






工地视频监控ai分析盒子系统能设在安全出口外或办公区域,工地视频监控ai分析盒子依据视频监控自动识别不戴安全帽的人,并传出警示。工地视频监控ai分析盒子将警告信息推送到后台监控平台工作人员,与此同时截取图片作为凭证。工地视频监控ai分析盒子提升了作业区域的管理效率,保证了作业人员的安全。
在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(‘–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
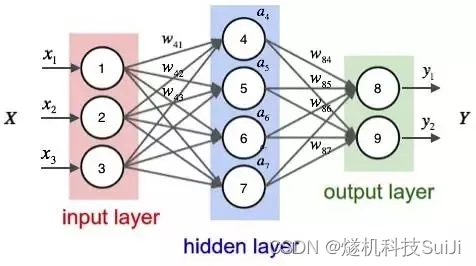
工地视频监控ai分析盒子借助最前沿的AI机器视觉算法,应用新的大数据,云技术,AI以在监控摄像头中实时监控现场视频流画面,可以用人工智能和物联网AI机器视觉算法对施工工地人员的工作着装及日常作业行为进行规范化管理,最大限度地降低作业过程中因为人员不规范行为引起的问题,借此完成现场安全生产的信息化管理。
针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。
# 检测类
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()工地视频监控ai分析盒子对佩戴安全帽的识别精度很高,除此之外还有反光衣穿戴识别检测、烟火识别、玩手机识别、抽烟检测、高空作业安全带识别检测、区域侵入等识别算法广泛应用于智慧校园、智慧建筑工地、智慧加油站、智慧煤矿、智慧港口、智慧园区、智慧电力、智慧工厂等场景。
















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









