










-
采样:按比例采集样本,来平衡样本
-
GAN生成模型: 生成虚拟数据 来平衡扩大样本
-
迁移学习: 利用之前在别的数据集上训练好的模型参数 在自己的任务上fine-tuning
-
选择合适的loss函数:对类别比例小的样本给更大的权重系数,对类别比例大的样本给更小的权重系数,通过这种方式可以在一定程度上解决正负样本不均衡的问题。
-
合适的模型
采样
缺点:如果随机的复制多分正样本进行过采样,那么必然会导致过拟合,因为训练数据中的正样本会反复出现。这种做法不建议。
smote是一种合成采样的方法,它主要基于少数样本,计算样本空间之间的相似度,然后创建人工合成样本
因为欠采样会丢掉信息,所以可以通过Ensemble、Boosting的思想来进行欠采样。
多次下采样(放回采样,这样产生的训练集才相互独立)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果。
GAN生成模型

对于模型来说,希望的是预测加入扰动后的结果和真实的一致
数学实现:这里的q(y|xl) 为真实数据的预测,p(y|xl+radv,θ) 为加入扰动的预测,D是衡量的标准,这里可以是KL散度。 来评估扰动结果和真实结果的一致性
对抗训练的本质上就是让模型具有较强的鲁棒性,可以抵抗对抗样本的干扰,采用的方式就是生成这些数据,并且把这些数据加入到训练数据中。这样模型就会正视这些数据, 并且尽可能地拟合这些数据,最终完成了模型拟合,这些盲区也就覆盖住了。将对抗样本和原有数据一起进行训练,对抗样本产生的损失作为原损失的一部分, 即在不修改原模型结构的情况下增加模型的loss,产生正则化的效果。
虚拟对抗训练
VAT则是在对抗训练的基础上,提出了LDS(local distributional smoothness)。VAT提出的LDS也可以理解为在原有模型的基础上加上正则项,这个正则项可以实现局部分布平滑,VAT可以不仅仅适用于纯监督环境, 也适用于半监督训练。
总结一下VAT论文的优势:
对于模型来说,希望的是样本加入扰动后的预测结果和的样本未加入扰动的预测结果一致
半监督训练,无真实样本标签
无监督数据增强
内容:
扰动的样本x来源于非训练数据
缺点:
监督数据通常都是少量的。
基于Loss
代表:OHEM、Focal Loss 另外还有GHM、PISA等方法
OHEM算法的核心是选择一些难样本(多样性和高损失的样本)作为训练样本,针对性的改善模型学习效果。对于数据类别不平衡问题,OHEM的针对性更强。
Focal Loss的核心思想是在交叉熵的基础上增加了类别的不同权重以及困难样本的权重,以改善模型学习效果。https://blog.csdn.net/qq_42363032/article/details/121573416
合适的模型
如何选择,看实际效果
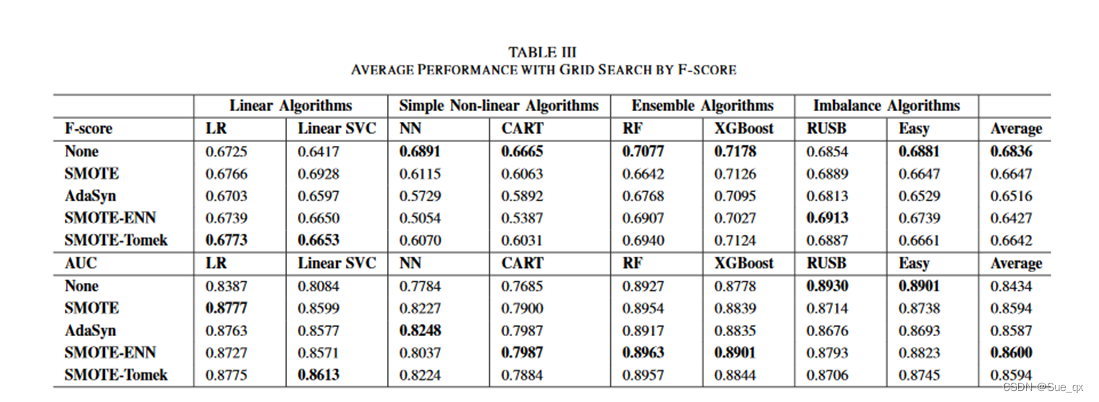
https://arxiv.org/pdf/2104.02240.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









