







序列的本质和内存结构
序列是一种数据存储方式,在内存中,序列就是一块用来存放多个值的连续的内存空间。列表、元组、字典、集合都属于序列。
列表特点:
(1)存储任意数目、任意类型的数据。
(2)是内置可变序列。
如下整数序列[10,20,30,40]的内存示意图:
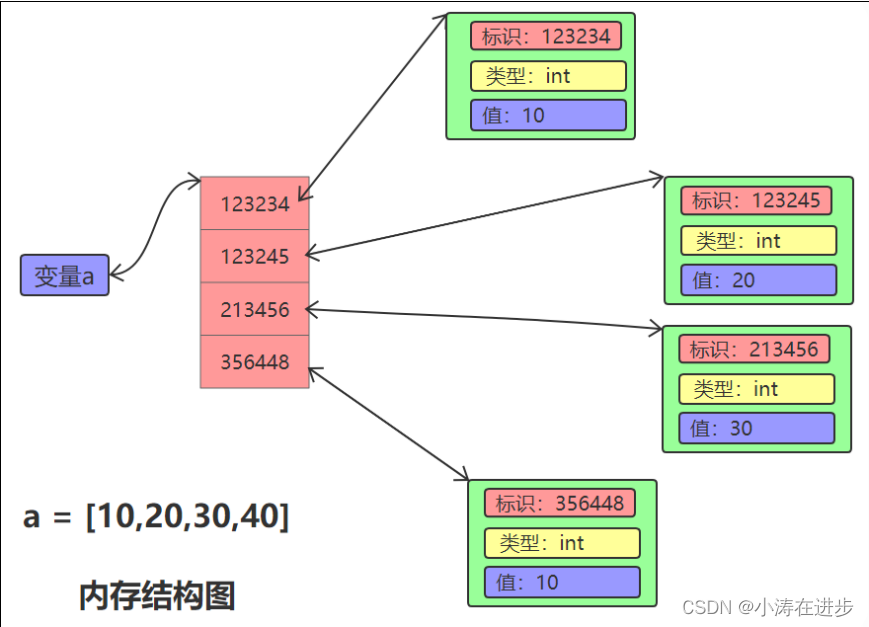
列表创建的四种方式:
# 基本语法 [] 创建
a = [10,20,30,40]
# list()创建
b =list("10,20")
# range()创建整数列表,语法格式range([start,] end [,step])
c = list(range(3,10,2))
# 推导式生成列表
d = [x*2 for x in range(5)]
print(a)
print(b)
print(c)
print(d)
执行结果:
[10, 20, 30, 40]
['1', '0', ',', '2', '0']
[3, 5, 7, 9]
[0, 2, 4, 6, 8]
列表元素的增加
列表添加有5中方式:
(1)append();(2)extend();(3)insert();(4)+尾部添加新元素;(5)乘法扩展,生成新列表
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。所以我们尽量在尾部添加删除元素。
(1)append()方法,原地修改列表对象,是真正的列表尾部添加新的元素,速度最快
a = [10,20,30,40]
a.append(50)
print(a)
执行结果:
[10, 20, 30, 40, 50]
(2)extend()方法,将目标列表的所有元素添加到本列表尾部,属于原地操作,不创建新的列表对象。
a = [20,40]
print(id(a))
b = [50,60]
a.extend(b) #原对象修改
print(a)
print(id(a))
执行结果:
1808659894976
[20, 40, 50, 60]
1808659894976
(3)insert() 方法,可以将指定的元素插入到列表对象的任意制定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。
a = [10,20,30]
a.insert(2,100)
print(a)
执行结果:
[10, 20, 100, 30]
(4)+运算符操作,并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。
a = [20,40]
print(id(a))
a = a+[50]
print(a)
print(id(a))
执行结果:
1395859837632
[20, 40, 50]
1395860409152
(5)乘法扩展,使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复。
a = ['sxt',100]
b = a*3
print(a)
print(b)
执行结果:
['sxt', 100]
['sxt', 100, 'sxt', 100, 'sxt', 100]
列表元素的删除
(1)del 删除,删除列表指定位置的元素。
a = [100,200,888,300,400]
del a[2]
print(a) #结果[100, 200, 300, 400]
(2)pop()方法,)删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
