






数据库操作
#层级:数据库->表格->列
#1.展示所有数据库
show databases;
#2.创建一个数据库:create database 数据库名;
create database test2;
#3.选中数据库: use 数据库名;
use test2;
#4.展示数据库中所有的表格
show tables;
表格操作
#5.创建数据库表格
/*
create table 表格名字(
列1名称 数据类型(长度) 主键/唯一键 是否允许为空 备注,
列2名称 数据类型(长度) 键 是否允许为空 备注,
列3名称 数据类型(长度) 键 是否允许为空 备注,
[foreign key(列) references 另一个表(列)]
) charset=字符集;
*/
#班级表
create table class(
class_id int(2) primary key comment'班级编号',
class_name varchar(20) comment'班级名称',
address varchar(30) comment '班级地址'
);
#学生表
create table student(
sid char(12) primary key comment'学号',
sname varchar(20) not null comment '学生名字',
birth datetime comment '出生日期',
class_id int(2) comment'班级编号',
foreign key(class_id) references class(class_id)
) charset=utf8mb4;
#6.修改表格的列,新增列或是修改原有的列,或是删除原有的列
#(1).新增列,例如:学生表增加一个性别的列
#alter table 表格名字 add 列名字(长度) comment'备注';
alter table student add sex varchar(4) comment'性别';
#描述表格属性: desc 表格名字;
desc student;
#(2).修改原有的列,例如:把学生表的性别的列改成整数类型
alter table student modify sex int(2) comment'性别';
#(3).删除原有的列,例如:把学生表的性别的列删除
alter table student drop sex;
#7.删除表格:drop table 表格名字;
drop table student;
#8.删除数据库:drop database 数据库名字;
drop database test2;
#9.删除约束,删除主键或者外键、唯一键:alter table 表格名字 drop 键;
#例如:删除学生表的主键:alter table 表格名字 drop primary key;
alter table student drop primary key;
#例如:删除学生表的外键:alter table 表格名字 drop foreign key 外键名字;
alter table student drop foreign key student_ibfk_1;
#10.修改表格名称:alter table 表格名字 rename 表格新名字;
alter table student rename student_tab;
数据处理-增删改
#(1) 新增一条数据,如果值的类型是字符串的话,要用单引号给括起来
#写法一:增加指定的一些列的值:insert into 表格名字(列1,列2,列3) values(列1的值,列2的值,列3的值);
#例:
insert into student(sid,sname,birth) values('1002','钱二','2002-01-01');
#写法二:增加所有的列的值,按照表格列的顺序把所有值和列一一对应,部分值可以填null:insert into 表格名字 values(列1的值,列2的值,列3的值,列4的值);
#例:
insert into student values('1003','张三','2001-03-01', null);
#一次性增加多条数据:insert into 表格名字 values(列1的值,列2的值,列3的值,列4的值),(列1的值,列2的值,列3的值,列4的值);
#例:
insert into student values('1004','李四','2001-04-01', null),('1005','王五','2001-05-01', null);
#(2) 修改数据记录
关闭安全模式:
#关闭安全模式:
set sql_safe_updates=0;
#把学号是1001的学生的名字更改:
# update 表格名字 set 列1名字=新的值 where 列的名字=‘值’;
# !如果没有where 列的名字=‘值’ 这个条件,那么就会把整个表格的列1的值全部更改!
#例:
update student set sname = '赵一' where sid = '1001';
#如果同时更改多个列
# update 表格名字 set 列1名字=列1新的值,列2名字=列2新的值,列3名字=列3新的值 where 列的名字=‘值’;
#例:
update student set sname = '赵一一',birth='2002-01-01' where sid = '1001';
#(3)删除数据记录
#delete from 表格名字; – 意思是把整个表格的数据删除
#delete from 表格名字 where 条件列=值;
#例:
delete from student where sid='1001';
查询
#查询某个表格所有的列的所有记录
#select * from 表格名字;
select * from emp;
#查询指定的列的所有记录
select empno,ename,job from emp;
#条件查询:where 关键字
select * from emp where deptno=20; -- 查询部门编号为20的所有列的记录
select empno,ename,deptno from emp where deptno=20; -- 查询部门编号是20的员工工号和名字
#比较查询
#运算符比较 > < >= <= != =
select * from emp where sal >= 2000; -- 查询薪资大于2000的员工记录
select * from emp where comm != 0;-- 查询comm佣金不为0的记录
#逻辑运算符 and与 or或 not非
select * from emp where deptno=20 and sal > 2000; -- 查询部门编号为20的 并且 薪资大于2000的记录
select * from emp where deptno=20 or job = 'CLERK'; -- 查询部门编号为20的 或者 工作job是'CLERK'的记录
select * from emp where comm is not null;-- 查询comm佣金不为空的记录
#范围条件查询 BETWEEN…AND
select * from emp where sal between 2000 and 3000;-- 查询薪资是2000到3000之间的记录
