







HsahMap与HashTable的区别
HashMap的底层方法中没有加锁,是线程不安全的,但是效率比价高;
HashTable的底层方法中加了锁,是线程安全的,但是效率比较低,并且最终会变成单线程;
在高并发的情况下应该使用ConcurrentHashMap
HashTable,HashMap是否可以存放key=null,如果key,那么存放在什么位置?
HashTable中key和value都不允许为空;
HashMap可以允许key为null,存放在数组中的index=0的位置;
如果发生了hash碰撞,则会形成一条链表追加在后面,并且这样的key只有一个,可以有一个或者多个key对应的值为null,当get方法返回null的时候,即可以表示HashMap没有该键,也可以表示该键对应的值为null,因此在HashMap中不能使用get方法来判断HashMap中是否存在某个值,而应该使用ContainsKey方法来判断;
Map接口的继承体系
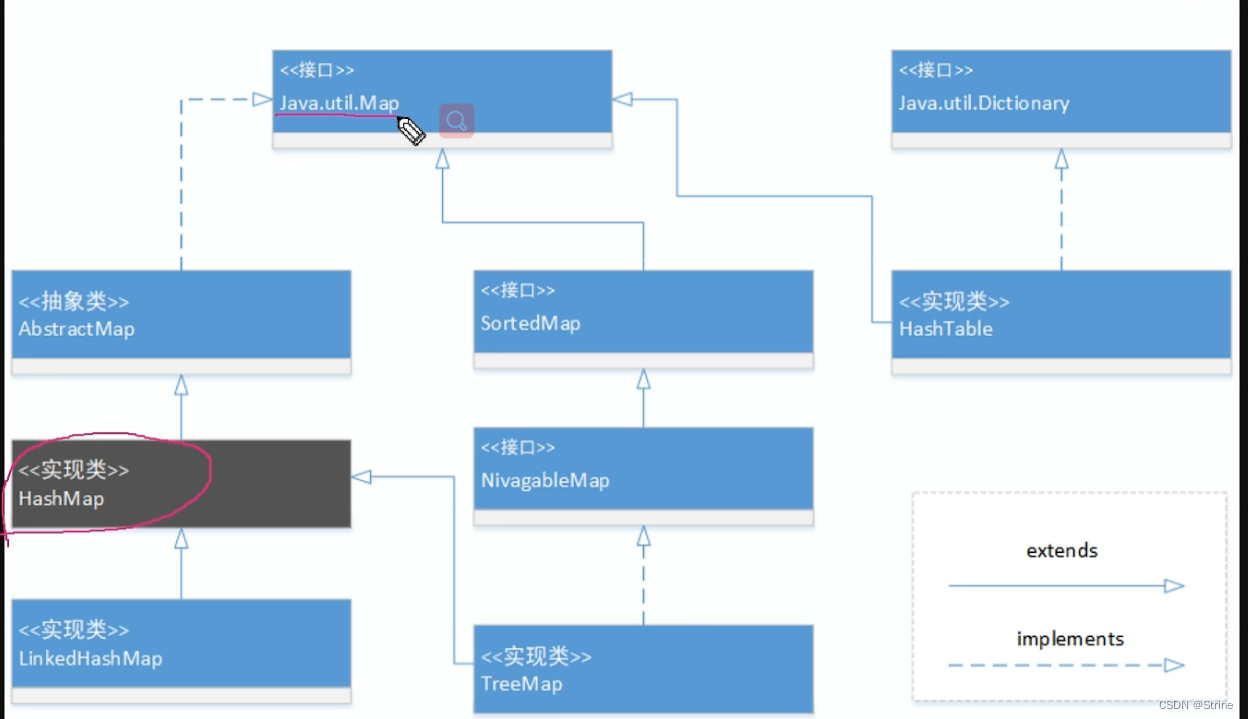
1.SortedMap接口继承了Map接口,NavigableMap接口继承了SortedMap,而TreeMap类不仅实现了该接口,还继承了AbstractMap;
2.HashTable类是Map接口的实现类,并且继承了Dictionary类;
3.AbstractMap是一个抽象类,也实现了Map接口,HashMap实现了该接口,而LinkedHashMap继承了HashMap的同时实现了Map接口;
HashMap集合底层实现方式
1.基于ArrayList集合实现;
2.基于数组+链表实现;
3.基于数组+链表+红黑树实现(后面再讲);
我们现在来手写一下前两种实现方式;
基于ArrayList集合实现HashMap
HashMap的底层实现了Map接口,其中我们可以发现键值对封装在Map接口里面的Entry对象中;
因此实现起来也比较简单,我们自定义一个Entry对象,将Key和Value放在里面,然后再将整个Entry对象存入ArrayList中,当我们需要取数据的时候就循环遍历整个ArrayList,判断Entry对象的key与我们传过去的key是否相同,相同则返回value值;
public class StrineArrayListHashMap<K,V> {
private ArrayList<Entry> entries = new ArrayList<Entry>();
/**
* 封装键值对
* */
public class Entry<K,V>{
private K k;
private V v;
public Entry(K k,V v){
this.k=k;
this.v=v;
}
}
public void put(K k ,V v){
Entry entry = new Entry(k,v);
entries.add(entry);
}
public V get(K k){
for (Entry entry : entries) {
if (entry.k.equals(k)){
return (V) entry.v;
}
}
return null;
}
}存在的问题:
