







什么是循环依赖?
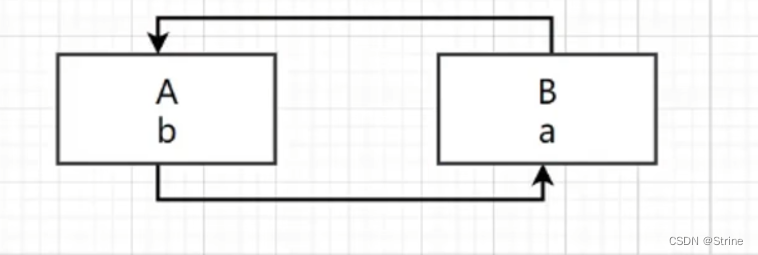
在A对象里面有一个属性b,这个属性b是B对象;
那么在进行创建A对象之后需要对其属性b进行赋值,这个时候需要判断容器里面有没有B对象,如果有B对象就直接赋值就可以了;
但是没有B对象,那么就会去创建B对象然后对属性a进行赋值,这样的话就会出现上图这样一个闭环的情况,这就是我们所说的循环依赖问题;
图解
图中框起来的地方就是一个闭环,也就是出现了循环依赖问题;
Spring是如何解决循环依赖的?
流程分析
1.想要解开这种闭环问题,那么就让其中一个环节断开即可,而一般遇到这种问题我们首要考虑的就是解开最后一个连线;
2.也就是说我们现在只要存在A对象,并且赋值给a属性,那么就能解开这个闭环;
那我们现在来思考,当走到最后一条连线的时候,存不存在A对象呢?
对象按照状态分类可以分为:成品对象(完成实例化和初始化)和半成品对象(完成实例化但未完成初始化);
3.也就是说走到最后一条连线前A对象其实已经存在的,但此时是一个半成品对象;
4.因此我们可以让其在持有一个对象的引用之后,在后续的步骤再给对象进行赋值操作,这样也就解决了;
Spring解决这个问题的本质就是让实例化和初始化可以分开执行;
具体步骤
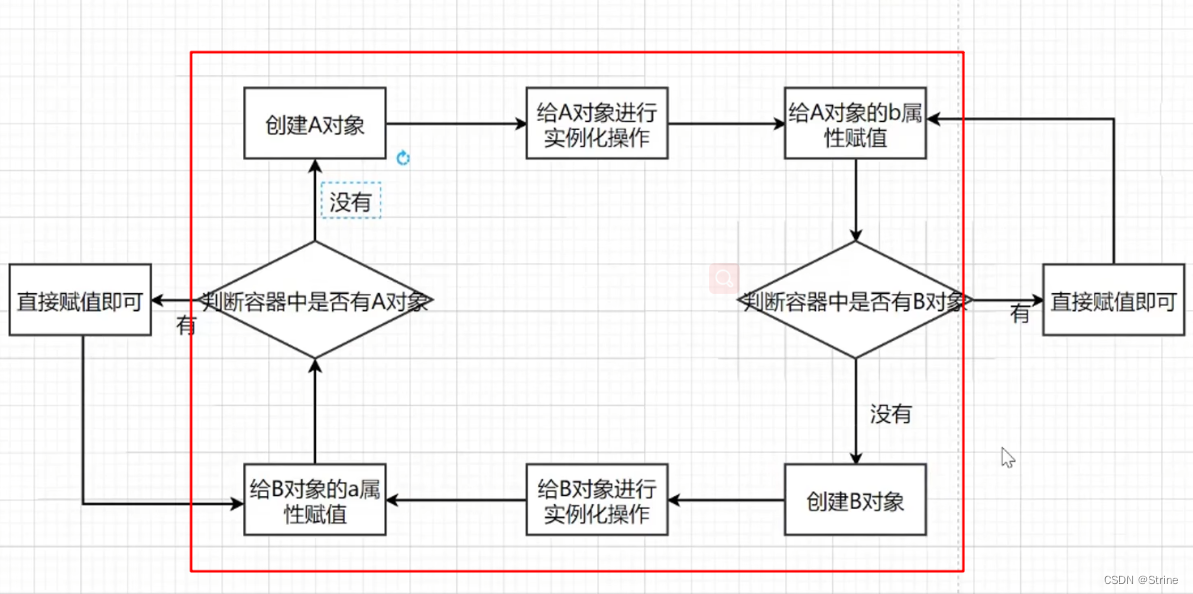
1.我们知道Spring在实例化对象的时候使用的存储结构是一个Map结构,那么我们可以在A对象实例完成之后(初始化之前),再额外添加一个缓存,让这个半成品对象存放在另外一个map里面;
2.因此在判断容器中是否有对应对象的时候就到这个缓存里面去找;这个时候没有找到B对象,则创建B对象
