






1.什么是HashMap?
简介
HashMap是我们⾮常常⽤的数据结构,由数组和链表组合构成的数据结构。
HashMap是用哈希表(直接一点可以说数组加单链表)+红黑树实现的map类
它是一个键值对的组合,每一个地方都存了Key-Value这样的实例,采用拉链法实现的,在Java7叫Entry在Java8中叫Node。
特点
没有重复的key,key必须是唯一的,HashMap是无序的。而且顺序会不定时改变。每个Key只能对应一个Value。
底层实现是链表数组,JDK8后又加了红黑树
key,value都可以是任何引用类型(包括null)的数据(只能是引用类型)
HashMap查询效率高在获取指定元素前需要把key经过哈希运算,得到目标元素在哈希表中的位置,然后再进行少量比较即可得到元素
允许空键和空值(但空键只有一个,且放在第一位,知道就行)
HashMap不同步
取值操作都是通过Key来取。如果出现两个key,计算机将不知道取哪个对应的值。如果动手实践强的小伙伴会发现,可以传入两个相同的key值,那是因为源码中,传入相同的键值对,将作为覆盖处理,所以HashMap不会出现相同的key。
结构和底层原理
因为它本身所在的位置都为null,所以在put插入的时候会根据key的hash去计算一个index值。
例如:我在put(“欢少”,666),我放入了欢少这个元素,这个时候我们会通过哈希函数计算出插入的位置也就是index。
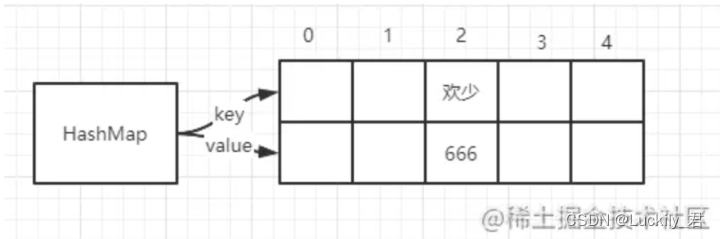
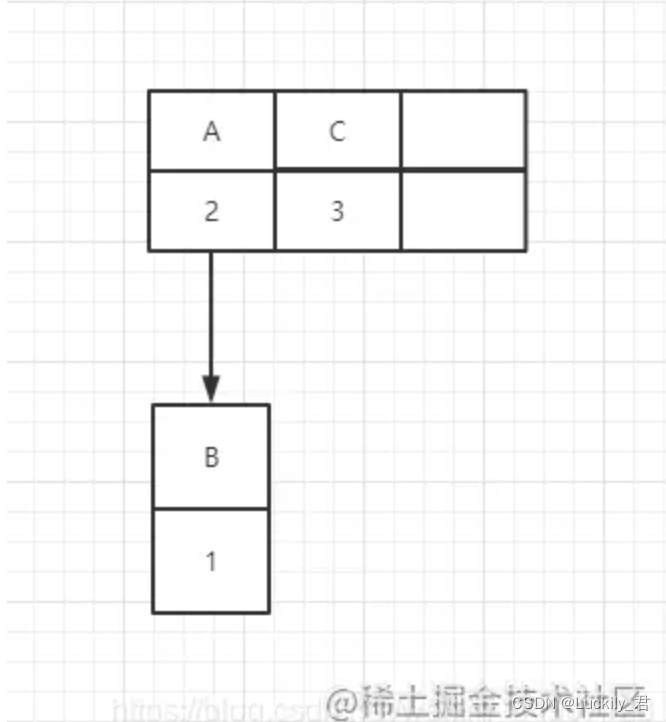
这个图是验证如果放入同一个Key,源码中会自动覆盖的以及验证HashMap支持空
2.HashMap与ArrayList哪个取值效率性能更高?(虽然没可比性,科普一下)他们俩如何选型?
效率问题
HashMap效率大于ArrayList!HashMap取值直接get(key),没有的话就返回null。因为ArrayList底层是由数组实现的list.get(index)。当list去按索引查询的时候,会先去数组里比对索引是否越界,然后再去查询,耗时要比HashMap慢一点。
选型问题
ArrayList查询效率高,新增删除效率慢,线程不安全
Vector线程是安全的,基于数组,大小可变,可以同步访问,效率低
HashMap存在的意义就是实现一种快速的查找并且插入、删除性能都不错的一种K/V(key/value)数据结构。
3.链表是什么?HashMap为啥还需要链表?又是什么样子?
