







前面几期介绍了isnull()找缺失值,value_counts()统计字段内容的频次,但特征工程字段很多,一个个地看太麻烦了,能不能用for循环把方法封装起来 批量查看字段呢?
代码如下:
def exploreData(x):
for i in x.columns:
print("字段名:",i)
print("缺失值个数:",x[i].isnull().sum())
print("字段值与频数:")
print(x[i].value_counts())
print("-----------------------------------------------------------")代码讲解:
def后面是方法名,这里用驼峰命名法命名为exploreData,当然也可以依自己喜好命名为F(x)、fre(x)·····
columes表示列标签,是表示DataFrame的列标签的属性名,是内置的。表名.columes就能把一个二维表的列标签全打印出来了,如: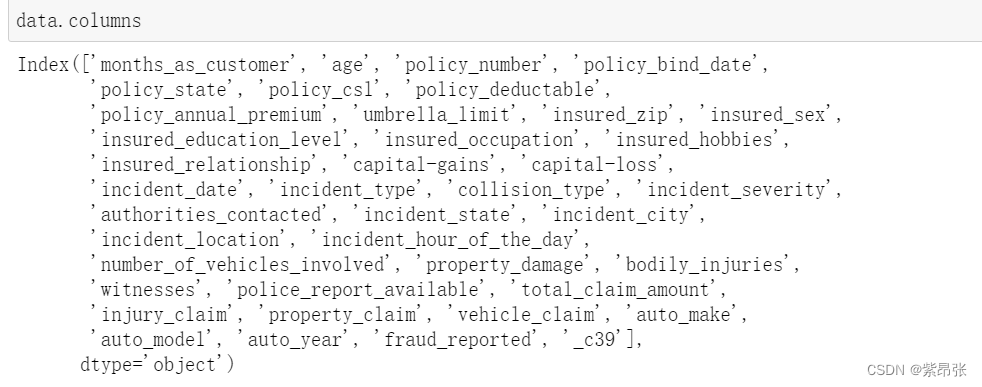
x是变量名其一,在这里表示数据集,也就是二维表DataFrame;
i是变量名其二,在这里表示数据集里面的字段。调用一个表里面的字段一般是这样写的:表名['字段名'],或者这样:表名.字段名。所以这里用两个变量来表示,就是这样:x[i];
for循环里面写 i in x.columes 就能把所有字段都遍历一遍;
用到的函数只有几个,一个isnull()和sum()的组合使用:先用isnull()把空值转为布尔值True,再用sum()把为1的加和起来;另一个是value_counts()计算每一个值出现的次数,也就是频数。
下面看运行结果:
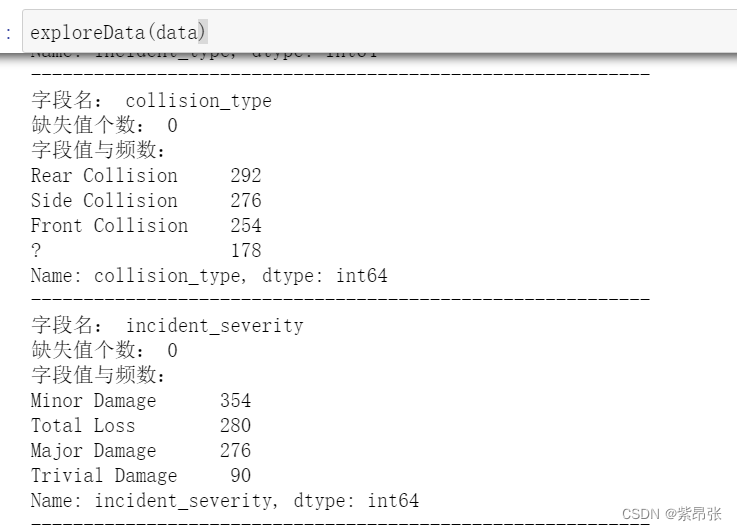
可以发现这份数据用问号?来表示空值了,我们需要记一下要处理的字段,对空值进一步处理。
















 2124
2124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