3.再把B对象的半成品对象放到缓存中去,这个时候需要进行B对象的初始化操作,到缓存中去找,这个时候找到了A的半成品对象,然后进行赋值;,赋值完成之后再将B对象的成品对象再放到缓存中去;
4.这个时候B成品对象存在了,那么就可以完成A对象的初始化操作了;
图解
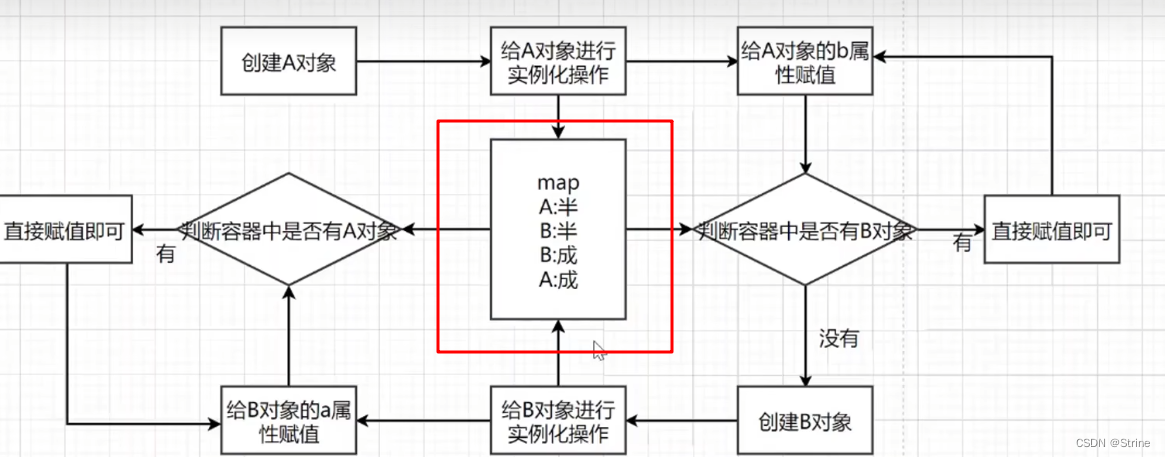
但是我们可以发现这个Map结构很乱,它里面既有半成品对象,也有成品对象,因此我们可以将这个Map拆开,拆分为几个不同的Map结构,这也就是我们三级缓存的实现原理,也就是说三级缓存其实就是三种不同的map结构;
源码分析
这三个不同的map结构在DefaultSingletonBeanRegistry这个类中:
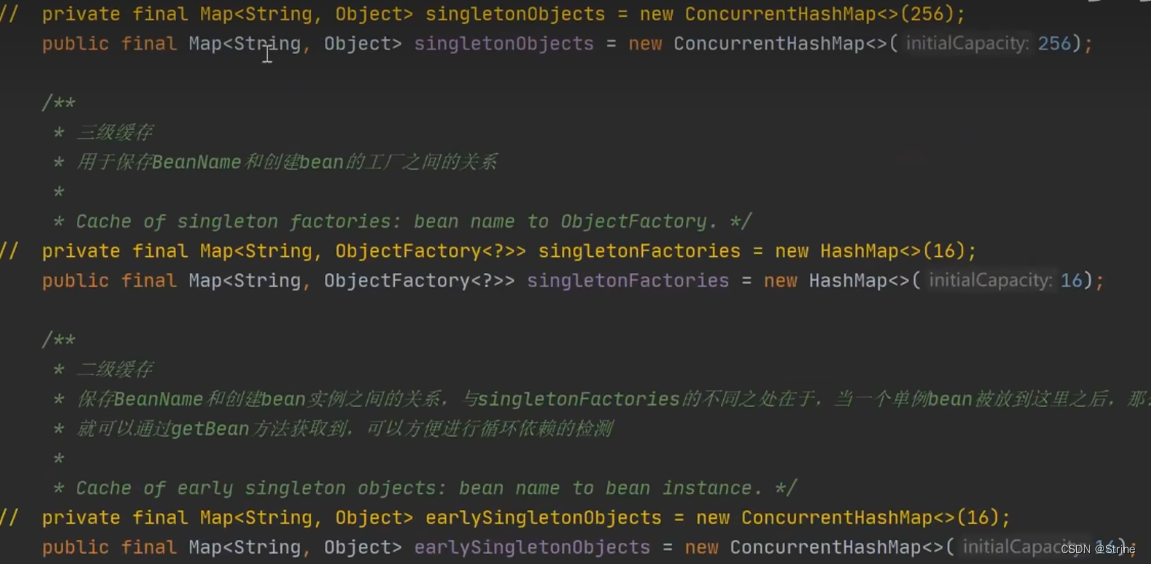
一级缓存(singleTonObjects);二级缓存(earlySingletonObjects);三级缓存(singletonFactories)
我们可以发现一级缓存和二级缓存都是ConcurrentHashMap,并且值的类型都是Object;
而三级缓存是HashMap,值的类型是一个函数式接口:ObjectFactory<?>:
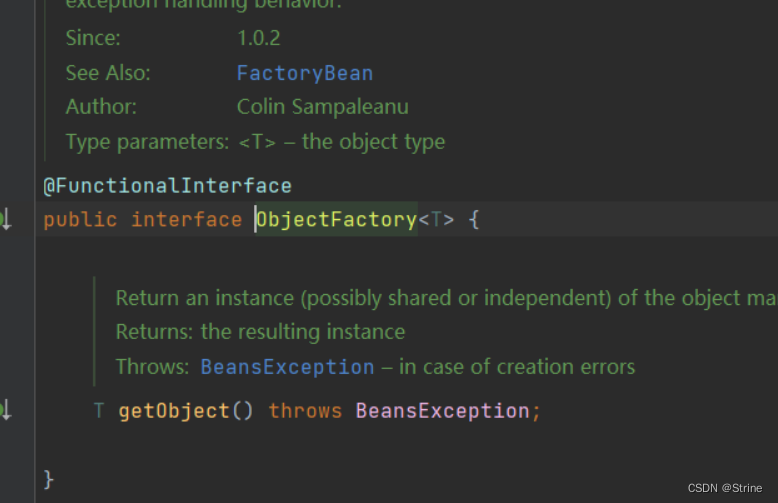 二级缓存和三级缓存的默认容量为16.而一级缓存的默认容量为256;
二级缓存和三级缓存的默认容量为16.而一级缓存的默认容量为256;
模拟循环依赖Debug分析
我们就以最开始的A对象和B对象的形态来进行Debug模拟,观察这三个缓存结构:

在最开始的时候,这三个缓存结构里面都没有我们的A、B对象;
我们继续往下走:
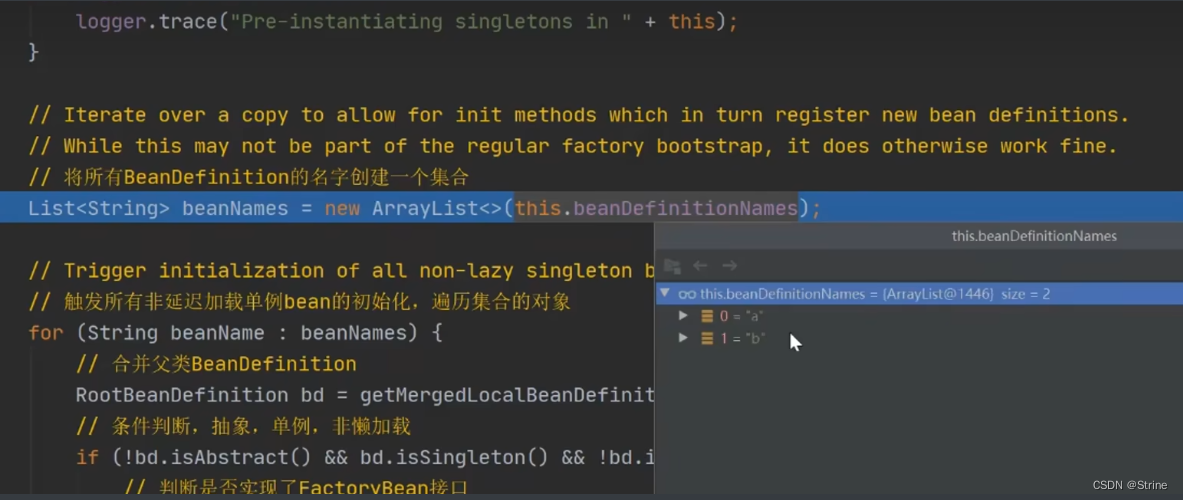