链表是什么
链表是一种根据元素节点逻辑关系排列起来的一种数据结构。
利用链表可以保存多个数据,这一点类似于数组的概念,但是数组本身有一个缺点——数组的长度固定,不可改变。
在长度固定的情况下首选的肯定是数组,但是在现实的开发之中往往要保存的内容长度是不确定的,那么此时就可以利用链表这样的结构来代替数组的使用
为啥需要链表
放入元素的时候会有一个hash函数求当前要放入key的哈希值
硬核知识=>放入第一个元素与第二个元素有可能哈希值相同,处理之后得到下标也是相同的,系统不知道如何放,但是得到的哈希值的下标又没有任何毛病,只有在第一个值的下面延申出一个节点。如下图
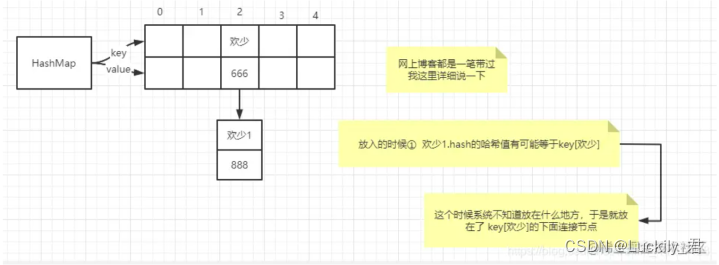
链表又是什么样子
每⼀个节点都会保存⾃身的hash、key、value、以及下个节点,
如上图结构下图代码
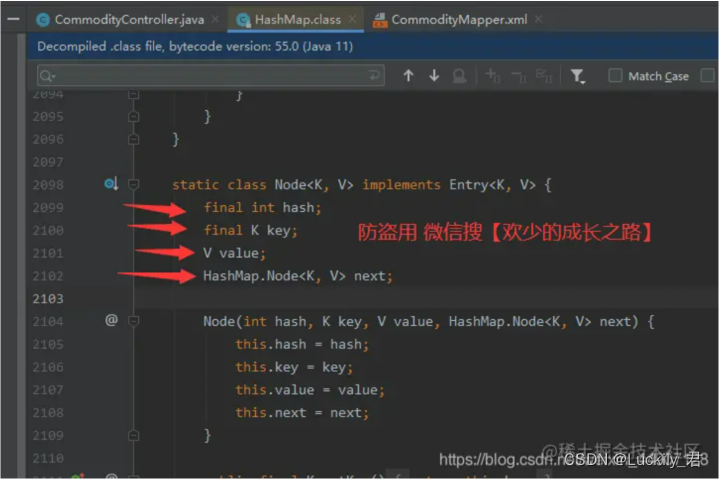
4.新的Entry节点在插入的时候是怎么插入的?
Java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上⾯的例⼦⼀样。
因为写这个代码的作者认为后来的值被查找的可能性更⼤⼀点,提升查找的效率。但是,在java8之后,都是所⽤尾部插⼊了
5.为啥在Java8之后改为尾部插入了?
