







问题简介:
后缀树作为一种数据结构,一个具有m个字符的字符串s的后缀树T,包含一个根节点的有向树,该树恰好带有m+1个叶子,分别有从0到m的标号。每一个内部节点,除了根节点以外,都至少有两个子节点,而且每条边都用S的一个子串来标识。出自同一节点的任意两条边的标识不会以相同的字符开始。 后缀树的关键特征是:对于任何叶子i,从根节点到该叶子所经历的边的所有标识串联起来后恰好可以拼出S的从i位置开始的后缀,即S[i,…,m]。
背景介绍
后缀树(后缀Trie)最早由Weiner在1973年引⼊。McCreight在1976年⼤幅简化了后缀树的构造算法。他的⽅法从右向左构造后缀树,由于是从末端开始构造,因此限制为离线算法。1995年,Ukkonen给出了第⼀个从左向右的on-line构造算法。
简而言之,我们在构建后缀树时自然就要首先用到字符串的后缀。首先说明字符串的后缀,比如单词heart,我们就有后缀集合suffix{heart, eart, art, rt, t , 空串}在我们构建后缀树时我们就需要用到这些后缀帮助我们创建一个被压缩过的Trie树。
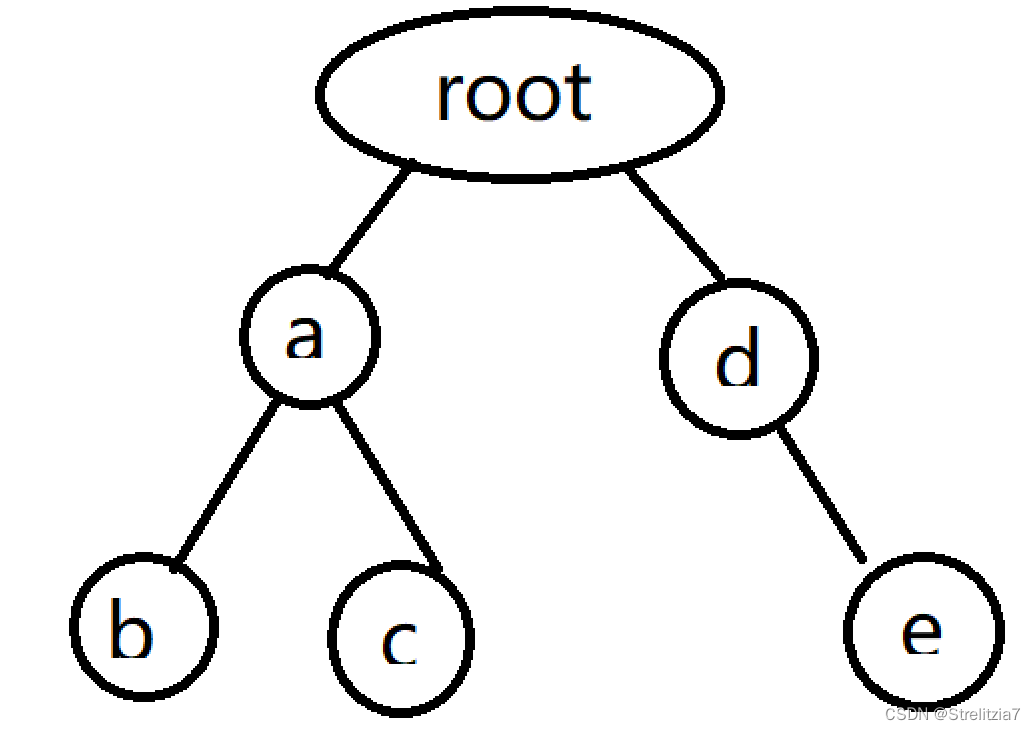
比如这一棵Trie树,在我们对其进行压缩后会变成如下形式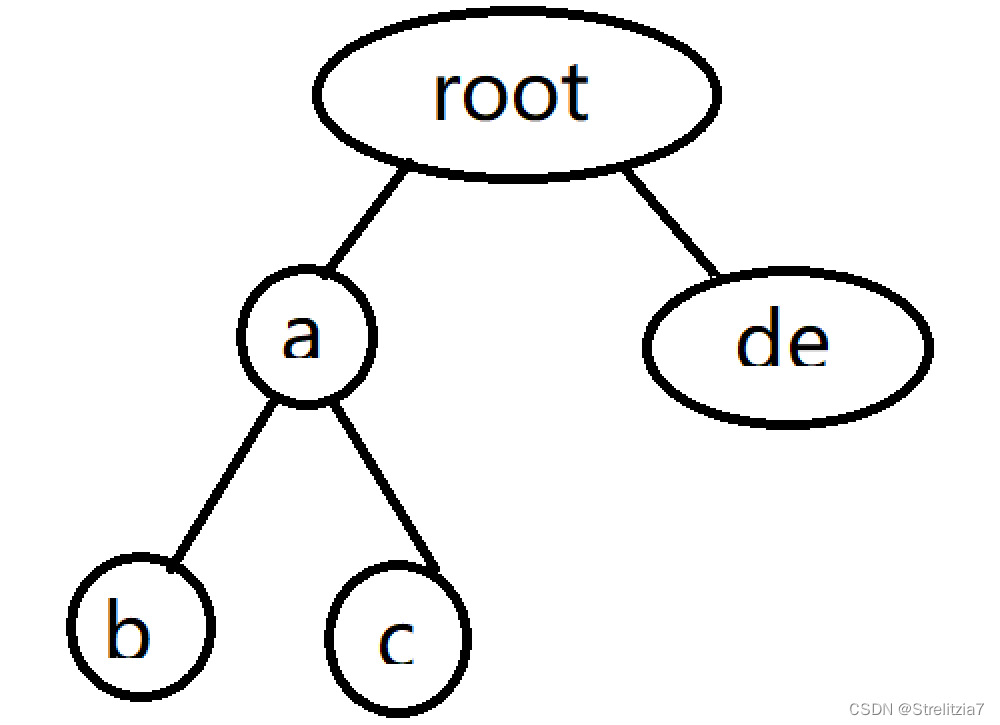
我们可以发现,我们的Trie树在一个节点仅仅存放一个字符的情况是有些浪费时间与空间的,那么我们可以将单个子节点的边压缩到一起,我们就会得到一颗压缩字典树。
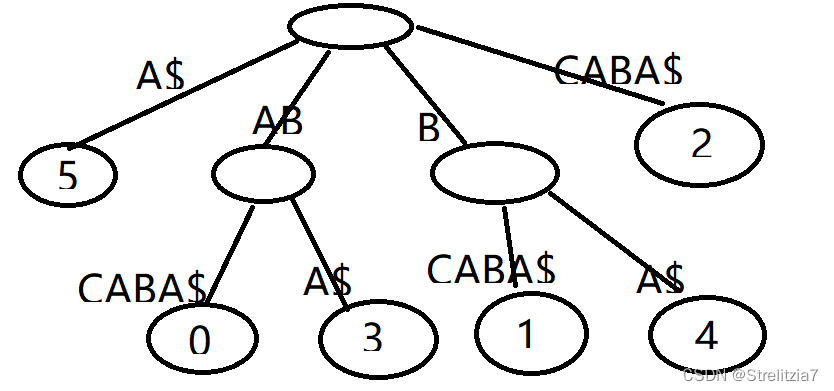
而后缀树,就是包含一则字符串所有后缀的压缩Trie。比如字符串‘ABCABA’把上面的后缀加入Trie后,我们得到下面的结构:
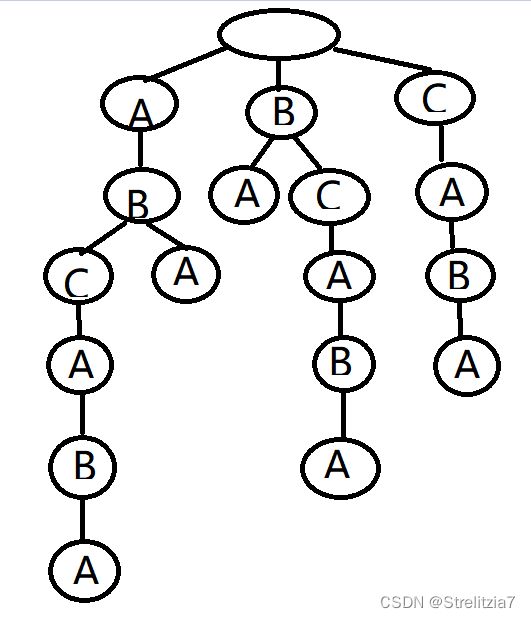
但是我们在构建压缩Trie树时,我们会发现一些后缀消失了,比如A。因为他作为某个字符串的前缀,因而在构建时被吞并,那么我们倾向于在构建时,规定每项的后缀不能是其他后缀的前缀。而解决这样一个问题也比较简单,我们直接在初始时我们需要处理的字串的末尾加上一个空字串就可以了。比如我们在预处时我们在尾端加上&,即ABCABA&
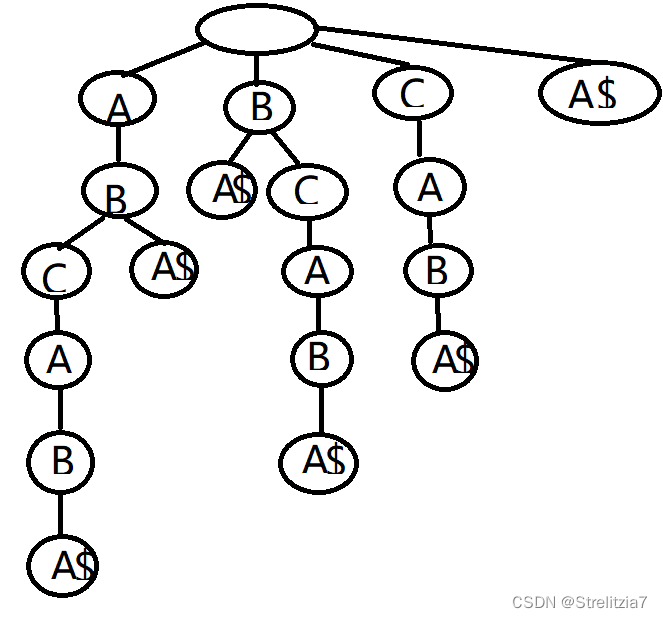
我们再将其进行压缩,就可以得到以下树:
而我们的 后缀树同样有很多用途,比如:
1.查找字符串是否在原字符串中。
我们就可以根据有原字符串直接构造后缀树,然后在后缀树中进行搜索。
2.字符串中最长回文子串。
我们可以根据原字符串 + ‘$’来构建后缀树,找到最深的非叶子节点。
3.指定某个字符串在原字符串中的重复次数。
我们可以根据原字符串 + ‘$’来构建后缀树,找到指定字符串下的叶节点数目。
4.查找两个字符串最长公共子串。
例两个字符串分别为S1与S2,将S1'$'与S2'#'压入后缀树中,找到最深的非叶子节点。
5.生物学碱基配对原理。
后缀树的构建:
for i 从 1 到 m: //m为字符串长度
逐步构造隐含后缀树
for j 从 1 到 i+1:
在已经构建好的后缀树中找到从root结点出发
标记位S[j~i]的序列,如果需要的话将
S[i+1]加入到这条路径后面
end