select * from emp where sal >=2000 and sal <=3000;
#列表条件查询 in 或 not in
select * from emp where deptno not in (20,30);-- 部门编号是在20,30的任意一个里面
#模糊查询 like
#通配符 %代表0个或多个字符 _代表一个字符
select * from student where sname like '赵%';-- 查询姓赵的同学
#排序 order by 列名 asc/desc asc升序从小到大 desc降序从大到小
select * from emp order by sal desc;
练习:
create table person (
username varchar(20) comment '姓名',
address varchar(128) comment '地址',
salary int(6) comment '工资',
department varchar(20) comment '部门'
) charset = utf8mb4 ;
insert into person values
('张三','武当',6000,'保洁部'),
('张无忌','魔教',6000,'事业部'),
('张三丰','武当',4000,'产业部'),
('周芷若','峨眉',8000,'事业部'),
('谢逊','魔教',5000,'产业部'),
('杨逍','魔教',7000,'事业部')
;
-- 3.请以下面的方式查询出所有信息:
-- 姓名 居住地 月薪 年薪
-- 张三 武当 6000 72000
-- pname as "姓名"
select username as '姓名',address as '居住地',salary as '月薪', (salary*12) as '年薪' from person;
-- 4.请查询出所有部门为事业部的所有人信息
select * from person where department = '事业部';
-- 5.请查询出所有地址为魔教的所有人信息
select * from person where address = '魔教';
-- 6.请查询出所有工资为6000元的人的所有信息
select * from person where salary = 6000;
-- 7.请查询出所有工资在6000-8000之间的所有人的信息
select * from person where salary between 6000 and 8000;
-- 8.请查询出所有工资是6000,7000,8000的所有人的信息
select * from person where salary in (6000,7000,8000);
-- 9.请查询出所有工资在6000-8000之间,或者姓张的所有人的基本信息
select * from person where salary between 6000 and 8000 or username like '张%';
-- 10.请查询出所有工资为6000,7000,8000,或者姓张,并且不叫张三丰的所有人的基本信息
select * from person where salary in (6000,7000,8000) or username like '张%' and username != '张三丰';
-- 11.请查询出所有工资为5000,或者叫张三的人的所有信息
select * from person where salary = 5000 or username = '张三';
-- 12.请查询出所有魔教的人的信息,按照人名升序排列
select * from person where address = '魔教' order by username asc;
-- 13.请查询出工资高于5000的人员信息,按照address降序排列
select * from person where salary > 5000 order by address desc;
-- 14.请查询出所有人的信息,先按照salary降序排列,若一致,则按照人名升序排列
select * from person order by salary desc, username asc;
案例表:emp
CREATE TABLE `emp` (
`empno` int(5) DEFAULT NULL,
`ename` varchar(20) DEFAULT NULL,
`job` varchar(20) DEFAULT NULL,
`mgr` int(5) DEFAULT NULL,
`hiredate` date DEFAULT NULL,
`sal` int(5) DEFAULT NULL,
`comm` int(5) DEFAULT NULL,
`deptno` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into emp values (7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1981-2-22',1250,500,30),
(7566,'JONES','MANAGER',7839,'1981-4-2',2975,NULL,20),
(7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250,1400,30),
(7698,'BLAKE','MANAGER',7839,'1981-5-1',2850,NULL,30),
(7782,'CLARK','MANAGER',7839,'1981-6-9',2450,NULL,10),
(7788,'SCOTT','ANALYST',7566,'1987-4-19',3000,NULL,20),
(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10),
(7844,'TURNER','SALESMAN',7698,'1981-9-8',1500,0,30),
(7876,'ADAMS','CLERK',7788,'1987-5-23',1100,NULL,20),
(7900,'JAMES','CLERK',7698,'1981-12-3',950,NULL,30),
(7902,'FORD','ANALYST',7566,'1981-12-3',3000,NULL,20),
(7934,'MILLER','CLERK',7782,'1982-1-23',1300,NULL,10) ;
分组统计
统计函数 sum() 求和函数 avg() 平均值函数 max() 求最大值 min() 求最小值
# count(*) 计数
select count(*) as '总人数' from person;
# select sum(列名) from 表格名字;
select sum(sal) as '总工资' from emp;
select avg(sal) as '平均工资' from emp;
select max(sal) as '最高工资' from emp;