我先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize呢?(容量负载系数=>20.75=1)所以第二个要resize了
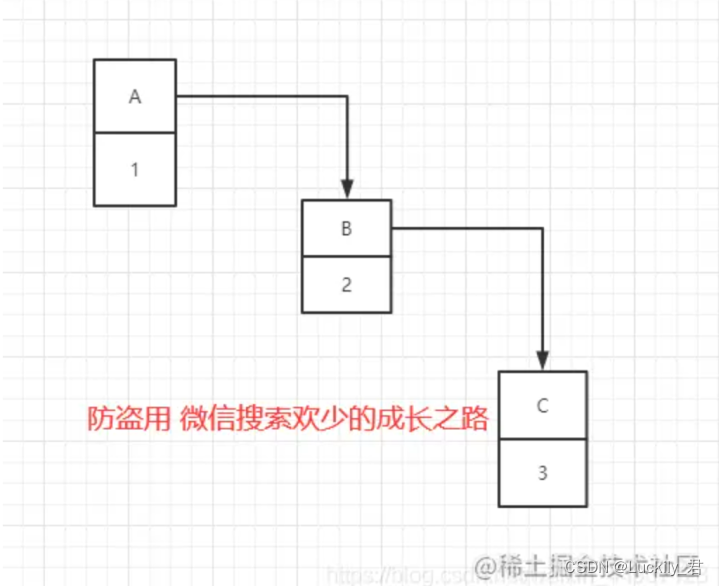
现在我们要在容量为2的容器里面用不同的线程插入A,B,C,假如我们在resize之前打个断点,那意味着数据都插入了但是还没resize那扩容前可能是这样的。A=>B=>C。A的下一个指针是指向B的
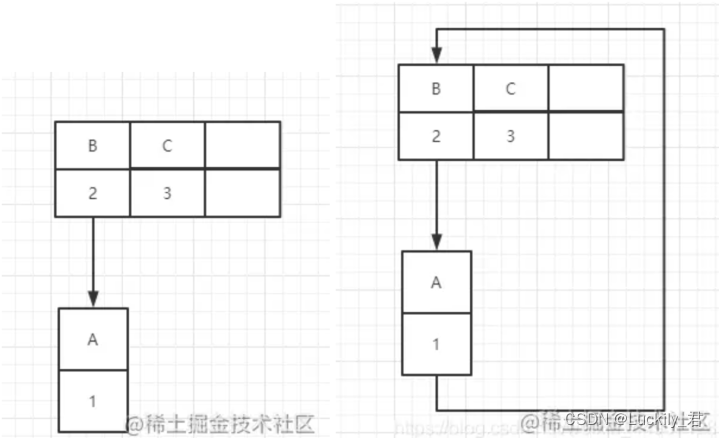
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。如图,B的下一个指针指向了A
这个时候线程还没有结束有可能线程都执行结束的时候B指向A的同时,A也指向了B也就是出现环形链表。如果这个时候取值,那就尴尬了。。。。infiniteloop
下一个需要调整大小的大小值(容量负载系数)Thenextsizevalueatwhichtoresize(capacityloadfactor)
6.HashMap的扩容机制是什么?是怎么扩容的?
怎么扩容的:
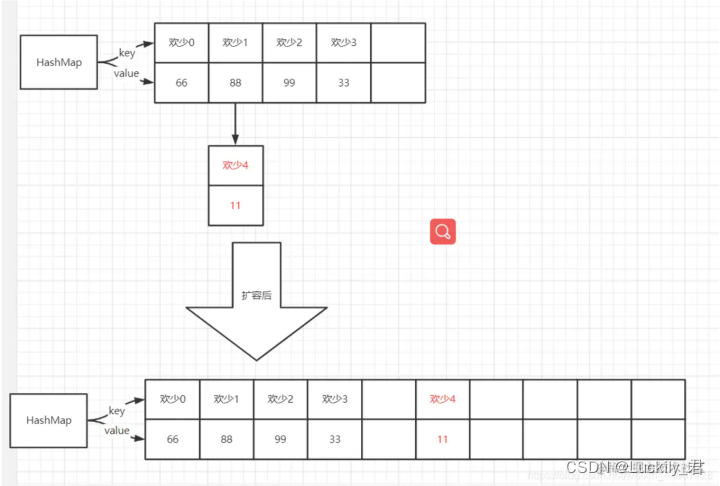
每次扩容后,都会重新哈希,也就是key通过哈希函数计算后会得出与之前不同的哈希值,这就导致哈希表里的元素是没有顺序,会随时变化的,这是因为哈希函数与桶数组容量有关,每次结点到了临界值后,就会自动扩容,扩容后桶数组容量都会乘二,而key不变,那么哈希值一定会变
分为两步第一步扩容:创建新的Entry空数组,长度是原数组的2倍。ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
7.扩容的时候为什么要重新Hash呢,直接复制过去不好吗?
因为⻓度扩⼤以后,Hash的规则也随之改变。
比如原来的长度是8,位运算之后的值是2。新的长度是16的时候,位运算的值明显就不一样了。上图用图说话
Hash的公式—>index=HashCode(Key)&(Length-1)
8.8之前用头插法,8之后改成尾插是怎么样的呢?