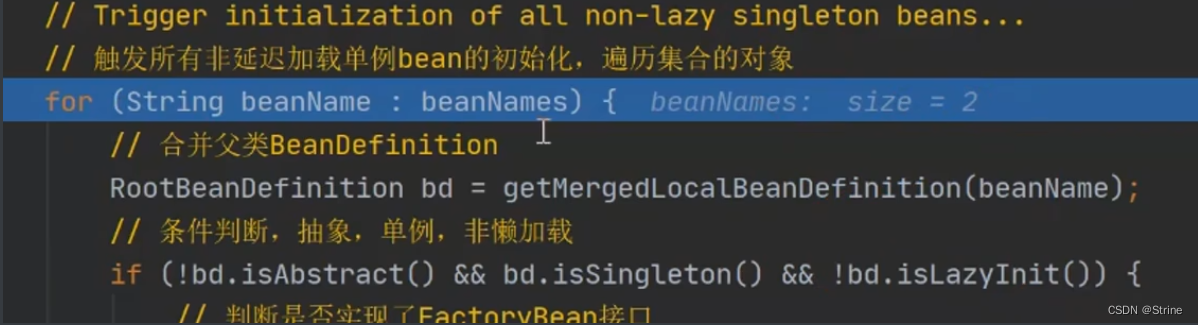
1.到真正创建Bean对象的这一步,首先它获取到了我们beanNames并放到一个list集合里面;
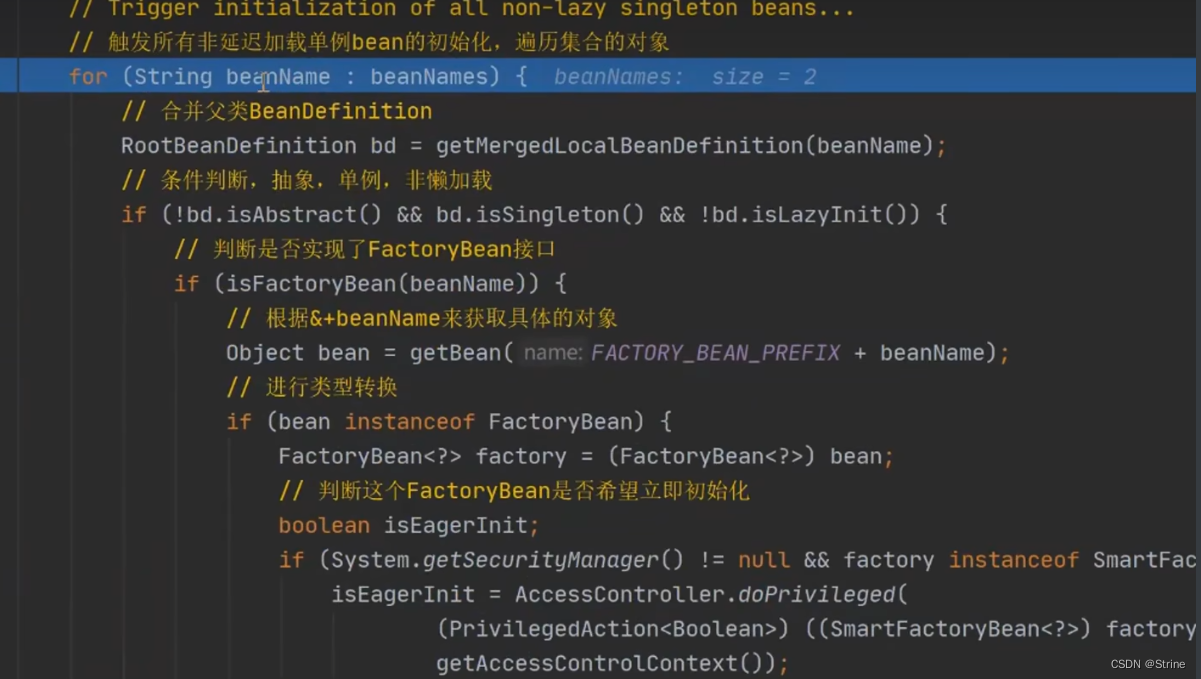
2.循环这个list集合进行Bean对象的创建(第一次);

3.首先它肯定会通过getBean方法去尝试在容器里面获取对象(判断当前容器有没有该对象);

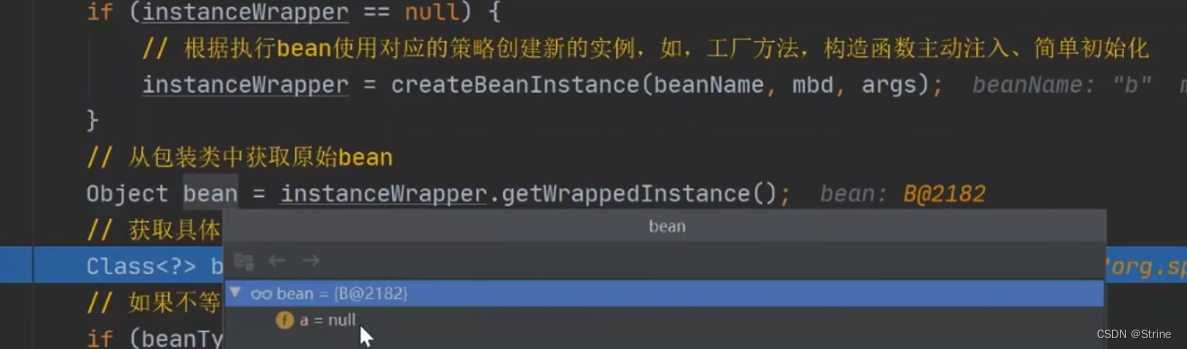
4.第一次获取肯定是没有的,因此它会去调用一系列的方法(createBean=>doCreateBean=>createBeanInstance=>instantiateBean=>instantiate=>instantiateClass),通过反射创建Bean对象;
5.这个时候我们的A对象就创建好了,并且现在它里面的b属性为null(还没有进行初始化);

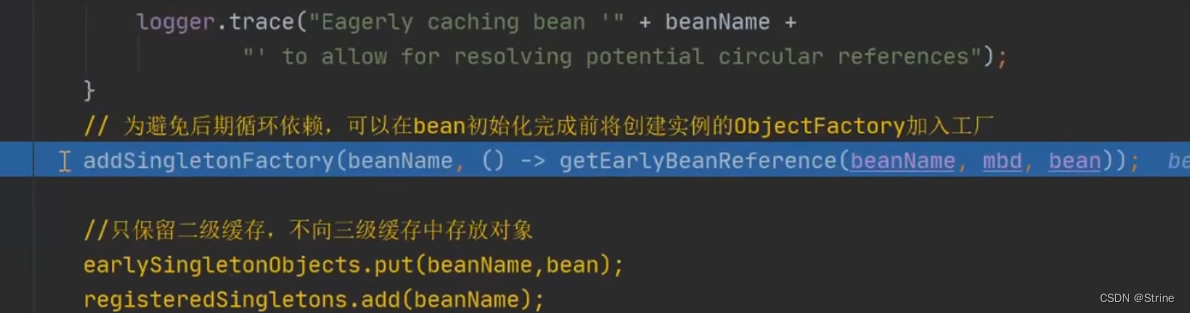
6.它在这里调用了addSingletonFactory方法
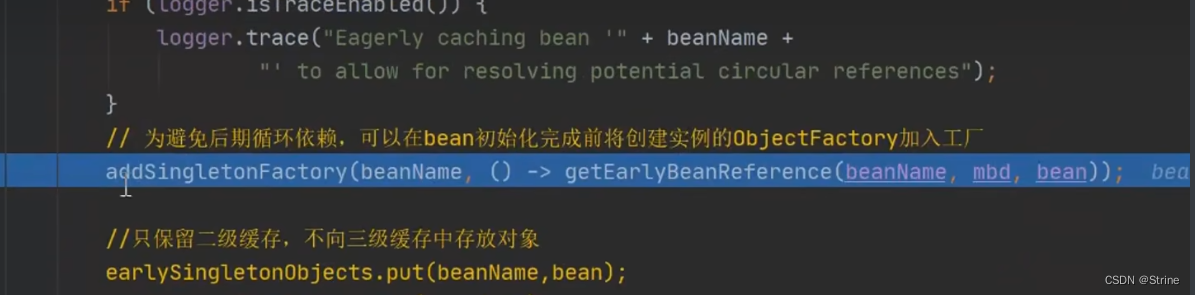
7.我们点开这个方法发现它将A对象(key)和lambda表达式(value)放到了三级缓存中去;并且移除了二级缓存中的该对象(刚开始本来就是空的);也就是说我们现在其实只是将lambda表达式放到三级缓存中去了,我们的A对象并没有放到三级缓存中去;

8.调用populateBean方法进行A对象的初始化操作