select min(sal) as '最低工资' from emp;
分组:group by
统计分组 :求每个部门的总工资和平均工资是多少
#先分组后统计
select deptno,sum(sal),avg(sal) from emp group by deptno;
#每个部门的人数分别有多少
select deptno,count(empno) from emp group by deptno;
#每个部门的最高工资
select deptno,max(sal) from emp group by deptno;
#分组的同时进行条件筛选
#查询每个部门除了经理以外其余人的平均工资
#先筛选,再分组 where … group by 注意顺序
#先分组,再筛选 group by … having
select deptno,avg(sal) from emp where job != 'MANAGER' group by deptno;
#查询各部门职位为’CLEAK’的平均工资
#先筛选后分组
select deptno,avg(sal) from emp where job='CLERK' group by deptno;
#查询平均工资大于2000的部门
#先分组后筛选
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;
#查询每种工作的最高工资、最低工资、人数,并按照人数升序排列,若人数相同则按照最低工资降序排列
select job,max(sal) as '最高工资',min(sal) as '最低工资',count(*) as '人数'
from emp group by job order by '人数' asc,'最低工资' desc;
子查询
一个完整的SQL语句中 嵌套了另一个完整的SQL语句
#1.找出最高工资的员工信息
select max(sal) from emp; -- 查询最高工资
select * from emp where sal = (select max(sal) from emp);
#2.查询员工表中工资高于平均工资的员工信息
select avg(sal) from emp; -- 查询平均工资
select * from emp where sal > (select avg(sal) from emp);
#3.查询在班级class表里 'D215教室’上课的同学有哪些
#(1)查询在'D215教室'上课的班级有哪些
select class_id from class where address = 'D215教室';
select * from student where class_id = (select class_id from class where address = 'D215教室');
#4.查询数据库成绩不及格的同学的班级信息,包括班级名称和地址
#(1)数据库成绩不及格的同学的班级编号
select class_id from student where chinese_score < 60;
select * from class where class_id in (select distinct class_id from student where chinese_score < 60);
#5.查询最低工资大于30部门最低工资的部门编号deptno和其最低工资(先分组后筛选 group by… having)
#先查询30部门最低工资
select min(sal) from emp where deptno = 30;
select deptno, min(sal) from emp group by deptno having min(sal) > (select min(sal) from emp where deptno = 30);
#limit ? 写在所有的查询分组排序最后面,可以取指定的结果条数
#6.查询平均工资最低的部门的员工(分组)
#先查询平均工资最低的部门的部门编号,再根据部门编号去查底下的员工
select deptno from emp group by deptno order by avg(sal) asc limit 1;
select * from emp where deptno = (select deptno from emp group by deptno order by avg(sal) asc limit 1);
– 7.查询部门人数大于5的部门信息(先分组,后筛选,两张表做子查询)
#先查部门人数大于5的部门编号
select deptno from emp group by deptno having count(empno) > 5;
select * from dept where deptno = (select deptno from emp group by deptno having count(empno) > 5);
– 更新与子查询:
– 8.给平均薪资最低的部门的员工薪资增加200
#先查平均薪资最低的部门的员工
set sql_safe_updates=0;
update emp set sal = sal-400 where empno in (
select * from (
select empno from emp
where deptno = (select deptno from emp group by deptno order by avg(sal) asc limit 1)
) t
);
– 删除与子查询:
– 9.删除工资最低的员工信息
#先查工资最低的员工
select * from emp where sal = (select min(sal) from emp);
delete from emp where empno =
(select * from
(select empno from emp where sal = (select min(sal) from emp)) t
)
;
多表连接
表格之间的关系
#一对一 一个人person 对应 一条idcard(身份证号,出生日期)
#一对多 一个员工对应一个部门,一个部门有多个员工
多端添加一个外键约束,外键的名字和类型,与‘一端’的主键一致
#多对多 一个教师可以教多个学生, 一个学生可以听多个老师的课
多对多关系是两个一对多拼接在一起的
增加一个中间表,列包含两个,列名和类型分别与两个表格的主键一致
连接时,表1连接到中间表,通过中间表再连接到表2
#笛卡尔积
select * from emp,dept where emp.deptno = dept.dept_id;
外连接
#语法:select 列名 from 表1 left/right join 表2 on 连接条件
#以dept表为主表,分别做左连接和右连接
#左外连接:以左边的表为基准,左表数据全部查询,右表无对应数据则补null
select * from dept left join emp on emp.deptno = dept.dept_id;
#右外连接:以右边的表为基准,右表的数据全部查询,左边的表无对应数据则补null
select * from emp right join dept on emp.deptno = dept.dept_id;