在这里我们简单介绍后缀树的构造函数:
struct SuffixNode
{
public:
SuffixNode* Child; //左孩子,子节点
// iiflag=-3,不是叶子,子树中存在叶子节点含有#;iiflag=-2,不是叶子,子树中存在叶子节点含有$#;
SuffixNode* Brother; //右兄弟(右孩子)
SuffixNode* suffixNode;//后缀链接
string str;//对应字符串
int iiflag;//叶子节点:对应字符串开始位置
public:
void init(string str)//用于初始化的方法
{
this->str=str;
Child = 0;
Brother=0;
iiflag=-1;
// tmpp=0;
}
void SuffixTree::create(string str)
{//构造后缀树
int index = 0;
treeword=str;
while (index < str.length()) {
int currentIndex = index++;// 保存当前位置
char w =str[currentIndex];// 得到当前后缀字符
bool f=find(w);
if (f) {// 查找是否存在保存有当前后缀字符的节点
remainder++;
continue;
}else if(!f&&!activenode->index&&remainder != 0){
//找不到&&index==0,且需要插入后缀
SuffixNode* child=activenode->point->Child;
SuffixNode* splitNode=activenode->point;
SuffixNode *newNode=new SuffixNode();//即将插入的节点
string s=str.substr(currentIndex,str.length()-currentIndex);
newNode->init(s);
newNode->iiflag=iflag++;
while(child->Brother!=NULL){
child=child->Brother;
}
child->Brother=newNode;
if (NULL== activenode->point->suffixNode) {// 无后缀的节点
activenode->point = root;
} else {
activenode->point = activenode->point->suffixNode;
}
activenode->index=NULL;
activenode->length=0;
Split(str, currentIndex, splitNode);
continue;
}
//如果reminder==0表示之前在该字符之前未剩余有其他待插入的后缀字符,直接插入该后缀字符
if (remainder == 0) {
SuffixNode *node = new SuffixNode();
string tmp=str.substr(currentIndex,str.length()-currentIndex);
string tmp=str.substr(currenctIndex,str.length()-currentIndex);