a = [10,20,30,40,50]
b1 = a.pop()
print(a,b1) #结果:[10, 20, 30, 40] 50
b2 = a.pop(1)
print(a,b2) #结果:[10, 30, 40],20
(3)remove()方法,删除首次出现的指定元素,若不存在该元素抛出异常。
a = [10,20,30,40,50,20,30,20,30]
a.remove(20)
print(a) #结果:[10, 30, 40, 50, 20, 30, 20,30]
列表元素访问
index()获得指定元素在列表中首次出现的索引,语法是: index(value,[start, [end]]) 。其中, start和end指定了搜索的范围。
a = [10,20,30,40,50,20,30,20,30]
a.index(20) #结果:1
a.index(20,3) #结果:5 从索引位置3开始往后搜索的第一个20
a.index(30,5,7)#结果:6 从索引位置5到7这个区间,第一次出现30元素的位置
切片操作
切片是Python序列及其重要的操作,适用于列表、元组、字符串等。标准格式为:
[起始偏移量start:终止偏移量end[:步长step]]
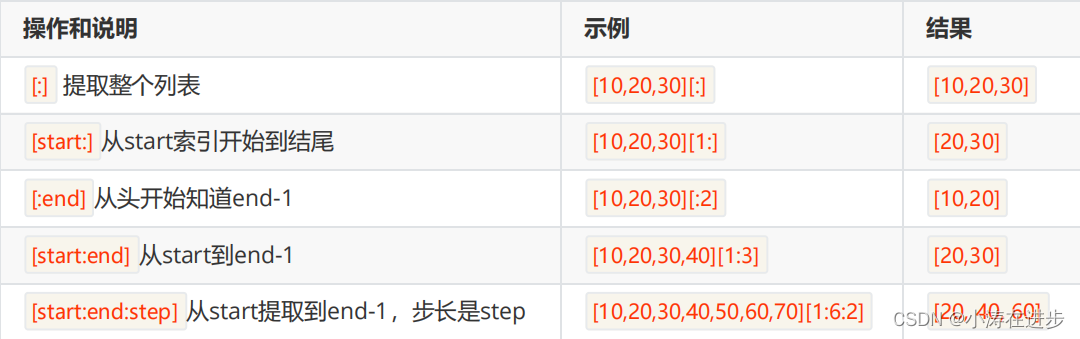
列表排序
sort()修改原列表,不建新列表的排序
a = [20,10,30,40]
print(id(a)) #结果:2383597064896
a.sort()
print(a) #结果:[10, 20, 30, 40]
print(id(a)) #结果:2383597064896
a.sort(reverse=True)
print(a) #结果:[40, 30, 20, 10]
sorted()返回新列表,不对原列表做修改。
a = [20,10,30,40]
print(id(a)) #结果:1540924953280
b = sorted(a)
print(b) #结果:[10, 20, 30, 40]
print(id(b)) #结果:1540925210752
b = sorted(b,reverse=True)
print(b) #结果:[40, 30, 20, 10]
print(id(b)) #结果:2130897653952
reversed()返回迭代器
a = [20,10,30,40]
b = reversed(a)
print(b) #结果:<list_reverseiterator object at 0x0000024E876BE710>
print(list(b)) #结果:[40, 30, 10, 20]
二维列表
姓名 年龄 薪资 城市
高小一 18 30000 北京
高小二 19 20000 上海
高小五 20 10000 深圳
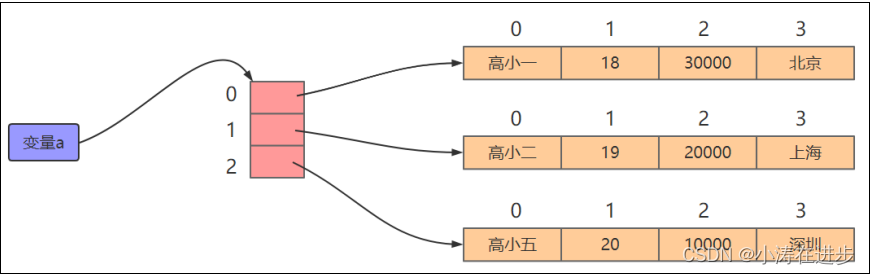
嵌套循环打印二维列表所有的数据
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小五",20,10000,"深圳"],
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print()#打印完一行,换行
执行结果:
高小一 18 30000 北京
高小二 19 20000 上海
高小五 20 10000 深圳















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