left和right来控制以哪一个表格的数据作为基准
作为基准的表格数据必须全部显示出来
非基准的表格按照on条件与之拼接
若找到条件拼接 则正常显示 若找不到满足条件的则 null
#例:以emp表为主表,做左连接,起别名
select e.empno,e.ename,e.job,e.deptno,d.dept_name
from emp e left join dept d on e.deptno = d.dept_id;
内连接
取两个表格的可对应的数据(取交集),无法在连接的表找到对应的数据的记录不会被查出来
#语法:select 列名 from 表1 inner join 表2 on 连接条件
select * from emp e inner join dept d on e.deptno = d.dept_id;
#内连接练习题:
#1.emp显示部门号为 10 的部门名,员工名和工资
select dept.dept_name,emp.ename,emp.sal
from emp inner join dept on emp.deptno = dept.dept_id
where emp.deptno = 10;
#2.显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号–empno)
select e1.empno,e1.ename from emp e1
inner join emp e2 on e1.empno = e2.mgr
where e2.ename = 'FORD';
视图
视图本身是可以被创建和修改的,但视图里的数据是不可以被增加、删除和更改的,只能被查询
查询视图时与查询表格的使用方式基本一致
创建视图
#语法:create [or replace] view 视图名称 as (查询语句)
create or replace view v1 as
(select c.*,a.aid,a.aname,city.cityid,city.cityname,city.citysize from Country c
inner join Area a on a.cid = c.cid
inner join City on a.aid = city.aid)
;
#查询视图
select * from v1;
#查看视图基本信息
#语法:DESC 视图名
desc v1;
#修改视图本身
#语法:create or replace view 视图名称 as (查询语句)
#删除视图
#语法:drop view 视图名称;
drop view v1;
函数
| 函数名 | 作用 | 举例 |
|---|---|---|
| abs() | 求绝对值 | select sname,abs(chinese_score) from student; |
| mod(参数1,参数2) | 求余数 | 第一个参数是传进去的数值,第二个参数是要除以多少,结果得到参数1除以参数2的余数 --求学生的成绩除以2的余数:select sname,mod(chinese_score,2) from student; |
| floor(参数) | 求小于参数的最大正整数 | 求小于学生成绩的最大正整数:select sname,floor(chinese_score) from student; |
| rand() | 随机产生一个0~1的小数 | 随机产生一个两位正整数:select TRUNCATE(rand()*100,2) from dual; |
| round(参数1) 或 round(参数1,参数2) | 四舍五入 | 参数1是传进去要计算的值,参数2是指定保留多少位小数 --将学生成绩四舍五入:select sname,round(chinese_score) from student; --将学生成绩四舍五入,并保留一位小数:select sname,round(chinese_score,1) from student; |
| 以下是字符串函数 | ||
| length() | 求字符串的长度 | select length('abcdefgtrsgawaergtfbr') from dual; |
| concat(参数1,参数2) | 字符串拼接 | 例:把学生的姓名拼接为一行用逗号分隔:select concat(concat(sid,','),sname) from student;或select concat_ws(',',sid,sname) from student; |
| replace(参数1,参数2,参数3) | 替换字符串 | #参数1是需要替换的字符串 ,参数2是将要被替换的字符,参数3是替换后的字符 :select replace(sname, '张','李') from student; |
| substring(参数1,参数2,参数3) | 截取字符串 | 参数1是字符串,参数2是从第几位开始截取,参数3是截取多长:select substring('aehfawfewrhuiiudearfhu',3,5); |
| left(参数1,参数2) | 从左边开始截取字符串 | 参数1是字符串,参数2是从左边开始数截取多长:select left('aehfawfewrhuiiudearfhu',3); |
| right(参数1,参数2) | 从右边开始截取字符串 | 参数1是字符串,参数2是从右边开始数截取多长select right('aehfawfewrhuiiudearfhu',3); |
| locate(参数1,参数2) | 查找指定字符串在整个字符串里面的位置 | 参数1是要查找的字符串,参数2是被查找的字符串:查找'e'字符串在'abcdefg'里的第几位:select locate('e','abcdefg'); |
| 以下是日期函数 | ||
| date_format(参数1,参数2) | 日期格式化 | 参数1是被格式化的时间,参数2是要格式化的样式:select date_format('2024/11/12 17:02:38','%Y-%m-%d'); |
| CURDATE() | 获取当前日期- | 年月日 select CURDATE(); |
| CURTIME() | 获取当前时间 | 时分秒 |
| NOW() | 获取当前日期和时间 | 年月日 时分秒 |
| year(参数) | 获取参数时间的年份 | 参数是时间 |
| month(参数) | 获取参数时间的月份1-12 | 参数是时间 |
| day(参数) | 获取参数时间的月里面的天1-31 | 参数是时间;select year('2024-11-12 17:02:38'),month('2024-11-12 17:02:38'),day('2024-11-12 17:02:38'),hour('2024-11-12 17:02:38'),minute('2024-11-12 17:02:38') ; |
创建自定义函数
语法:
create function 函数名(参数) returns 返回类型
begin
.....
return 返回值;
end;
删除自定义函数
语法:
drop function 函数名;
存储过程
创建存储过程
语法:
create procedure 过程名()
begin
......
