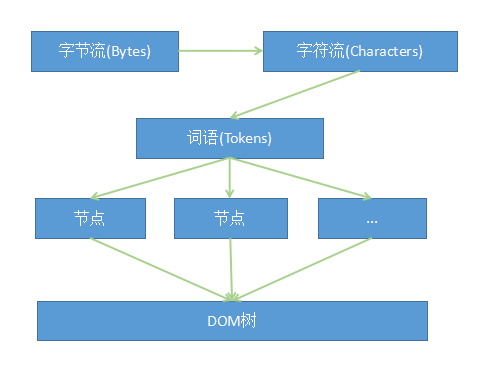
解释器的作用就是将本地磁盘或者网络获取的HTML网页和资源从字节流解释成DOM树结构,Webkit的处理过程如下:
WebKit为了完成这个过程,引入了比较复杂的基础设施类,下图描述了WebKit在构建DOM树时需要使用到的主要类:
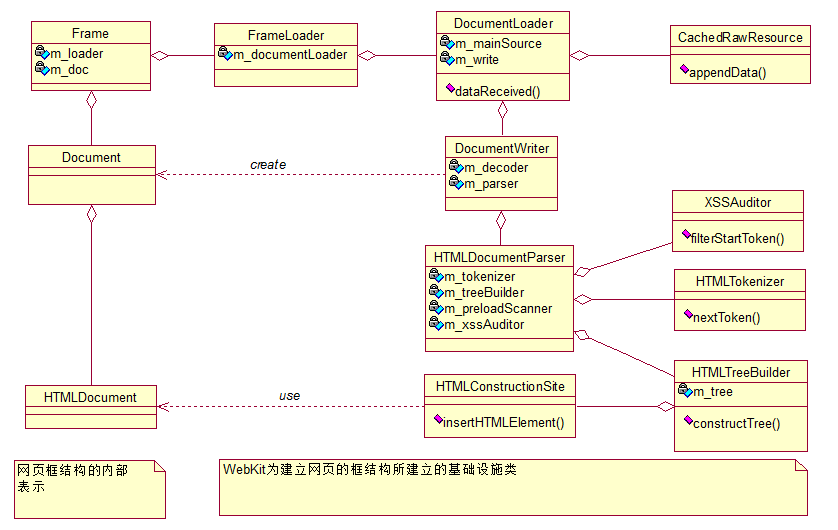
框对应与“Frame”类,而文档对应于“HTMLDocument”类,所以框内包含文档,HTMLDocument类继承自Document类,为了遵循DOM标准,因为Document有两个子类,另一个为XMLDocument,右边FrameLoader类是框中内容的加载器,类似与资源和资源的加载器,因为Frame对象中包含Document对象,所以WebKit需要DocumentLoader类帮助加载HTML文档并从字节流到构建成DOM树,DocumentWriter类是一个辅助类,它会创建DOM树的根节点HTMLDocument对象,该类包括两个成员变量,一个用于文档的字符解码,另一个为HTML解释器HTMLDocumentParser类。其中HTMLDocumentParser是一个管理类,包括了用于各种工作的其它类,例如字符串到词语需要用到词法分析器HTMLTokenizer类,该管理类读入字符串,输出一个词语,这些词语经过XSSAuditor做完安全检查之后,输出到HTMLTreeBuilder类,HTMLTreeBuilder类负责DOM树的建立,它本身能够通过词语创建一个个的节点对象,然后借由HTMLConstructionSite类来将这些节点对象构建成一个DOM树。
词法分析到构建节点
在进行词法分析之前解释器要检查网页内容使用的编码格式,以便后面使用合适的解码器,webkit使用相应的解码器将字节流转换成字符串。词法分析的工作由HTMLTokenizer类来完成,输入的为字符串,输出的为一个个的词语,词法分析器的主要接口为“nextToken”函数,对于该函数的调用者而言,它首先设置需要解释的字符串,然后循环调用NextToken函数知道处理结束,“nextToken”方法每次输出一个词语,同时会标记输入的字符串,表明哪些字符串已经被处理过了,因此每次词法分析器都会根据上次设置的内部状态和上次处理之后的字符串来生成一个新的词语,“nextToken”函数内部使用了超过70种状态,对于每个不同的状态都会有相应的处理逻辑,对于词语的类别,HTMLToken类定义了6种词语类别,包括DOCTYPE, StartTag,EndTag,Comment,Character和EndOfFile。根据XSS的安全机制,对于解析出来的词语可能会阻碍某些内容的进一步处理,因此XSSAuditor类会过滤这些被阻止的内容,通过的词语将被WebKit用来构建DOM节点,这一步奏由HTMLDocumentParser类调用HTMLTreeBuilder类的“constructTree”函数来实现,该函数实际利用processToken“函数来处理HTMLToken定义的6中词语类型。
