







当特征有很多的时候,难免会出现一些相关性高的特征。可以自定义一个自动化的方法批量输出这些特征,方便我们进行下一步删除或者降维的处理。
def hight_corr(x):
data_corr = x.corr()>0.65
a=[]
for i in data_corr.columns:
if data_corr[i].sum()>=2:
a.append(i)
return a代码讲解:
data是数据集;
def hight_corr()是自定义的函数名;
x是自定义参数,用来表示数据集的;
data.corr()生成相关矩阵,data.corr()>0.65是条件判断会生成布尔值;
data_corr 用来保存生成的布尔值的矩阵;
data_corr[i]筛选相关矩阵其中一列,i是被定义的用来代表columns的参数;
data_corr[i].sum()对布尔值进行相加,强相关的值为为True,也就是1,强相关的字段会被sum()函数计数出来;
那为什么要判断大于等于2呢,因为在矩阵里,特征a与自身相关 本来就有一个1,当这个特征a与另外的特征b强相关的时候才会有第二个1;
append()指在数组后面追加元素,a是定义的数组,i是字段名;
这个段代码可以直接复制使用,然后把数据集放到函数里就可以啦:
hight_corr(data)运行结果:
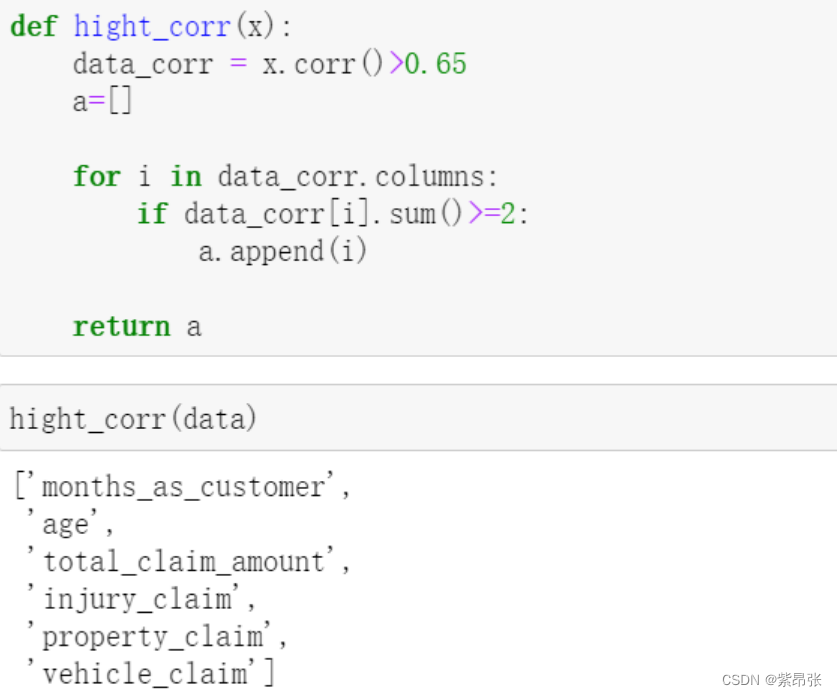
强相关性的字段就可以一键输出出来啦!
















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









