







本萌新记录一下看过的论文,如果理解有误大佬们体谅下QAQ。
摘要:
作者提出一个用于图像分类的、简单、高度模块化的网络结构。该网络是通过重复一个构建块(building block)来构建的,该构建块聚合了一组具有相同拓扑结构的转换。作者的简单设计产生了一个同质的、多分支的体系结构,只需要设置几个超参数。这个策略中引入(exposes)一个新的维度,我们称之为“基数”(转换集的大小),作为深度和宽度维度之外的一个重要因素。在ImageNet-1K的数据集实验表明,即使在持续复杂的限制条件下,增加基数(cardinality)能够提高分类的精确度。此外,在增加容量(capacity)时,增加基数比增加深度或者宽度更加有效。名为ResNeXt的模型在ILSVRC 2016分类任务中获得第二名。且在COCO数据集当中的效果也比ResNet更好。这些代码和模型在网上是开源的。

1、介绍:
视觉识别的研究正经历着从“特征工程”到“网络工程”的转变。与传统的手工设计特征不同,神经网络是从大数据当中学习的特征,在训练过程中,需要尽可能减少人为的干预,并可以转移到各种识别任务当中。然而,目前的工作重心已经转移到了设计更好的网络体系结构来表示学习。
随着超参数(宽度、过滤器尺寸、跨步数等)的不断增加,设计体系结构变得越来越困难,尤其是在有许多层的情况下。VGG网络展示了一个简单而且有效的构建非常深的网络的策略(strategy of constructing very deep networks):堆放相同形状的构建块(stacking buildings of the same shape)。这个策略继承与ResNets。这个简单的规则减少了超参数的自由选择,神经网络引入了一个重要的维度----深度。此外,我们认为这个规则的简单性可能会降低超参数对于某些特定的数据集过拟合的风险。VGGnets和ResNets的鲁棒性通过各种视觉识别任务和自然语言的非视觉任务所证明。
与VGG网络不同,Inception系列模型已经证明,精心设计的拓扑能够以较低的理论复杂度获得令人信服的精度(the family of Inception models have demonstrated that carefully designed topologies are able to achieve compelling accuracy with low theoretical complexity)。Inception模型随着时间的发展,其中一个重要的共同特征是拆分-转换-合并策略。在inception模块中,输入被拆分成几个低纬度嵌入(embeddings)(通过1x1卷积),通过一系列专用的滤波器转换(3x3或者5x5等),并通过级联合并。结果表明,该结构的解空间是在高维嵌入下工作的单个大层(如5x5)解空间的严格子空间(It can be shown that the solution space of this architecture is a strict subspace of the solution space of a single large layer (e.g., 5x5) operating on a high-dimensional embedding)。Inception模块的拆分-转换-合并行为有望接近大而密集层的表示能力,但是计算复杂度低得多。
尽管精度高,但是Inception模型的实现一直伴随着一系列复杂的因素----过滤器的数量和大小是为每个单独转换而定制的,并且模型是逐级定制的。虽然这些组件组合产生了优秀的神经网络结构,但是通常不清楚如何使初始架构去适应新的数据集或是任务,特别是当许多因素或者超参数需要被设定的时候。
本文提出一个简单的体系结构,它采用VGG/ResNets的重复层(repeating layers)策略,同时以一种简单易拓展的方式运用拆分-转换-合并策略。网络中的一个模块做出一系列的转换,每一个转换都嵌入在低纬度上,其输出通过求和聚合。我们希望这个想法可以简单实现——通过聚合的转换都是相同的拓扑结构。这个设计使得我们可以拓展任意数量的转变无需订制化。