1.7是数组+链表
1.8是数组+链表+红黑树
因为Java8有红黑树的部分,代码中已经多了很多ifelse逻辑判断,红黑树的引用,解决了时间复杂度的问题。巧妙的将原本的O(n)的时间复杂度降低到了O(logn)。
使用头插会改变链表原来的位置顺序,但是如果使用尾插的话,只会插在链表的下一个节点的位置,就算在扩容的时候也会保持链表元素的原本顺序,就不会出现链表成环的问题了。也就是说原本是A=>B扩容后还是A=>B。
Java7在多线程操作HashMap的时候可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。6.Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系
9.Java8可以把HashMap⽤在多线程中吗?详细说一下
通过源码我们可以知道,put/get方法都没有加同步锁,多线程情况最容易出现的就是无法保证上一秒put的值和下一秒get的值还是原值,有可能在这一秒钟会有新线程重新操作一遍这个数据,所以线程是无法保证数据的准确性的。所以不可以把HashMap放入多线程。
10.HashMap的默认初始化⻓度是多少?为什么是这个数?为啥用这个不用别的呢?
初始值长度 1<<4也就是16
为啥用位运算呢?直接写16不好吗?
编辑器会提醒我们最好赋初值,而且最好是2的幂,这样为了位运算方便,位运算比算数计算的效率高很多,之所以选择16是为了服务将key映射到index的算法中;
上面讲到了put的时候会hash一些key的值,但是我们怎么尽最大可能得到一个均匀分布的hash呢?我们通过的是key的hashcode值去做位运算。
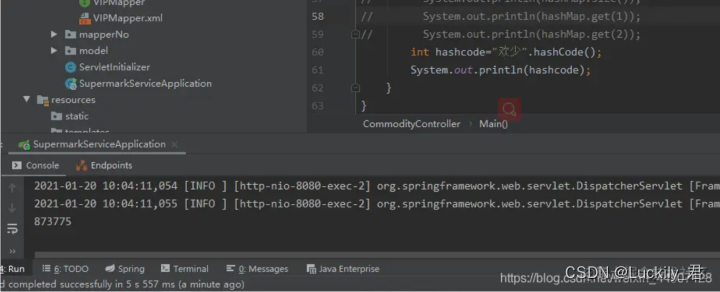
例如:
key为上面的”欢少“十进制为873775二进制为11010101010100101111
HashMap下标的计算方式是index=HashCode(Key)&(Length-1)
代入得 11010101010100101111&1111 十进制就是15
之所以用位运算,效果与取模一样,提高性能!
为啥用16不用别的?
首先默认容量一定要是2的次幂。所以只有是2,4,8,16,32
根据博主推断,因为在使⽤不是2的幂的数字的时候,Length-1的值是所有⼆进制位全为1,这种情况下,index的结果。等同于HashCode后⼏位的值。只要输⼊的HashCode本身分布均匀,Hash算法的结果就是均匀的。这是为了实现均匀分布。
11.为啥我们重写equals⽅法的时候需要重写hashCode⽅法呢?能⽤HashMap给我举个例⼦么?
为啥需要重写equals和hashcode方法
因为Java所有方法都继承了object类,object里有两个方法就是equals,hashCode。这两个方法都是判断两个对象是否相同相等的。
在未重写的equals方法,我们是继承了object类里的equals的,那里的equals是比较两个对象的内存地址,显然我们new了2个对象内存地址肯定不一样。
值对象=>比较的是两个对象的值。引用对象=>比较的是两个对象的地址。
下面说一下不重写hashcode的后果吧,因为那么多白话文不容易懂,如果抛出一个问题大家就更容易懂了
大家应该还记得上面取数据的流程吧第一步是根据key的hashcode去寻找的index值,如果是多个值的情况那不就是形成了index链表了嘛,也就是说一个链表上有欢少1,欢少2的index都是2。
到了这一步之后已经区分了index下标,但是区分不了找的是欢少1还是欢少2。如果我们对equals⽅法进⾏了重写,建议⼀定要对hashCode⽅法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。不然⼀个链表的对象,你哪⾥知道你要找的是哪个,到时候发现hashCode都⼀样,这不是完犊⼦嘛!
12.HashMap线程是不安全的,那怎么处理HashMap在线程安全的场景呢?