node->init(tmp);
node->iiflag=iflag++;
SuffixNode* child = activenode->point->Child;
if (NULL== child) {
activenode->point->Child = node;
} else {
while (NULL!= child->Brother) {
child = child->Brother;
}
child->Brother = node;
}
} else {
// 如果reminder>0,则说明该字符之前存在剩余字符,分割后插入新的后缀字符
SuffixNode *splitNode = activenode->index;
SuffixNode *node = new SuffixNode();
string tmp=splitNode->str.substr(activenode->length,splitNode->str.length()-activenode->length);
node->init(tmp);
node->iiflag=splitNode->iiflag;
splitNode->iiflag=-1;
node->Child = splitNode->Child;
node->suffixNode = splitNode->suffixNode;//后缀节点转移
splitNode->Child = node;
splitNode->suffixNode = NULL;
// 创建新插入的节点,放到当前节点的子节点
SuffixNode *newNode = new SuffixNode();// 插入新的后缀
string tmp2=str.substr(currentIndex,str.length()-currentIndex);
newNode->init(tmp2);
newNode->iiflag=iflag++;
splitNode->Child->Brother = newNode;
splitNode->str = splitNode->str.substr(0,activenode->length);
if (root == activenode->point) {// 活动节点是根节点的情况
// activenode->point == root
//activenode->index root,a,2->root,b,1
} else if (NULL== activenode->point->suffixNode) {
activenode->point = root;
} else {
activenode->point = activenode->point->suffixNode;
}
// 活动边和长度重置
activenode->index =NULL;
activenode->length = 0;
// 递归处理
Split(str, currentIndex, splitNode);
}
}
}
};以上就是关于后缀树的基本介绍与构造函数的实现















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









