







介绍
- 在TSQL的应用中对于排序的用法有时会减少一些其他不必要的工作这里就总结三个最基本的用法。
RANK()函数排序
通过RANK可以将我们通常意义上的“班级排分”进行简化,排序过程直接交给数据库去做。
- 代码:
SELECT * '使用RANK函数进行排名' , RANK() OVER( '用ClassID进行分班' PARTITION BY ClassID '按照分数进行降序排列' ORDER BY Mark DESC) AS [Rank] FROM Student
到这里貌似和普通的ORDER BY 没啥区别,但是我们执行完了的结果是这样的
- 代码:
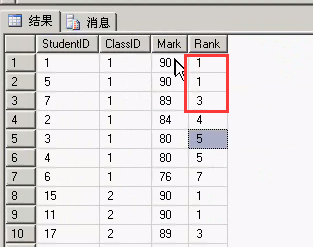
DENSE_RANK函数排序
同理,这个函数是对RANK的一个补充,如果我们需要不计人数的排序的话那么RANK就不能满足我们的要求了。
- 代码
SELECT * '使用DENSE_RANK()函数进行排序' ,DENSE_RANK() OVER( '按照班级分班' PARTITION BY ClassID '根据MARK进行降序排列' ORDER BY MARK DESC) AS [RANK] FROM Student
执行的结果如下:
- 代码
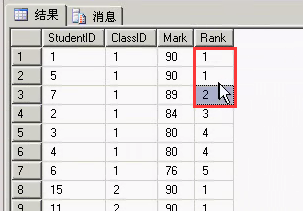
NTILE()函数进行分组
同样,如果我们需要对分数进行一个大概的分组的话(不是非常的准确)我们可以用NTILE()来宏观的观察一下数据的分组
- 代码如下:
SELECT * '括号中的2代表了只分两组' , NTILE(2) OVER ( ORDER BY Mark DESC) AS NewClass FROM Student
执行的结果如下:
- 代码如下:
如果我要想再分五组呢?只需要把括号中的2改成5即可。
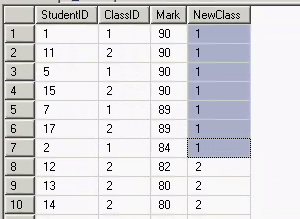
执行结果如下:
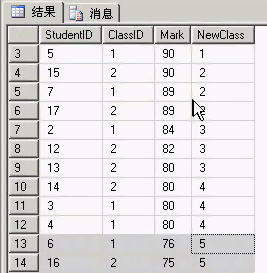
- 通过这个函数就可以知道老师对学生的分班工作原来是可以如此简单。
ROW_NUMBER()函数排序
简单的来讲,这个函数就是为每一条记录返回一个值,并标记这条数据,所以同样可以运用到对数据的排列整理当中。
- 代码如下:
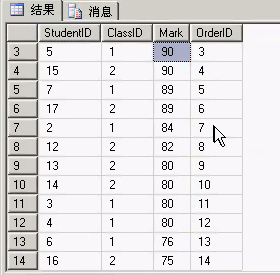
SELECT * ,ROW_NUMBER() OVER( ORDER BY Mark DESC) AS OrderID FORM Student '总体上的用法和之前的语法一样'
效果如下:
- 代码如下:
总结
- 通过对TSQL的排序用法的了解和技巧的运用,可以在存储过程中减少工作量,方便数据的存取。同时,最重要的一点就是大大的提高了对数据处理的效率,所以掌握他们非常重要。















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