如果这个ArrayList很长,那么循环遍历的次数就会变多,时间复杂度为O(n),效率很低,因此是不推荐的;
因此我们考虑使用其他数据结构来提高它的查询效率:
HashCode+数组+链表
我们使用数组的方式来实现,我们在存储的时候,先计算键的hashCode值,然后再对数组长度取余来获取它的下标值,然后存到Entry数组中去:
但是这样又会存在一个问题:Hash冲突,例如字符串“a”与数字97计算得到的hashCode值是相同的,但是内容是不相同的,那么就会导致如果先添加了前者,那么后面hashCode发生冲突的话就会把前者覆盖掉,因此我们加入链表来解决这个问题;
这也就是JDK1.7版本的底层数据结构
public class StrineExtHashMap<K,V> {
private Entry<K,V>[]entries=new Entry[1000];
public class Entry<K,V>{
private K k;
private V v;
private Entry<K,V> next;
public Entry(K k,V v){
this.k=k;
this.v=v;
}
}
public void put(K k,V v){
int index = k.hashCode() % entries.length;
if (entries[index]!=null){
entries[index].next=new Entry<>(k, v);
}else {
entries[index] = new Entry<>(k, v);
}
}
public V get(K k){
int index = k.hashCode()% entries.length;
for (Entry entry = entries[index];entry!=null;entry=entry.next){
if (entry.k.equals(k)){
return (V) entry.v;
}
}
return null;
}链表的增删改效率非常高,查询效率非常低,因为也需要挨个节点挨个节点的去遍历,时间复杂度为O(n);
那么当发生了Hash碰撞,也就是说不同的key值计算出来的hashCode是相同的,那么就会形成链表追加到后面,也就解决了这个问题;
但是这样也会存在问题,因为链表的查询效率很低,那么如果index发生冲突概率过多,那么这条链表就特别长,查询次数很多,效率很低;
从这里也可以看发现,HashMap存放Key是无序的,因为它是散列的,我们在计算下标的时候得到的结果绝对不可能是递增的,源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
n = (tab = resize()).length;
tab[i = (n - 1) & hash] // 这个i就是计算得到的索引值;因此在JDK1.8以后就引入了红黑树来解决这个问题(后面细讲)
大概就是:
当链表长度超过阈值8且所有元素数量达到64的时候,该链表就转换为红黑树存储
















 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