9.直接看最后一行代码调用的applyPropertyValues方法进行自定义属性的赋值;直接看这个方法里面对属性的操作,首先它先获取到属性名,然后再去获取到属性值,正常情况下我们的属性值是一个B对象,但是这个时候并没有B对象,并且它获取到的值并不是一个实际的B对象,而是一个RuntimeBeanReference<b>;
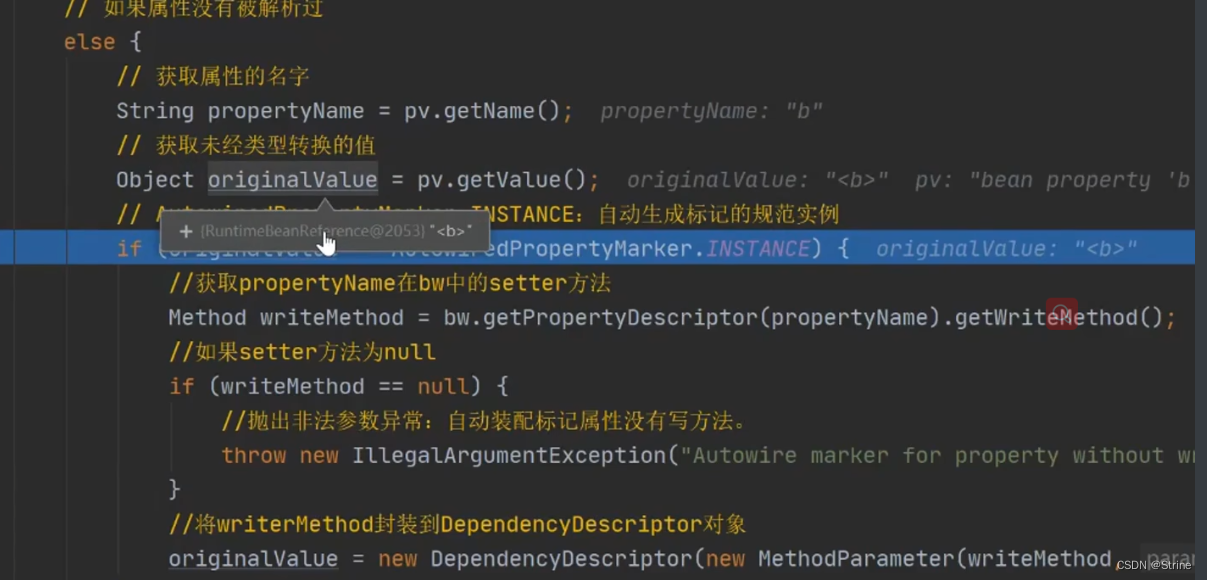
10.那么就需要对该RuntimeBeanReference对象进行处理,首先进行类型的强制转换,将其转换为RuntimeBeanReference;
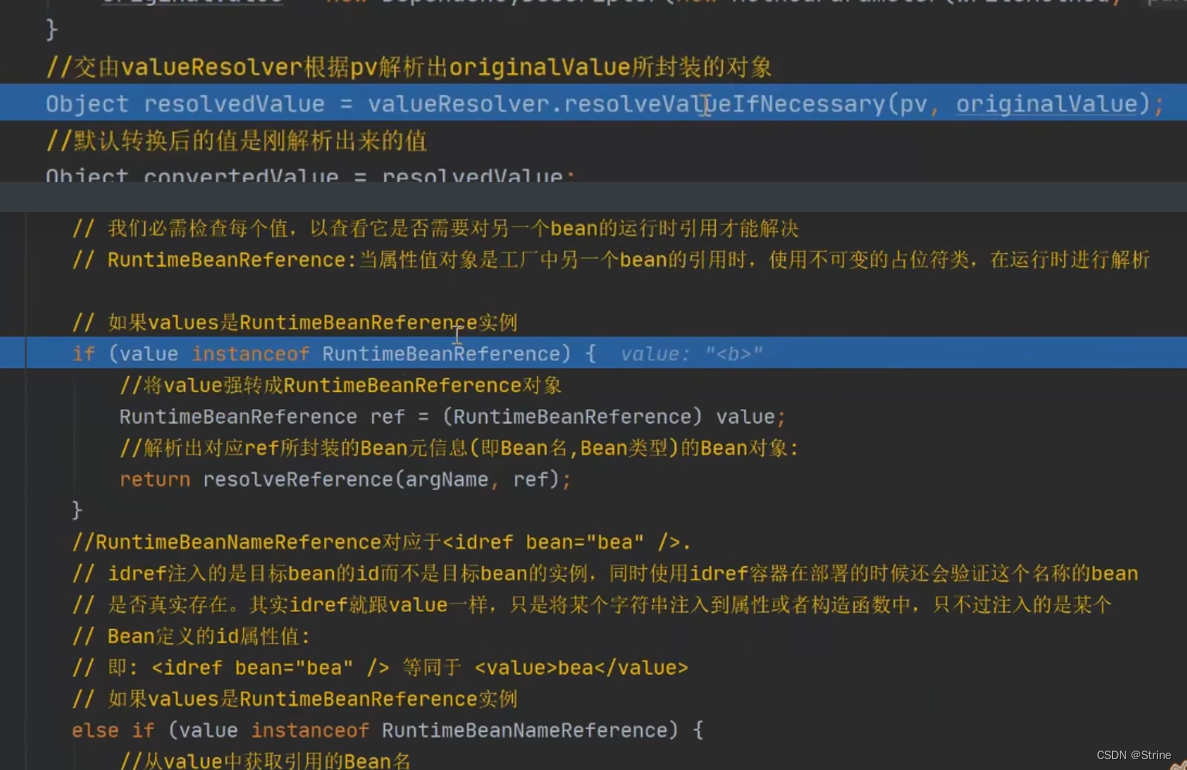
11.然后调用resolveReference处理引用方法,在这个方法里面,也是进行一些相关判断,然后这里最关键的地方来了:第二次调用getBean方法去获取B对象,当然这个时候也是获取不到B对象的,因此也需要通过上面一系列流程去创建B对象,
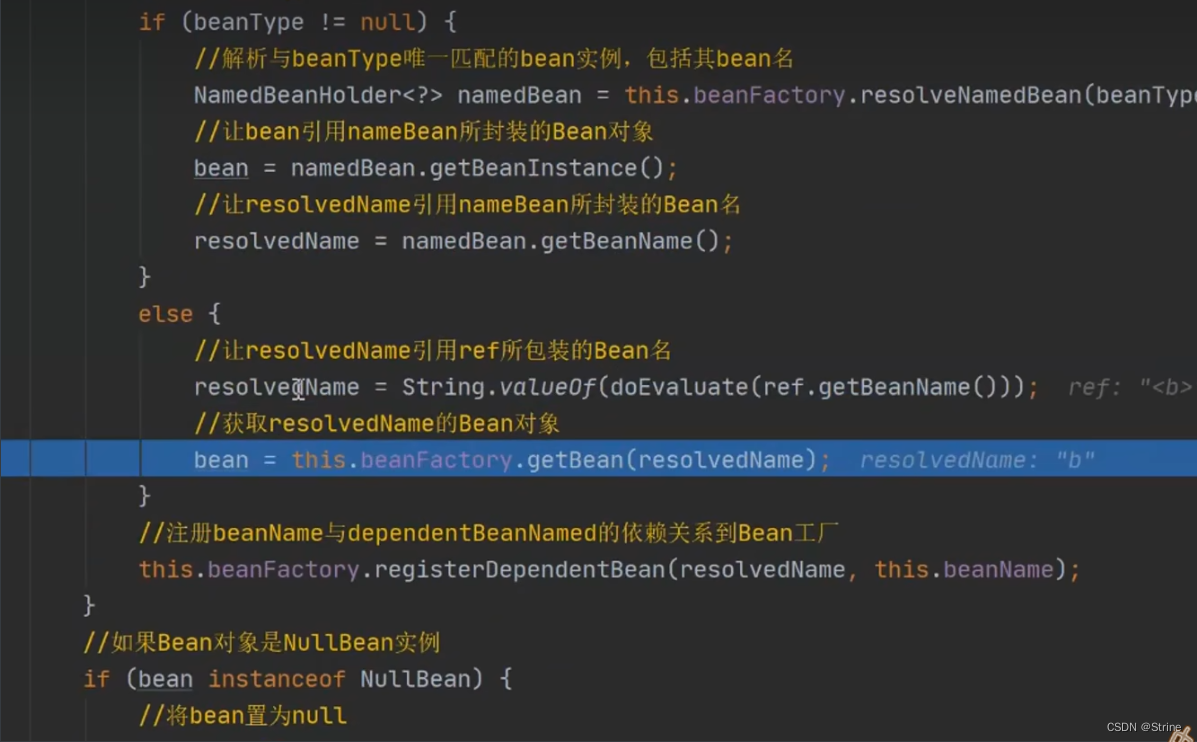
12.创建好之后我们,B对象里面的A属性也是等于null(因为也还没有开始初始化)也就是说到这一步我们就有A、B两个半成品对象了:
13.也是相同的,调用该方法,将B对象(key)和lambda表达式(value)存入三级缓存中去:
14.然后继续往下走,执行B对象的初始化工作,到applyPropertyValues方法
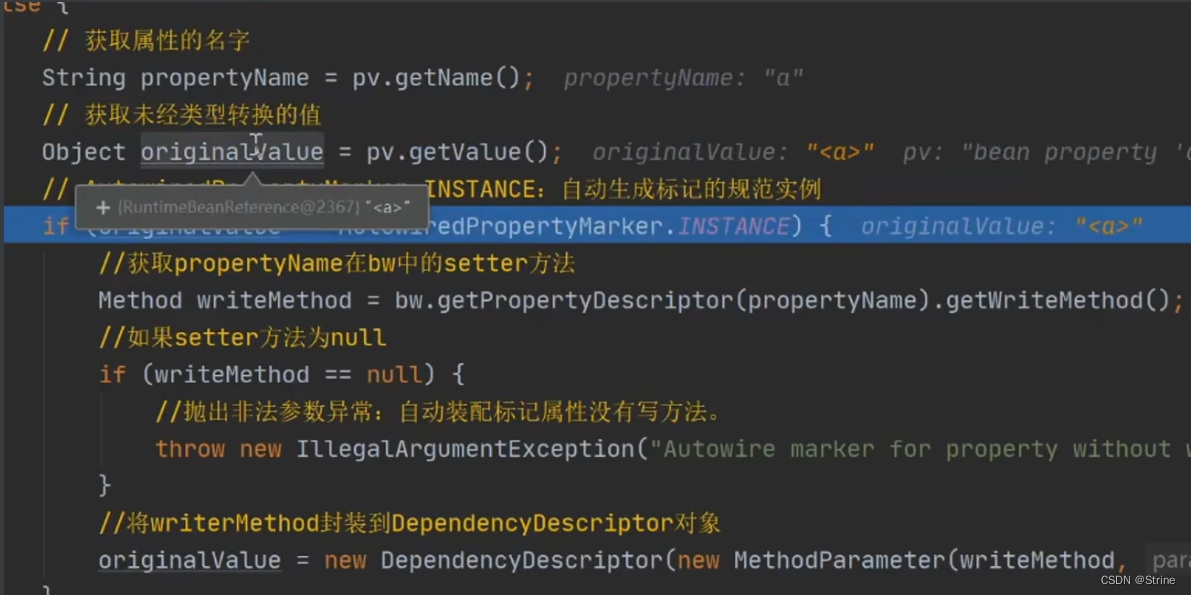
 15.继续走到该方法里面的获取属性值的地方,我们发现它现在获取到的属性值A依旧是RuntimeBeanReference:
15.继续走到该方法里面的获取属性值的地方,我们发现它现在获取到的属性值A依旧是RuntimeBeanReference:
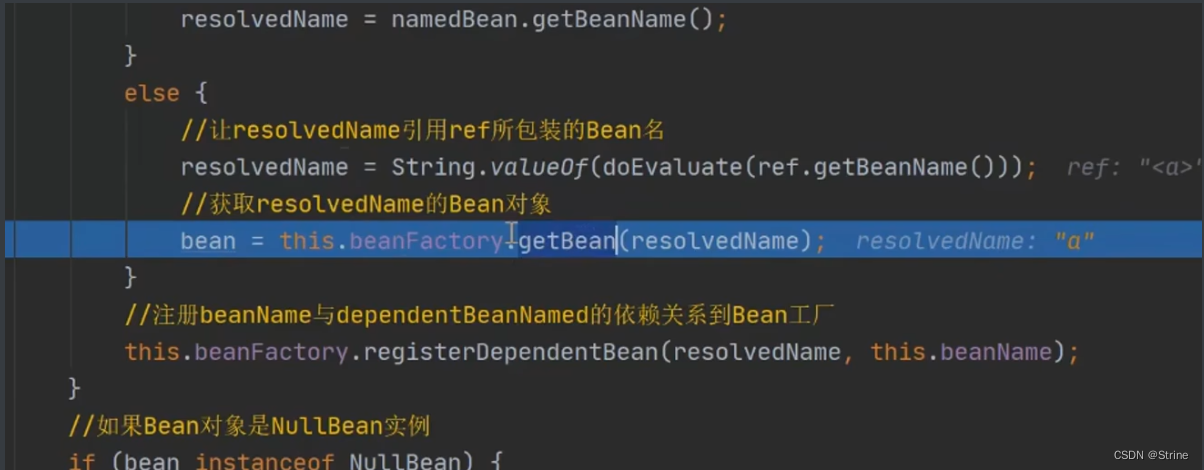
16.然后继续往下走处理该属性值(强转,调用resolveReference方法),这个时候第三次调用getBean方法尝试去获取A对象,
 17.但是这个时候进入到doGetBean方法调用getSingleton的时候就不跟之前一样了;
17.但是这个时候进入到doGetBean方法调用getSingleton的时候就不跟之前一样了;
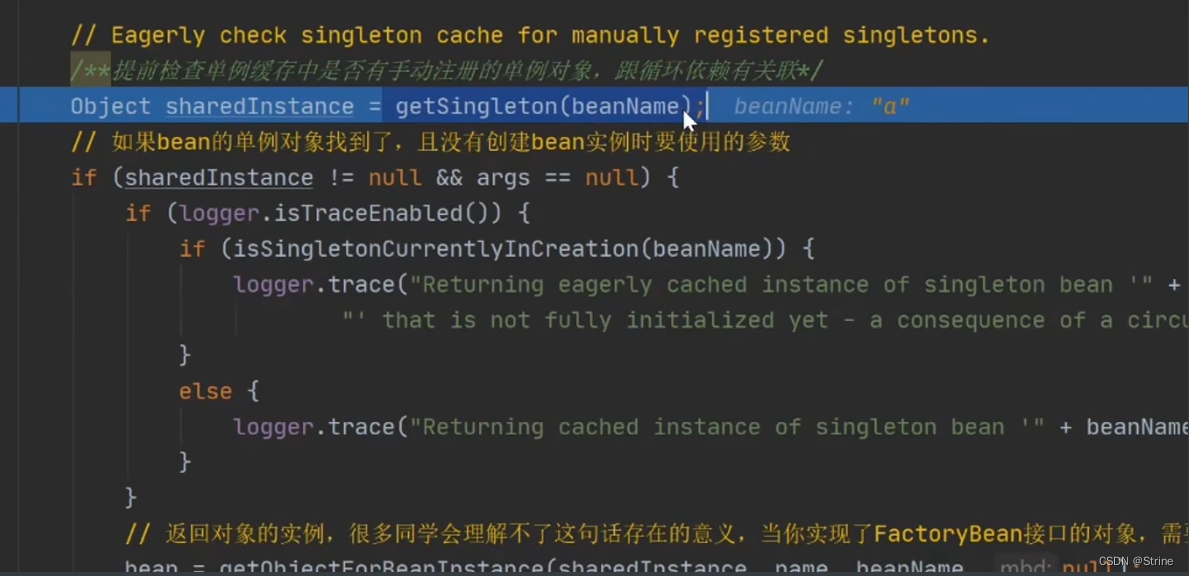
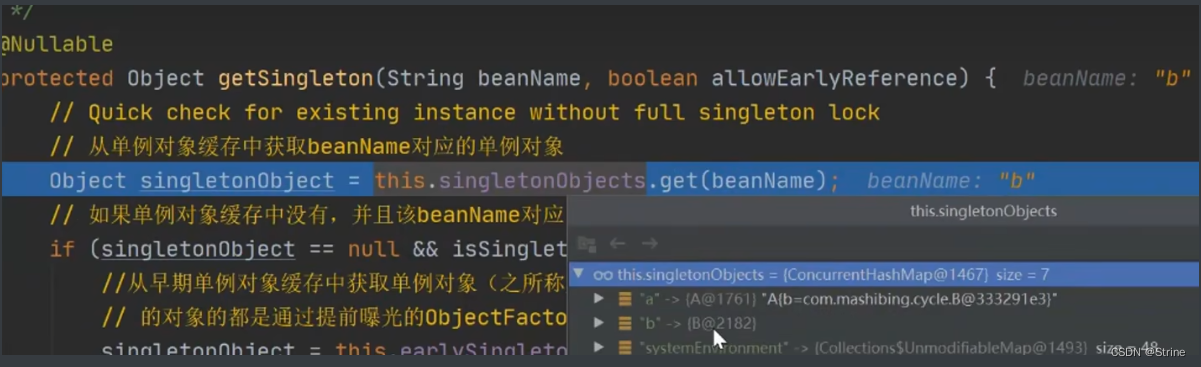
18.首先到一级缓存中去取,肯定是取不到的,
因此第二个判断是否为空并且当前对象是在创建过程中的,则在二级缓存中去取该对象;
这个时候也是取不到数据的,因此再进入到下一个判断中去,执行一个synchronize的双重检查(避免在执行到这一步操作的时候,其他线程在一级缓存中创建好的目标对象,因此这个时候再到一级缓存和二级缓存中去取)
如果这个时候还是取不到,才通过beanName去三级缓存中去取相关的Lmabda表达式,这个时候获取到了
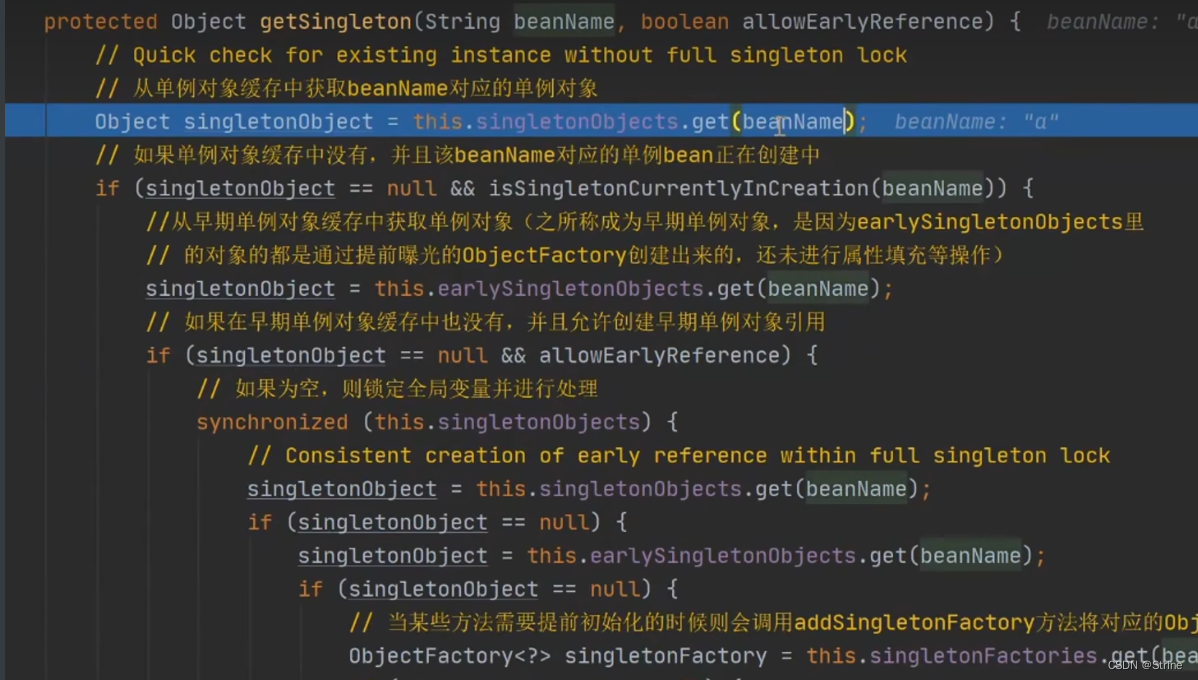
这个时候不为空,则去调用Lambda表达式中的getObject方法(注意,因为是函数式接口,因此只有在调用getObject方法的时候,才会去执行下面这个Lmabda表达式)

19.因此进入到这个方法里面去,我们就可以看到暴露对象这个关键字,首先它把A这个对象赋值给这个暴露对象(exposedObject)并且最终返回的也是它,那为什么不直接返回呢?