有趣的是,在这种简化的情况下,这个模型有两个等价的形式。图三(b)中的重新设置看起来类似于初始的ResNet模块,因为它连接多条路径,但是我们的模块不同于现所有的初始模块,因为我们的所以路径共享先沟通的拓扑结构,因此路径的数量可以很容易地作为要研究的因素隔离。在一个更简洁的表述中,我们的模块由Krizhevsky等人的分组卷积重塑(图三(3)),然而,这是作为工程折中开发的。经过实验证明,即使在保持计算复杂度和模型大小的限制条件下——例如图一(右)被设计为保持图一(左)的FLOPs复杂度和参数数目,我们的聚合转换仍优于原始ResNet模块。特此强调,虽然通过增加容量(更深或者更广)相对容易增加精度,但是保持或者降低复杂度的同时提高精度的方法在文献中并不多见。
我们的方法表明,基数(cardinality??)(变换集的大小)是一个具体的、可测量的维度,除了宽度和深度,它还具有中心重要性。实验表明,增加基数比增加宽度和深度更有效地提高精确度,特别是当深度和宽度开始减低现有模型的精度时。
我们的神经网络名为ResNeXt(表明下一个维度),在ImageNet分类数据集上的性能优于ResNet-101/152、ResNet-200、Inception-v3和Inception-ResNet-v2。特别是,101层的ResNeXt能够获得比ResNet-200更好的精度,且仅有50%的复杂度。此外,ResNeXt展示了比所有Inception模型还要简单的设计。ResNeXt是我们提交ILSRC 2016分类任务的基础,我们获得了第二。本文进一步评估了更大的ImageNet-5K集和COCO目标检测数据集上的ResNeXt,显示出与ResNet相对应的更高精度。
2、相关工作:
多分支卷积网络。Inception模型是成功的多分支体系结构,每个分支都经过仔细定制(customized)。ResNets可以被认为是两个分支网络,其中一个是身份映射(the identity mapping)。深度神经决策森林是具有学习拆分功能的树型多分支网络(Deep neural decision forests are tree-patterned multi-branch networks with learned splitting functions)。
分组卷积。如果不是更早的话,分组卷积的使用可以追溯到AlexNet的论文。Krizhevsky等人将模型分布在两个GPU上。Caffe、Torch和其他库支持分组卷积,主要是为了与AlexNet兼容。据我们所知,很少有证据表明,分组卷积可以用来提高精度。分组卷积有一种特殊的情况是信道卷积,其中组的数目等于信道的数目。信道卷积是是可分离卷积的一部分。
压缩卷积网络。分解(在空间和/或通道级别)是一种广泛采用的技术,用于减少深度卷积网络的冗余并加速/压缩他们。Ioannou等人提出了一种“根”模式的网络来减少计算和根中的分支是通过分组卷积实现的。这些方法已显示出精确的折中方案,具有较低的复杂性和更小的模型尺寸。不同于压缩,我们的方法是一种凭经验显示更强大的表示能力的体系结构。
集合。平均一组独立训练的网络来提高精确度是一种有效的解决方案,在识别比赛中被广泛的采用。将单个ResNet解释为浅层网络的集合,这是ResNet的加性行为(additive behaviors)的结果。我们的方法是利用加法聚合一组转换。但我们认为,这种方法是不精确的,因为要聚合且联合训练的,而不是独立训练。
3、方法:
模板:
我们采用了VGG/ResNets的高度模块化的设计。我们的网络由一堆残余的块(a stack of residual blocks)组成。这些块具有相同的拓扑结构,并且受VGG/ResNets启发的两个简单的规则:(1) 当产生大小相同的空间映射(spatial maps)时,块之间共享相同的超参数(宽度和过滤器的大小 ; (2) 每次当空间映射下采样因子为2时,块的宽度乘以因子2。第二条规则确保所有的块的计算复杂度(浮点运算,乘加运算)基本相同。
由于这两条规则,我们还需要设计一个模板模块(a tmplate module),就可以相应地确定网络中的所有模块。因此,这两条规则大大的缩小了设计空间,并使我们能够集中关注一些重要的因素。由这些规则构造的网络如表1所示。