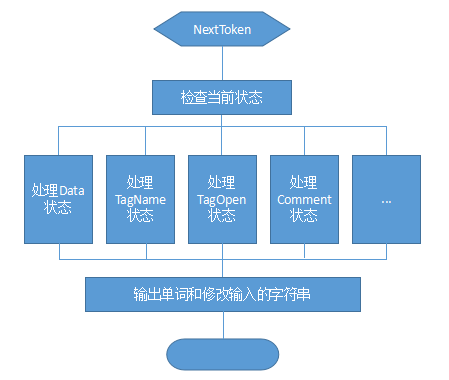
词法分析器HTMLTokenizer的主要工作流程:
节点到DOM树
从节点到构建DOM树,包括为树中的元素节点创建属性节点等工作由HTMLConstructionSite类来完成,DOM树的根节点为HTMLDocument,其他元素的节点都是它的后代,由于HTML文档中的Tag标签是有开始和结束标记的,因此可以使用栈,HTMLConstructionSite类中包含一个“HTMLElementStack”变量,它是一个保存元素节点的栈,其中的元素节点是当前有开始标记当时还没有结束标记的元素节点,如下的一个片段”< body >< div >< img >< /img >< /div >< /body >”,当解释到img元素的开始标记时,栈中的元素是body,div,img当遇到img的结束标记时,img退栈,img是div元素的子女,当遇到div的结束标记时,div退栈,表明div和它的子女以处理完毕,以此类推。DOM结构的基本为Node类,在WebKit中,DOM中的接口Interface对应与C++类,Node类是其他类的基类,下图显示了DOM的主要相关节点类:
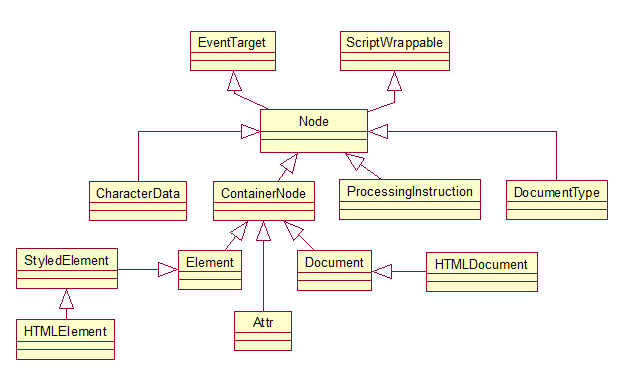
图中的Node类继承自EventTarget类,表明Node类能够接收事件,此外还继承自ScriptWrappable类,这个与JavaScript引擎有关,Node的子类是DOM中定义的同名接口,元素类,文档类和属性类均继承自一个抽象出来的ContainerNode类,表明它们能偶包含其他的节点对象。
DOM事件机制
事件的工作过程
事件在工作过程中使用两个主体,第一个是事件,第二个是事件目标,每个事件都有属性来标记该事件的事件目标,当事件到达事件目标的时候,在这个目标上注册的监听者都会被触发调用,其中监听者的调用顺序是不固定的,EventTarget的接口定义:
interface EventTarget {
void addEventListener(in DOMString type, in EventListener listener, in boolean userCapture);
void removeEventListener(in DOMString type, in EventListener listener, in boolean userCapture);
Boolean dispatchEvent(in Event evt) raises (EventException);
};事件处理主要有事件捕获和事件冒泡两种机制,过程如下:
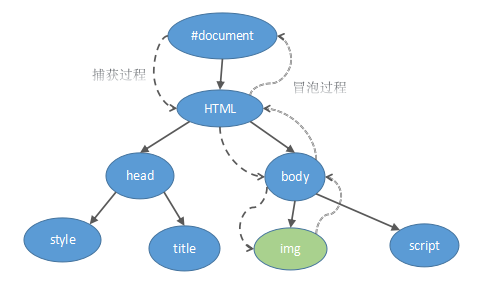