是因为在这个过程中是有可能将代理对象替换原始对象的,不信我们继续往下点;
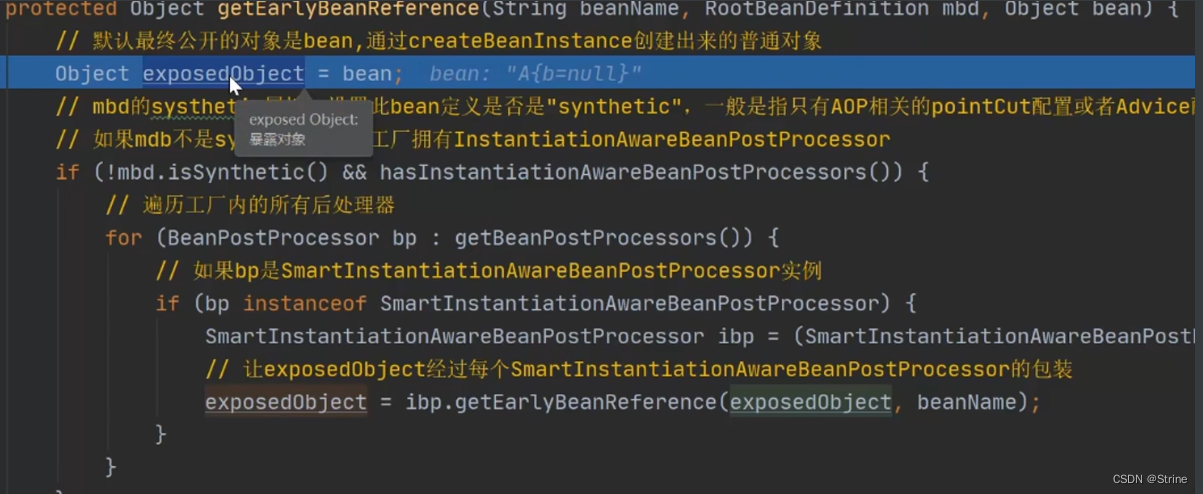
20.点开getEarlyBeanReference这个方法接口的下面这个子类:
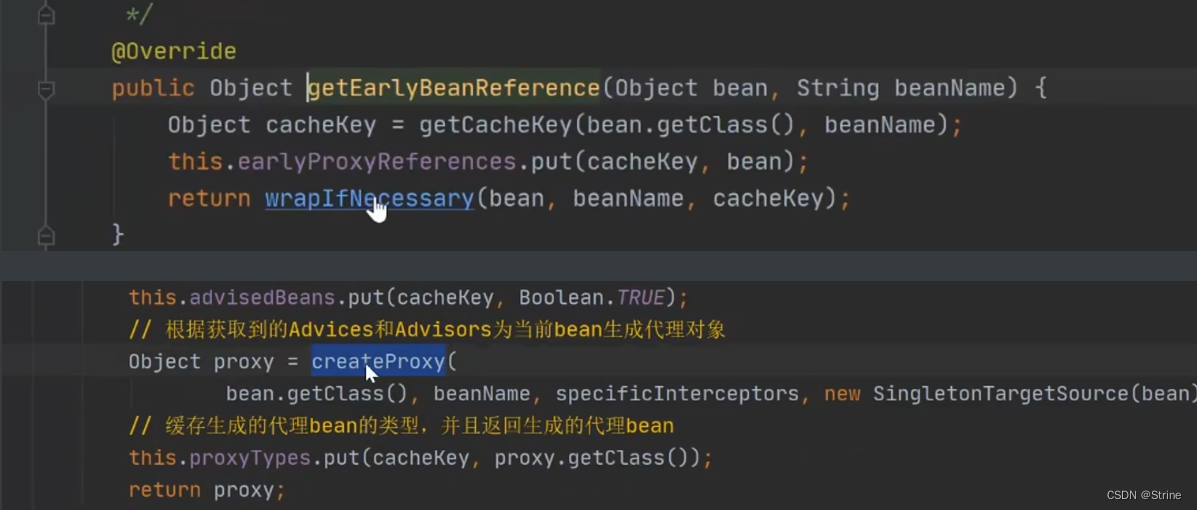
 21.跟我们昨天讲的内容相同,点开wrapIfNecessary方法,我们可以看到它有一个createProxy方法创建代理对象;
21.跟我们昨天讲的内容相同,点开wrapIfNecessary方法,我们可以看到它有一个createProxy方法创建代理对象;
22.但是我们这里什么都没有配,因此就跳过了直接返回这个暴露对象;这个时候我们就取出了这个A对象:这个时候我们再把这个A这个半成品对象放入二级缓存中去,然后再把它从三级缓存中移除掉(避免空间浪费);
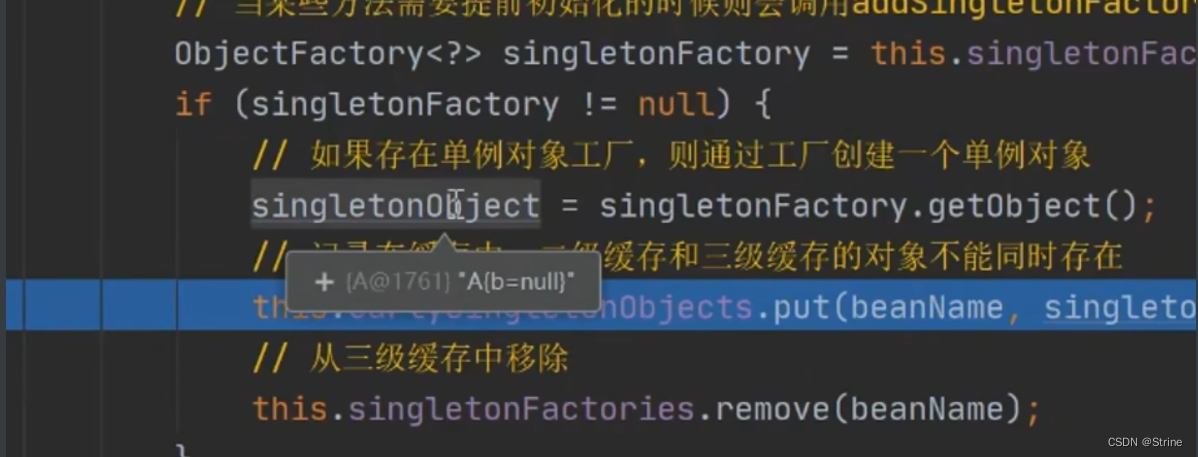
23.也就是说我们通过这一些系列操作,getBean方法成功获取到了A这个半成品对象,这个时候就不用再去继续创建了: 
24.对B对象的A属性进行赋值,因此这个时候我们的B对象的A属性就有值了,并且我们现在的B是一个成品对象:

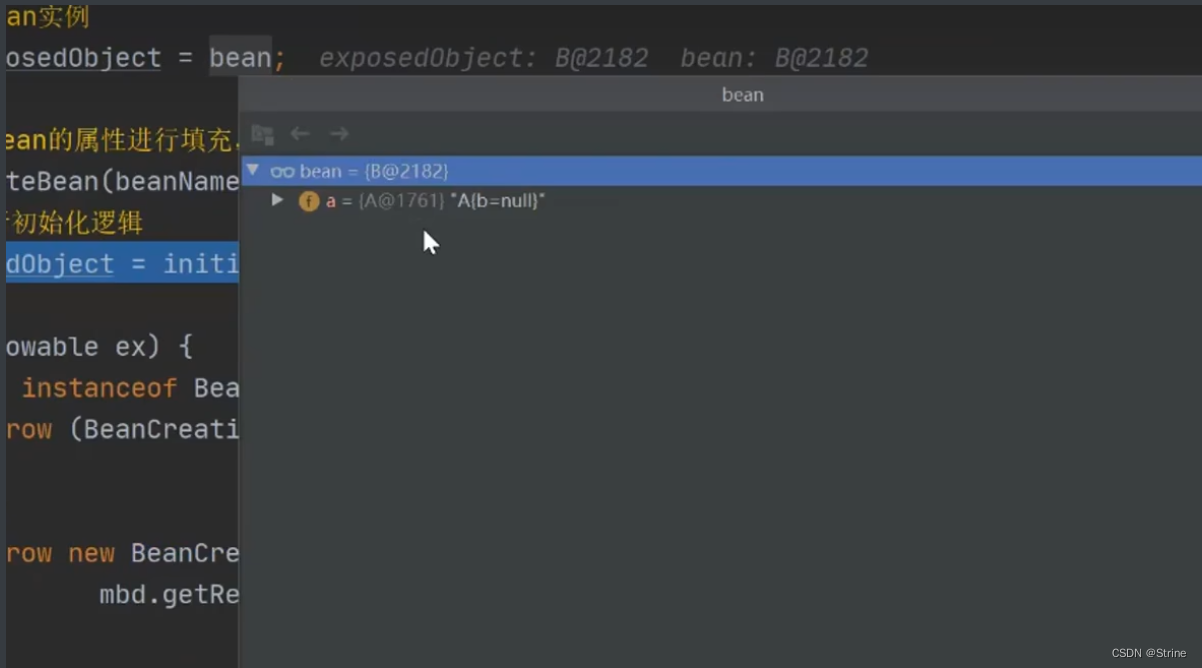 25.因此这个时候,然后最外面的getObject方法就获取到了值了:
25.因此这个时候,然后最外面的getObject方法就获取到了值了:

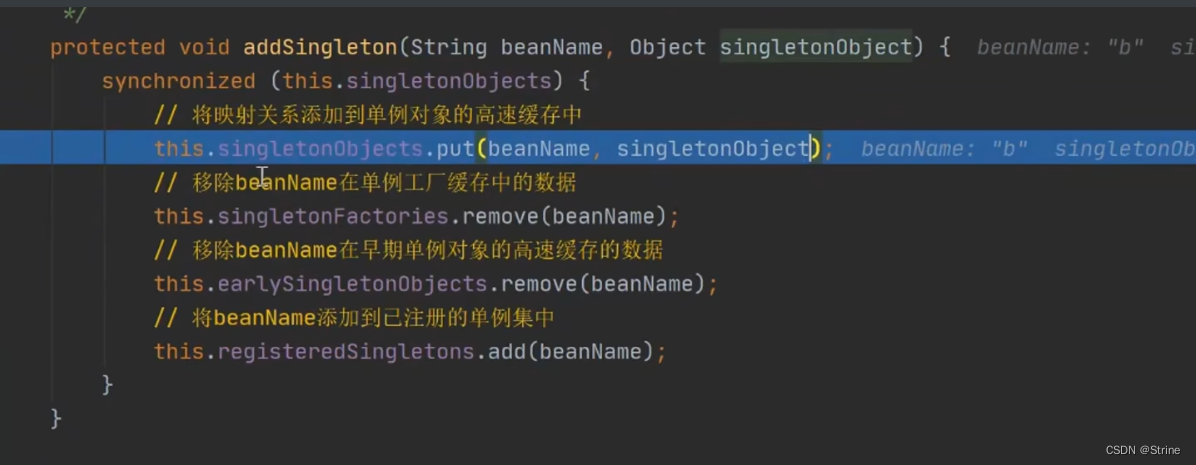
26.然后它调用了一个addSingleton方法,在这个方法里面先将获取到的这个B成品对象放到一级缓存中,然后再移除三级缓存和二级缓存;
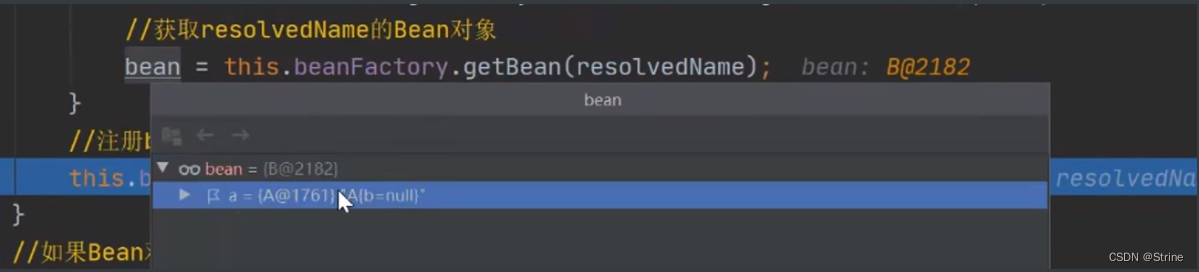