回溯简单神经元(revisiting simple neurons):
人工神经网络中最简单的神经元执行内积(加权和),这是个全连接层和卷积层完成的基本变换。内积可以认为是聚合转变的一种形式(Inner product can be thought of as a form of aggregating transformation):
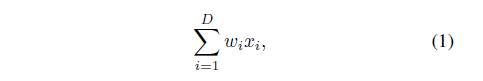
其中X=[]是一个D维的神经元输入向量,并且
是对于第i维的过滤器权重(a filter's weight)。这个操作(通常包括一些非线性输出)被称为“神经元”。如图二。
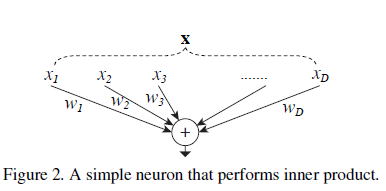
上面的操作可以被认为是拆分、转换和聚合的组合。1、拆分:向量x被分割为低维向量嵌入(embedding),在上图,这是一个一维的子空间xi。2、转换:低纬度表示被转换,在上图,只是按比例缩放:wixi。3、聚合:所有嵌入的转换都是通过得到。
聚合转换(Aggregated Transformations):
根据上述对于简单神经元的分析, 我们认为可以使用一个更通用的函数代替初等变换(wixi),它本身其实也是一个网络。与“网络中的网络”增加了深度的维度相比,我们的“神经元网络”拓展了一个新的维度(expands along a new dimension)。形式上,我们将聚合转换表示为:
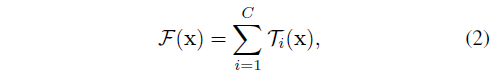
其中Ti(x)可以是任意的函数。类似于一个简单的神经元,Ti应该将x投影到一个(可选的低维)嵌入中,然后对其进行转换。在等式(2)中,C是聚合转换集的大小。我们将C作为基数。在等式(2)中,C的含义与等式(1)中的D相似,但是C不需要等同于D,可以是任意的一个数。虽然宽度维度与简单转换(内积)的数量相关,但是我们认为基数的维度可以控制更复杂的转换的数量。我们将以实验的形式证明,基数是一个重要的维度,并且比宽度和深度维度更加有效。
在本文中,我们设计了一种简单的转换函数:所有的Ti都具有相同的拓扑结构。这拓展了VGG的重复相同形状层的策略(strategy of repeating layers of the same shape),这有助于分离一些因素并拓展到任意数量的转换。我们将单个Ti设置为瓶颈的架构,如图1(右)所示。这个例子,在每个Ti的第一个1x1的层中,产生低维度的嵌入(In this case, the first 11 layer in each Ti produces the lowdimensional embedding.)。
等式(2)中的聚合变换充当残差函数(如图一右):
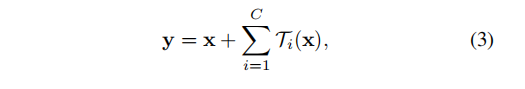
其中y是输出。
与Inception-RseNet的关系。一些张量操纵显示图一(右)中的模块(也在图三(a)中显示)等效于图3(b)。图3(b)看起来与Inception-ResNet块相似,因为它涉及到残差函数中的分支和连接。但是不像所有的Inception或Inception-ResNet模块,我们在多个路径下共享相同的拓扑结构。我们的模块需要最小的精力去设计每一个路径。
与分组卷积的关系。使用分组卷积的符号,上面的模块变得更加简洁。在图三(c)中表示了这种重新表述。所有低维度的嵌入(第一个1X1层)能被一个单独的更宽的层所代替(如图三(c)中的1x1, 128-d)。拆分基本上是由分组卷积层在其输入层分组时完成的( Splitting is essentially done by the grouped convolutional layer when it divides its input channels into groups.)。图三(c)中的分组卷积层执行32组卷积,其输入和输出信道是四维的。分组卷积层将他们连接起来作为输出层。图三(c)中的块看起来像图一(左)的原始瓶颈残余块,除了图三(c)更宽且更稀疏(The block in Fig. 3(c) looks like the original bottleneck residual block in Fig. 1(left), except that Fig. 3(c) is a wider but sparsely connected module.)。
我们注意到,只有当块的深度≥3时,重新格式化才产生非平凡拓扑。如果块的深度为2(例如,[14]中的基本块),则重新格式化将导致一个非常宽、密集的模块(We note that the reformulations produce nontrivial topologies only when the block has depth ≥3. If the block has depth = 2 (e.g., the basic block in [14]), the reformulations lead to trivially a wide, dense module.)。
模型容量:
我们在下一节的实验表明,我们的模型在相同的模型复杂度和参数个数时,提高了精度。这不仅在实际中很有趣,而且更重要的是,参数的复杂度和个数代表着模型的固有容量(inherent capacity),因此经常被作为深度网络的基本性质来研究。当我们评估不同的基数C时同时保持相同的复杂度,这样我们希望最小化其他超参数的修改。我们选择调整瓶颈的宽度(如图一(右)中的4-d),因为它能从块的输入和输出中分离出来。这种策略不会改变其他的超参数(块的深度或者输入输出的宽度),所以有助于我们关注基数的影响。
在图一(左),原始的ResNet瓶颈块中有256x64+3x3x64x64+64x256≈70k参数和proportional FLOPs(在相同大小的特征映射上)。对于瓶颈宽度d,我们图一(右)中的模板具有:

参数和proportional FLOPs。当C=32,d=4,等式4≈70k。表2表示基数C和瓶颈宽度d之间的关系。
因为我们采用3.1中的两个规则,在上诉近似相等在ResNet瓶颈块和我们的ResNet之间在所有阶段都有效(除了特征映射大小改变的子采样层)。表一比较了原始ResNet-50和我们TesNeXt-50的容量相同。我们注意到复杂度只能近似地保持,但是复杂度差别很小不会影响我们的结果。
4、实现细节:
在ImageNet数据集里,使用由[11]实现的[38]的比例和纵横比增大,从调整大小的图像中随机裁剪输入图像224x224。快捷键是标识连接(the shortcuts are identity connections)处理那些增加维度的投影。conv3、conv4,conv5的下采样是按照[11]中的建议,在每个阶段的第一个块的3x3层中通过步长为2的卷积得到的。我们使用SGD,8GPU上的最小批处理大小为256(每个GPU32个)。权重下降是0.0001且动量为0.9。学习率从0.1开始,并用[11]中的工程计划将其除以10三次。采用[13]的权重初始化。在所有的消耗(ablation)比较中,我们估计来自图片较短边为256的单个224x224中心裁剪的误差。
我们的模型以图三(c)的形式实现。我们在图三(c)中的卷积之后执行批处理规范化(BN)[17]。ReLU在每个BN(批处理)之后执行,除了添加到快捷键之后执行ReLU的输出块(expect for the output of the block where ReLU is performed after the adding to the shortcut),如[14]。
我们注意到,当BN和ReLU如上文所提到那样处理时,图三的三种形式是严格相等的。我们训练三种形式并且得到了相同的结果。所以我们选择图三(c)去实现,因为它比其他两种更简洁和更快。
未完待续…















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









