







上面对什么是数据切分做了个概要的描述和解释,读者可能会疑问,为什么需要数据切分呢?像 Oracle这样成熟稳定的数据库,足以支撑海量数据的存储与查询了?为什么还需要数据切片呢?
的确,Oracle的DB确实很成熟很稳定,但是高昂的使用费用和高端的硬件支撑不是每一个公司能支付的起的。试想一下一年几千万的使用费用和动辄上千万元的小型机作为硬件支撑,这是一般公司能支付的起的吗?即使就是能支付的起,假如有更好的方案,有更廉价且水平扩展性能更好的方案,我们为什么不选择呢?
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是横向扩展,通过添加更多的机器来共同承担压力。我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?Sharding可以轻松的将计算,存储,I/O并行分发到多台机器上,这样可以充分利用多台机器各种处理能力,同时可以避免单点失败,提供系统的可用性,进行很好的错误隔离。
综合以上因素,数据切分是很有必要的。 我们用免费的MySQL和廉价的Server甚至是PC做集群,达到小型机+大型商业DB的效果,减少大量的资金投入,降低运营成本,何乐而不为呢?所以,我们选择Sharding,拥抱Sharding。
一、范围分区
user_id为1~1000的对应DB1,1001~2000的对应DB2,以此类推;
优点:可部分迁移
缺点:数据分布不均
二、hash分区
1、hash取模
假设有一张记录用户购买信息的订单表order,由于order表记录条数太多,将被拆分成256张表。拆分的记录根据user_id%256取得对应的表进行存储,前台应用则根据对应的user_id%256,找到对应订单存储的表进行访问。

在缓存服务器采用这种策略,当出现下面的情况
1 、一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 、由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。虽然更改了规则,但是现存的数据都是根据之前的规则存放的,现有的规则无法找到之前的数据,导致流量直接访问服务器。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
遇到节点增删的问题,基本就是停止服务,将数据重新分布,然后更改规则,数据的导入会消耗很长的时间,极大的延长服务不可用。
2、一致性hash
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - 232-1(即哈希值是一个32位无符号整形)。
下面简单举个例子来说明一致性hash。
准备:1、2、3 三台机器
还有待分配的9个数 1、2、3、4、5、6、7、8、9
一致性hash算法架构
步骤
一、构造出来 2的32次方 个虚拟节点出来,因为计算机里面是01的世界,进行划分时采用2的次方数据容易分配均衡。另 2的32次方是42亿,我们就算有超大量的服务器也不可能超过42亿台吧,扩展和均衡性都保证了。

二、将三台机器分别取IP进行hashcode计算(这里也可以取hostname,只要能够唯一区别各个机器就可以了),然后映射到2的32次方上去。比如1号机器算出来的hashcode并且mod (2^32)为 123(这个是虚构的),2号机器算出来的值为 2300420,3号机器算出来为 90203920。这样三台机器就映射到了这个虚拟的42亿环形结构的节点上了。
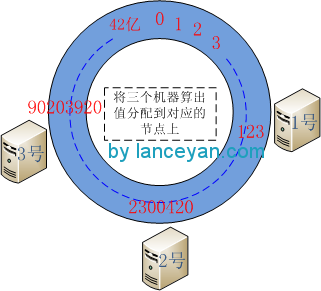
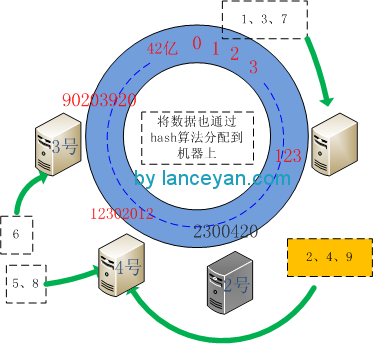
三、将数据(1-9)也用同样的方法算出hashcode并对42亿取模将其配置到环形节点上。假设这几个节点算出来的值为 1:10,2:23564,3:57,4:6984,5:5689632,6:86546845,7:122,8:3300689,9:135468。可以看出 1、3、7小于123, 2、4、9 小于 2300420 大于 123, 5、6、8 大于 2300420 小于90203920。从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个Cache节点上。如果超过2^32仍然找不到Cache节点,就会保存到第一个Cache节点上。也就是1、3、7将分配到1号机器,2、4、9将分配到2号机器,5、6、8将分配到3号机器。

这个时候大家可能会问,我到现在没有看见一致性hash带来任何好处,比传统的取模还增加了复杂度。现在马上来做一些关键性的处理,比如我们增加一台机器。按照原来我们需要把所有的数据重新分配到四台机器。一致性hash怎么做呢?现在4号机器加进来,他的hash值算出来取模后是12302012。 5、8 大于2300420 小于12302012 ,6 大于 12302012 小于90203920 。这样调整的只是把5、8从3号机器删除,4号机器中加入 5、6。

同理,删除机器怎么做呢,假设2号机器挂掉,受影响的也只是2号机器上的数据被迁移到离它节点,上图为4号机器。
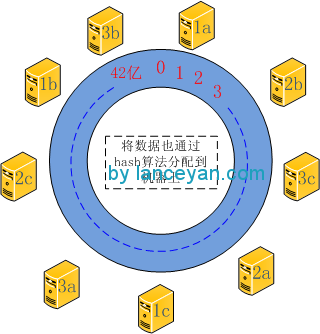
大家应该明白一致性hash的基本原理了吧。不过这种算法还是有缺陷,比如在机器节点比较少、数据量大的时候,数据的分布可能不是很均衡,就会导致其中一台服务器的数据比其他机器多很多。为了解决这个问题,需要引入虚拟服务器节点的机制。如我们一共有只有三台机器,1、2、3。但是实际又不可能有这么多机器怎么解决呢?把 这些机器各自虚拟化出来3台机器,也就是 1a 1b 1c 2a 2b 2c 3a 3b 3c,这样就变成了9台机器。实际 1a 1b 1c 还是对应1。但是实际分布到环形节点就变成了9台机器。数据分布也就能够更分散一点。如图:
遇到节点增删的问题,停止服务,计算节点增删后哪些数据被影响,然后迁移被影响的数据,更改规则,数据的迁移时间会比一短很多,一段时间服务不可用。
由于一致性hash主要解决了节点增删的问题,所以主要运用在分库中,如果只是库内分表,一致性hash就没有用武之地了。对于分库分表,分库可以做一致性hash,分表可以hash取模,结合使用。
三、表存放数据规则
就是建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
优点:灵活性强,一对一关系
缺点:每次查询之前都要多一次查询,性能大打折扣















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