当渲染引擎接收到一个事件的时候,会通过HitTest检查哪个元素是直接的事件目标,以上图“img”为例,假设它是事件的直接目标,这样事件会经过自顶向下和自底向上两个过程,事件的捕获是向下的,事件先到document节点,然后一路到达目标节点,事件可以在这一传递过程中被捕获,只需要在注册监听的时候设置相应的参数即可,EventTarget类中的“addEventListener”的第三个参数就是表示这个含义,默认情况下,其他节点不捕获这样的事件,如果网页注册了这样的监听者,那么监听者的回调函数会被调用,函数可以通过事件的“stopPropagation”函数来阻止事件向下传递。事件的冒泡过程是从下向上的顺序,它的默认行为是不冒泡,但是事件包含一个是否冒泡的属性,当这一属性为真的时候,渲染引擎会将该事件首先传递给事件目标节点的父亲,以此类推,同捕获动作一样,这些监听函数也可以使用“stopPropagation”函数来阻止事件向上传递。
WebKit事件处理机制
DOM事件分为很多种,与用户相关的只是其中的一种UIEvent,其它的包括CustomEvent,MutationEvent等,UIEvent又可以分为很多种,包括但是不限于FocusEvent,MouseEvent,KeyboardEvent,CompositionEvent等。基于WebKit的游览器事件处理过程,首先是做HitTest,查找事件发生出的元素,检测该元素有无监听者,如果网页的相关节点注册了事件的监听者,那么游览器会把事件派发给WebKit内核来处理,同时,游览器也可能需要理解和处理这样的事件,因为有些事件游览器必须响应从而对网页作默认处理,若想禁止游览器做默认处理则可以调用事件的”preventDefault“函数。
影子(Shadow)DOM
影子DOM主要是解决了一个文档中可能需要大量交互的多个DOM树建立和维护各自的功能边界的问题,影子DOM能够使得一些DOM节点在特定范围内可见,而在网页的DOM树中却不可见,但是网页渲染结果中包含了这些节点。下图描述了HTML文档对应的DOM树和”div”元素包含的一个影子DOM子树:
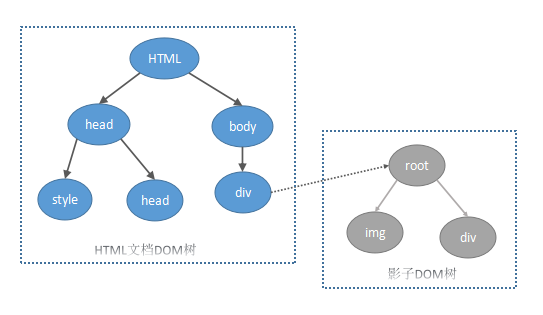
当使用JavaScript代码访问HTML文档的DOM树的时候,通常的接口是不能直接访问到影子DOM树中的节点的,JavaScript只能通过特殊的接口方式。HTML5对视频、音频提供了支持,这些元素有很复杂的控制界面组成,这些界面也是使用HTML元素编写,但是在DOM树中,无法找到相应的节点,这就是采用了影子DOM的思想,影子DOM中,所有事件目标都是包含影子DOM子树的节点对象,事件捕获的逻辑没有发生变化,在影子DOM子树内也会继续传递,当影子DOM子树中的事件向上冒泡的时候,WebKit会同时向整个文档的DOM上传递该事件。















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