end;
例如:
查看员工与部门表中的全部信息
create procedure dept_emp()
begin
select * from dept;
select * from emp;
end;
定义变量
语法:
declare 变量名 变量类型 default 默认值; #声明变量
set 变量名=值; #变量赋值
select 字段名 into 变量名 from 数据库表; #查询表中字段,完成变量赋值
select 变量名; #显示变量
例如:查看员工表中empno=7369的员工姓名
create procedure emp_name()
begin
declare name varchar(20) default '';
select ename into name from emp where empno=7369;
select name;
end;
call emp_name();
存储过程参数
in:传入参数
out:传出参数
inout:可以传入也可以传出,如果既需要传入,同时又需要传出,则可以使用INOUT类型参数
create procedure 过程名([IN|OUT|INOUT] 参数名 参数数据类型 )
begin
......
end;
例如:传入员工的编号,查询对应的员工姓名
#创建存储过程
delimiter //
create procedure emp_name(in eno int)
begin
declare empname varchar(20) default '';
select ename into empname from emp where empno=eno;
select empname;
end;
//
#调用
call emp_name(7900);
例如:
根据传入的eno,返回员工的empno和姓名
create procedure emp_no_procedure(inout eno int,out ename varchar(20))
begin
select empno,ename into empno,ename from emp where empno=eno;
end;
set @eid=3;
set @ename='';
call emp_no_procedure(@eno,@ename);
select @eid,@ename;
删除存储过程
drop procedure 存储过程名;
例如:
drop procedure emp_no_procedure;
触发器
MySQL触发器是一种特殊的存储过程,它会在INSERT、UPDATE或DELETE等数据库操作执行时自动触发执行。触发器可以用于保持数据的完整性,自动更新或计算字段值,同步表数据等。
创建触发器
语法:
CREATE TRIGGER 触发器名称
BEFORE | AFTER trigger_EVENT
ON 触发器关联的表名 FOR EACH ROW 触发器被激活时执行的SQL语句
- BEFORE 或 AFTER 指定触发器是在操作之前还是之后触发。
- trigger_EVENT 可以是INSERT、UPDATE或DELETE。
- FOR EACH ROW 表示触发器会对每一行数据的操作进行响应。
注意:
- 不能创建具有相同名字的触发器。
- 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发器(比如after insert插入之后有一个触发器那么就不能再有触发器是after的了,但是before insert是可以的)。
执行语句中如果要引用更新记录中的字段,对于INSERT语句,只有NEW是合法的,表示当前已插入的记录;对于DELETE语句,只有OLD才合法,表示当前删除的记录;而UPDATE语句可以和NEW(更新后)以及OLD(更新前)同时使用。
创建一个insert事件触发器
例如,如果想在student表中插入数据后,自动更新class表中的人数,可以创建如下触发器:
CREATE TRIGGER tri_insert_student AFTER INSERT
ON student FOR EACH ROW
UPDATE class SET count = count + 1 WHERE class.id = NEW.class_id;
# AFTER INSERT 表示在插入操作之后触发,NEW.class_id 表示新插入行的class_id字段
创建一个delete 事件触发器
create trigger tri_delete_student after delete
on student for each row update class set count=count-1 where old.class_id=class.id;
查看触发器
查看已存在的触发器可以使用SHOW TRIGGERS语句,或者查information_schema数据库中的triggers表:
SHOW TRIGGERS;
或者
SELECT * FROM information_schema.triggers WHERE trigger_name = 'tri_insert_student';
删除触发器
删除触发器的语法如下:
DROP TRIGGER IF EXISTS 触发器名称;
#这里,IF EXISTS 是可选的,用于避免删除不存在的触发器时产生错误。
create database test;
#选中数据库
use test;
#班级表