27.因此这个时候最外面的A对象的getBean方法也成功获取到了B这个成品对象
28.再调用A对象的setPropertyValues方法进行A对象中B属性的赋值,这个时候我们的A对象就是一个成品对象了: 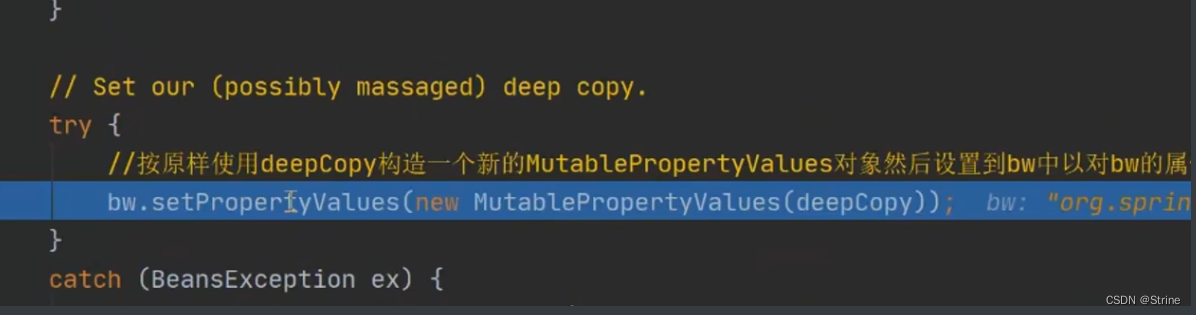
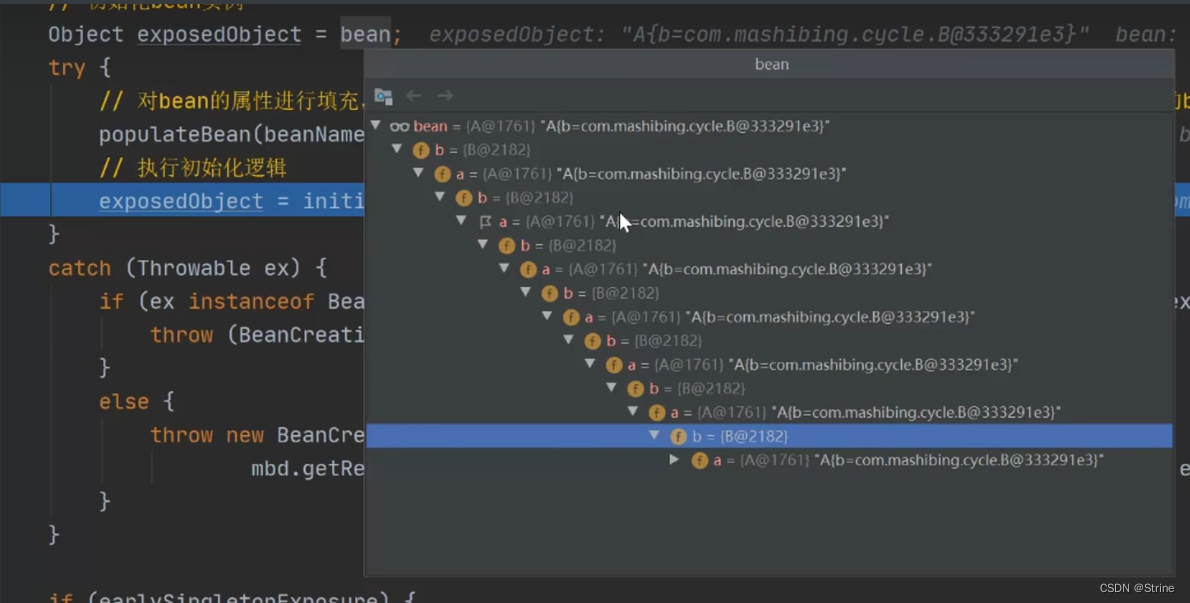 29.再走到A对象的addSingleton方法将A对象放入一级缓存中去;
29.再走到A对象的addSingleton方法将A对象放入一级缓存中去;
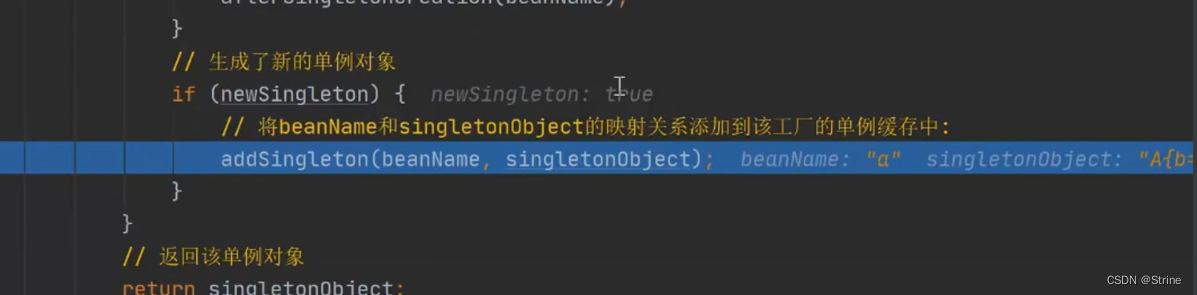 30.这个时候回到最外面的创建对象的循环去,因为我们上面的一系列操作都只是针对第一个循环的对象,只不过A对象需要B对象因此才创建了B对象,但是外面这个循环才执行完一次,因此这个时候要回到这个循环中去对B对象进行操作
30.这个时候回到最外面的创建对象的循环去,因为我们上面的一系列操作都只是针对第一个循环的对象,只不过A对象需要B对象因此才创建了B对象,但是外面这个循环才执行完一次,因此这个时候要回到这个循环中去对B对象进行操作
31.但是走到B对象的getSingleton方法的时候就能够直接在一级缓存中取到B这个成品对象了,因此B对象不需要再进行那么多操作了
到这个地方我们整个循环就结束了,这个才是我们整个出现循环依赖问题后的创建过程;
我们的成品对象最终放在一级缓存中,只有当容器关闭的时候才会清空;
那么我们再来解决下面这些问题:
三级缓存分别存放什么?
一级缓存:存放成品对象;
二级缓存:存放半成品对象;
三级缓存:存放Lambda表达式;
查找的顺序是1=>2=>3;
为什么要使用三级缓存,一级、二级缓存能否解决问题
如果是一级缓存(也就是说只有一个map结构):
理论上是可行的,实际上没人这么做;