我们⼀般都会使⽤HashTable或者ConcurrentHashMap,但是因为前者的并发度的原因基本上没啥使⽤场景了,所以存在线程不安全的场景我们都使⽤的是ConcurrentHashMap。
HashTable我看过他的源码,很简单粗暴,直接在⽅法上锁,并发度很低,最多同时允许⼀个线程访问。
ConcurrentHashMap就好很多了,1.7和1.8有较⼤的不同,不过并发度都⽐前者好太多了。
13.HashMap的存取原理?
A.存入Put原理
//添加指定的键值对到Map中,如果已经存在,就替换publicVput(Kkey,Vvalue){returnthis.putVal(hash(key),key,value,false,true);}//计算对应的位置staticfinalinthash(Objectkey){inth;returnkey==null?0:(h=key.hashCode)^h>>>16;}publicresize:扩容publicputTreeVal:树形节点的插入publictreeifyBin:树形化容器finalVputVal
1、先调用hash方法计算哈希值
2、哈希值&table.length得出数组的下标
3、调用putVal方法中根据哈希值进行相关操作
4、如果当前哈希表内容为空,新建一个哈希表
5、如果要插入的桶中没有元素,新建个节点并放进去
6、否则从桶中第一个元素开始查找哈希值对应位置
7、如果桶中第一个元素的哈希值和要添加的一样,替换,结束查找
8、如果第一个元素不一样,而且当前采用的还是JDK8以后的树形节点,调用putTreeVal进行插入
9、否则还是从传统的链表数组中查找、替换,结束查找
10、当这个桶内链表个数大于等于8,就要调用treeifyBin方法进行树形化
11、检查是否需要扩容
B.取出Get原理
publicVget(Objectkey)//如果HashMap中包含一个键值对k-v满足以上代码,就返回值v,否则返回null;(key == null ? k == null : key.equals(k))
1、先计算哈希值
2、再用(n-1)&hash计算出桶的位置
3、在桶里的链表进行遍历查找
14.Java7和Java8的区别?
StreamApi–jdk1.8增加了stream特性,主要是基于fork-join框架构建,而且你可以通过parallel与sequential在并行流与顺序流之间进行切换
Hashmap性能优化:
1.最重要的一点是底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构;
2.插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插
3.jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,使元素分布更均匀
4.扩容策略:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容
15.有什么线程安全的类代替么?
ConcurrentHashMap,这个类的具体讲解由下篇文章发表个人对ConcurrentHashMap的理解与用法。
16.HashMap的主要参数都有哪些?负载因⼦是多少?为什是这么多?
负载因子 负载因子默认值为0.75
为什么那么多?提高空间利用率和减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小
通常负载因子在时间河空间成本上寻求一种折衷,过高,虽然减少了空间开销提高了空间利用率,但同时增加了查询成本
过低又导致减少查询时间成本,但是空间利用率低,同时提高了rehash操作的次数。所以0.75是一个折衷选择
下面太细的细节就不深挖了,涉及到数据结构以及算法知识了,我会专门讲解一些算法以及数据结构的知识。
主要参数:
loadFactor:负载因子,默认值为0.75
thresshold:所能容纳的键值对的临界值
thresshold:计算公式为数组长度*负载因子
size:HashMap中实际存在的键值对数量
modCount:字段用来记录HashMap内部结构发生变化的次数
HashMap默认容量INITIAL_CAPACITY为16
17.HashMap常用方法
(1)插入键值对数据publicVput(Kkey,Vvalue)
(2)根据键值获取键值对值数据publicVget(Objectkey)
(3)获取Map中键值对的个数publicintsize
(4)判断Map集合中是否包含键为key的键值对publicbooleancontainsKey(Objectkey)
(5)判断Map集合中是否包含值为value的键值对booleancontainsValue(Objectvalue)
(6)判断Map集合中是否没有任何键值对publicbooleanisEmpty
(7)清空Map集合中所有的键值对publicvoidclear
(8)根据键值删除Map中键值对publicVremove(Objectkey)键值对数据遍历
(9)将Map中所有的键装到Set集合中返回//publicSetkeySet;Setset=map.keySet
(10)返回集合中所有的value的值的集合//publicCollectionvalues;Collectionc=map.values
(11)将每个键值对封装到一个个Entry对象中,再把所有Entry的对象封装到Set集合中返回
//publicSet>entrtSet;Set>entrys=map.entrySet















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