create table class(
class_id int(2) primary key comment'班级编号',
class_name varchar(20) comment'班级名称',
address varchar(30) comment '班级地址',
count int comment '班级人数'
);
INSERT INTO `class` (`class_id`, `class_name`, `address`) VALUES ('1', '1班', 'F219教室');
INSERT INTO `class` (`class_id`, `class_name`, `address`) VALUES ('2', '2班', 'D215教室');
INSERT INTO `class` (`class_id`, `class_name`, `address`) VALUES ('3', '3班', 'F307教室');
create table student(
sId varchar(16) primary key comment '学生编号',
sname varchar(20) comment '学生姓名',
sage int(3) comment '年龄',
ssex char(2) comment '性别',
class_id varchar(20) comment '班级',
chinese_score float(5,2) comment '数据库成绩'
) charset=utf8mb4;
insert into student values (
'1001', '赵一', 17, '男', '1', 90.00),('1002', '钱二', 18, '女', '2', 88.00),
('1003', '张三', 23, '男', '3', 59.00),('1004', '李四', 20, '男', '3', 70.00),
('1005', '王五', 19, '男', '2', 56.00),('1006', '赵六', 16, '女', '2', 80.00),
('1007', '周七', 17, '女', '2', 85.00),('1008', '吴八', 21, '男', '1', 60.00),
('1009', '郑九', 19, '男', '3', 76.00);
#新增数据时的触发器
CREATE TRIGGER tri_insert_student AFTER INSERT
ON student FOR EACH ROW
UPDATE class SET count = count + 1 WHERE class.class_id = NEW.class_id;
#删除数据时的触发器
create trigger tri_delete_student after delete
on student for each row
update class set count=count-1 where old.class_id=class.class_id;
#查看所有触发器
SHOW TRIGGERS;
创建一个update事件触发器
例:创建一个触发器,当班级class表中的class_id修改时,学生student表里的class_id也随之更新
CREATE TRIGGER tri_update_classid AFTER UPDATE
ON class FOR EACH ROW
UPDATE student SET student.class_id= NEW.class_id
WHERE student.class_id = OLD.class_id;
索引
- MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能。
- 建立索引可以大大提高 MySQL 的检索速度,尤其是在大型表中进行搜索时。通过使用索引,MySQL
可以直接定位到满足查询条件的数据行,而无需逐行扫描整个表。
但是:
- 索引需要占用额外的存储空间。
- 对表进行插入、更新和删除操作时,索引需要维护,可能会影响性能。
应该建立索引的列:
- 在经常需要搜索的列上,可以加快搜索的速度
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度
- 在经常用在连接(JOIN)的列上,这些列主要是外键,可以加快连接的速度
- 在经常需要排序(order by)的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
创建索引
创建表时直接指定索引
CREATE TABLE table_name (
ID INT NOT NULL,
列名2 数据类型(长度) NOT NULL,
INDEX 索引名称 (列名)
);
索引分类(按功能划分):
主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL
ALTER TABLE 表格名字 ADD PRIMARY KEY(列名);
唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
CREATE UNIQUE INDEX 索引名称 ON 表格名字(列名);
#或者
ALTER TABLE 表格名字 ADD UNIQUE (列名);
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入