我们之所以要使用三级缓存,就是为了把成品对象和半成品对象区分开来,因为半成品对象是不能够直接暴露给外部使用的,但是也可以使用标识来区分成品对象和半成品对象,但是这样操作起来比较麻烦,代码复用性差,且维护起来不方便,因此实际上没人这么做;
如果是二级缓存(也就是说只有两个map结构):
也是可以解决的,但是有前提条件:当不使用AOP的时候(没有代理对象的时候),两个缓存map就可以解决循环依赖问题;
但是当使用AOP(或者需要生成代理对象的时候),就会出现以下错误:
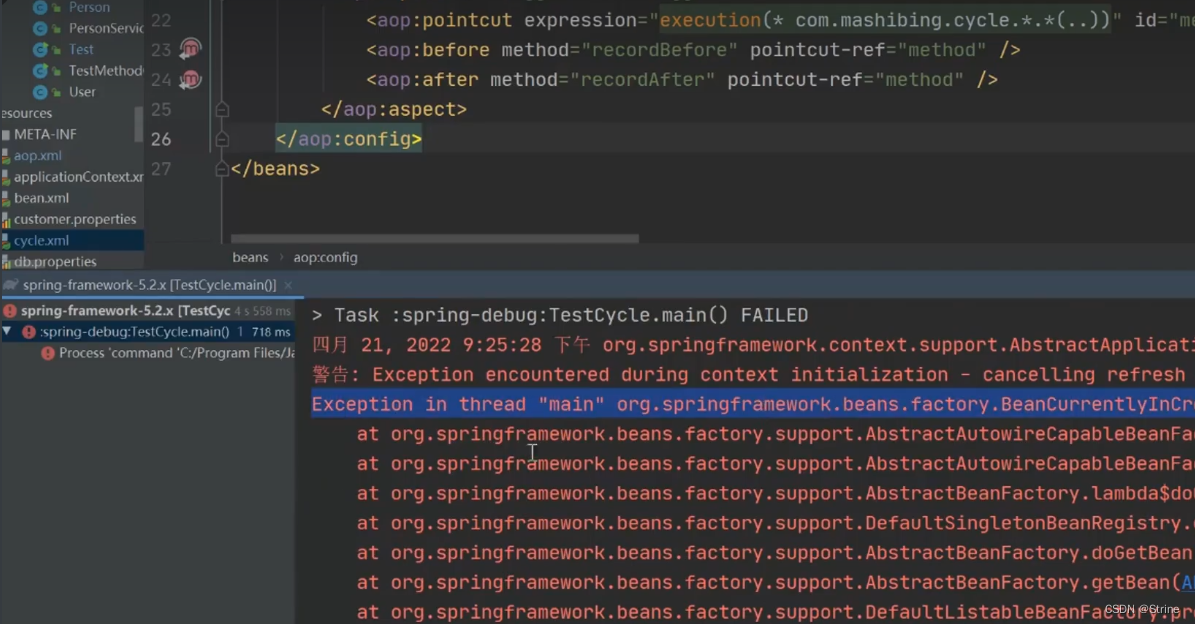

因此我们就要思考为什么使用三级缓存就可以解决带aop的循环引用?
首先一个容器不能包含两个同名的对象,对象在创建过程中原始的对象有可能需要创建代理对象,当中途创建出了代理对象的时候,程序是应该使用代理对象而非原始对象的,但是程序是死的,是提前写好的,它并不知道这种情况下需要使用代理对象替换掉原始对象;并且我们通过源码也了解到了,代理对象的创建是在初始化过程的后置方法中执行的,而属性的赋值是在生成代理对象之前执行的,需要在前置过程(属性赋值)的时候判断是否需要生成代理对象;那怎么才能完成替换呢?

因此三级缓存就是为了解决这个问题的
那么为什么非要使用函数式接口加lambda表达式的机制来完成呢?
因为对象在什么时候被暴露出去或者被其他对象引用是没办法提前确定好的,所以只有在被调用的那一刻才可以进行使用原始对象还是代理对象的判断,因此使用Lambda表达式类似一种回调机制,不暴露的时候不需要调用执行,只有在需要被调用的时候才真正执行Lambda表达式来判断返回的到底是代理对象还是原始对象;
















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