CREATE INDEX 索引名字 ON 表格名字(列名);
#或者
ALTER TABLE 表格名字 ADD INDEX 索引名字(列名);
组合索引
-- 创建普通组合索引
CREATE INDEX 索引名称 ON 表格名字(列1,列2);
-- 创建唯一组合索引
CREATE UNIQUE INDEX 索引名称 ON 表格名字(列1,列2);
索引名称 是可以省略的,省略后,索引的名称和索引列名相同。
删除索引
-- 直接删除索引
DROP INDEX 索引名称 ON 表格名字;
-- 修改表结构删除索引
ALTER TABLE 表格名字 DROP INDEX 索引名称;
查看索引
查看索引信息(包括索引结构等)
show index from 表格名字;
事务
什么是事务?
数据库中的事务是指对数据库执行一批操作,在同一个事务当中,这些操作最终要么全部执行成功,要么全部失败,不会存在部分成功的情况。
事务是一个原子操作。是一个最小执行单元。可以甶一个或多个SQL语句组成
在同一个事务当中,所有的SQL语句都成功执行时,整 个事务成功,有一个SQL语句执行失败,整个事务都执行失败。
举个例子:
比如A用户给B用户转账100操作,过程如下:
从A账户扣100
给B账户加100
如果在事务的支持下,上面最终只有2种结果:
操作成功:A账户减少100;B账户增加100
操作失败:A、B两个账户都没有发生变化
如果没有事务的支持,可能出现错:A账户减少了100,此时系统挂了,导致B账户没有加上100,而A账户凭空少了100。
事务是作为并发控制的最小控制单元,具备以下ACID四个特性:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
原子性(Atomicity)
事务的整个过程如原子操作一样,最终要么全部成功,或者全部失败,这个原子性是从最终结果来看的,从最终结果来看这个过程是不可分割的。
一致性(Consistency)
一个事务必须使数据库从一个一致性状态变换到另一个一致性状态。
所谓一致性,指的是数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。最常见的例子是转帐。例如从帐户A转一笔钱到帐户B上,如果帐户A上的钱减少了,而帐户B上的钱却没有增加,那么我们认为此时数据处于不一致的状态。
从这段话的理解来看,所谓一致性,即,从实际的业务逻辑上来说,最终结果是对的、是跟开发人员的所期望的结果完全符合的
隔离性(Isolation)
一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
这里提一下事务的隔离级别:
- 读未提交:read uncommitted
- 读已提交:read committed
- 可重复读:repeatable read
- 串行化:serializable
从上到下隔离级别越来越强,会导致数据库的并发性也越来越低。
持久性(Durability)
一个事务一旦提交,他对数据库中数据的改变就应该是永久性的。当事务提交之后,数据会持久化到硬盘,修改是永久性的。
MySQL的事务操作
事务分为隐式事务和显式事务。
mysql中事务默认是隐式事务,执行insert、update、delete操作的时候,数据库自动开启事务、提交或回滚事务。
隐式事务
事务自动开启、提交或回滚,比如insert、update、delete语句,事务的开启、提交或回滚由mysql内部自动控制的。
查看MySQL是否开启了自动提交:
show variables like 'autocommit';
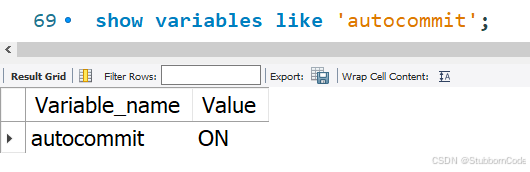
autocommit为ON表示开启了自动提交。
显式事务
事务需要手动开启、提交或回滚,由开发者自己控制。
第一种写法:
//设置不自动提交事务
set autocommit=0;
//执行事务操作
commit;//提交
rollback;//回滚
//还原回去
set autocommit=1;
第二种方式:
start transaction;//开启事务
//执行事务操作
commit;//提交
rollback;//回滚
更多深入的内容可以跳转查看这位博主的文章:MySQL事务详解
用户与权限
创建用户
语法:
CREATE USER '用户名'@'主机IP' IDENTIFIED BY '密码';
- 主机IP:指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符
% - 密码:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
例如:
CREATE USER 'user1'@'localhost' IDENTIFIED BY '123456';
CREATE USER 'user2'@'192.168.1.101' IDENDIFIED BY '123456';
CREATE USER 'user3'@'%' IDENTIFIED BY '123456';
CREATE USER 'user4'@'%' IDENTIFIED BY '';
CREATE USER 'user5'@'%';
授权
语法:
GRANT 操作权限 ON 数据库名称.表格名 TO '用户名'@'localhost'
- 操作权限:用户的操作权限,如
SELECT,INSERT,UPDATE等,如果要授予所的权限则使用ALL - 如果要授予该用户对所有数据库和表的相应操作权限则可用
*表示,如*.*
例如:
GRANT SELECT, INSERT ON test.user TO 'user1'@'localhost';
GRANT ALL ON *.* TO 'user5'@'%';
GRANT ALL ON test.* TO 'user3'@'%';
注意:
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
GRANT privileges ON 数据库名称.表格名 TO '用户名'@'localhost' WITH GRANT OPTION;
设置与更改密码
语法:
alter user 用户名@主机地址 identified by '新密码';
例如:
alter user user1@localhost identified by '111111';
撤销用户权限
语法:
REVOKE 权限 ON 数据库名称.表格名 FROM '用户名'@'localhost';
删除用户
DROP USER '用户名'@'localhost';
查看当前数据库服务器上的所有用户信息:
SELECT user, host FROM mysql.user;
E-R图
在数据库设计中我们会使用到E-R图(Entity Relationship Diagram)
ER图分为实体、属性、关系三个核心部分。实体之间通过线连接,并在连接线上标明它们之间的基数关系,如1:1、1:n或n:m等。
- 矩形:表示实体
- 椭圆形:表示字段
- 主键:在字段上使用下划线
- 菱形:外键约束;实体之间的关系
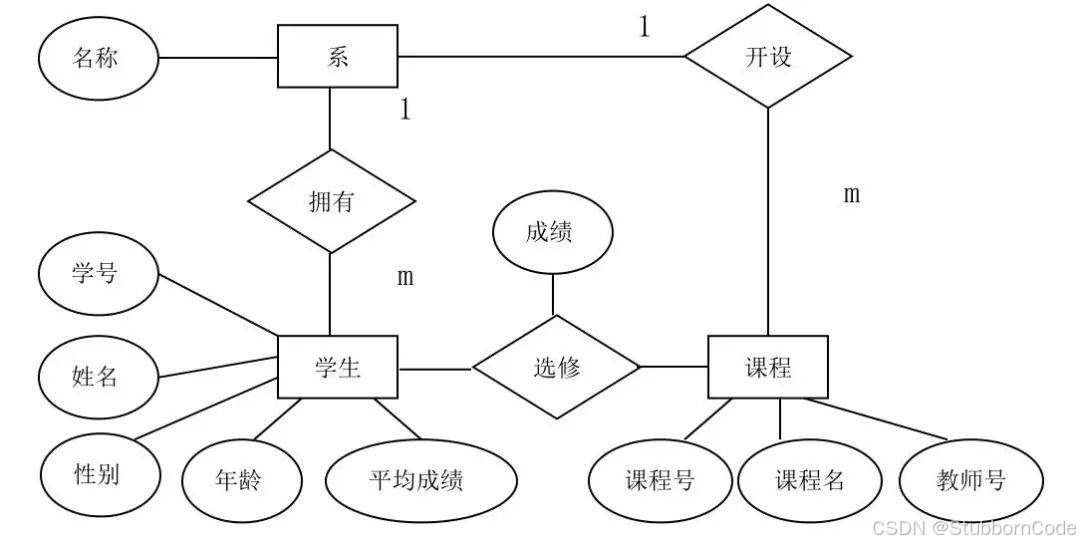
实体(entity)
一般认为,客观上可以相互区分的事物就是实体,实体可以是具体的人和物,也可以是抽象的概念与联系。
例如人、学生、课程 都可以作为一个数据对象,用长方体来表示,每个实体都有自己的实体成员(entity member)或者说实体对象(entity instance),例如学生实体里包括张三、李四等,实体成员(entity member)/实体实例(entity instance) 不需要出现在ER图中。
属性(attribute)
即数据对象所具有的属性。
实体所具有的某一特性,一个实体可由若干个属性来刻画。属性不能脱离实体,属性是相对实体而言的。
例如学生具有姓名、学号、年级等属性,用椭圆形表示,属性分为唯一属性( unique attribute)和非唯一属性,唯一属性指的是唯一可用来标识该实体实例或者成员的属性,用下划线表示,一般来讲实体都至少有一个唯一属性。
关系(relationship)
用来表现数据对象与数据对象之间的联系。
实体内部的联系通常是指组成实体的各属性之间的联系;实体之间的联系通常是指不同实体集之间的联系。
例如学生的实体和成绩表的实体之间有一定的联系,每个学生都有自己的成绩表,这就是一种关系,关系用菱形来表示。
ER图中关联关系有三种:
- 1对1(1:1)
- 1对多(1:N)
- 多对多(M:N)
范式
设计数据库的时候需要遵从的一些规范,目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
正常情况下满足前三个范式就可以设计一个比较规范的数据库。
要遵循后边的范式,就必须先遵循前面的范式要求,比如第二范式就必须先遵循第一范式的,第三范式必须先遵循第二范式,以此类推
- 第一范式(1NF):每个列都不可以再拆分。
- 第二范式(2NF):在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
- 第三范式(3NF):在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
例如:
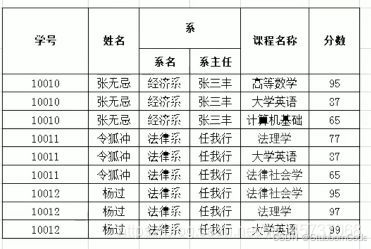
进行第一范式的改造

在第一范式转变为第二范式前,先了解几个概念:
- 函数依赖:如果通过A属性(属性组),可以确定唯一B属性的值,那么B依赖于A。比如上图的姓名,完全依赖于学号
- 完全函数依赖:如果A是一个属性组,则B属性值的确定需要依赖于A属性组中的所有的属性值。属性组是指多个字段,那么比如我们要想知道一个分数,就必须依赖于学号和课程名称两个属性才能确定一个分数,其他的属性是不能确定某一个分数的
- 部分函数依赖:如果A是一个属性组,则B属性值的确定需要依赖A属性组的某一些字段即可,例如学号和课程名称为一个属性组,那么学生姓名其实就只需要学号就可以确定
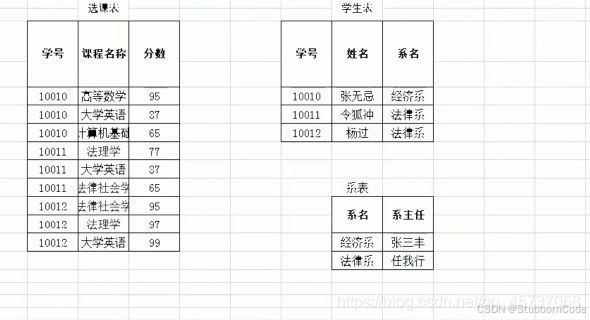
- 传递函数依赖:如果A属性(属性组),可以确定唯一个B属性的值,再通过B属性的值又可以唯一确定C属性的值,例如一个学号确定一个系名,一个系名对应一个系主任
- 主键:在一张表中,一个属性或者属性组,被其他所有属性完全依赖,则称这个属性为该码的表,比如上图的学号和课程名称组成的属性组
1NF->2NF需要在第一范式的基础上消除非主键列对主键列的部分依赖,进行第二范式的改造后:
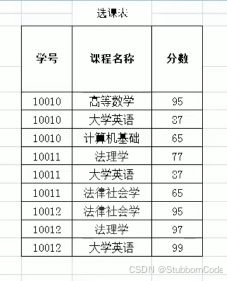
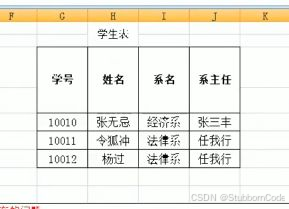
2NF->3NF需要在第二范式的基础上消除非主键列的传递函数依赖,进行第三范式的改造后:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









