







第1章 Spark的设计与运行原理
简介
hadoop中计算框架MapReduce的缺点:
- 表能能力有限,计算都必须要转化成Map和Reduce两个操作,难以表示复杂场景
- IO开销大,中间结果写入到磁盘中,每次执行时都需要从磁盘读取数据
- 延迟高,IO读取耗时,同时任务串行进行,等待时间长
于是,引入了SPARK:
- 更多操作算子,计算模式虽然也属于MapReduce,但具备更多算子
- 内存计算,中间结果直接放到内存中,避免了从磁盘中频繁读取数据,带来了更高的迭代运算效率
- DAG的任务调度执行机制,要优于MapReduce的迭代执行机制
- 任务是基于线程的,相对MapReduce基于进程的方式更高效
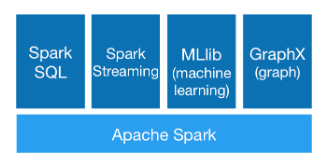
spark生态系统
运行架构
主从模式,硬件上:master-slave ,软件上:driver-executor
基本概念
- RDD:弹性分布式数据集(Resilient Distributed Dataset)的简称,是不可变的分布式对象集合,每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。本质上是一个只读的分区记录集合
- DAG : 有向无环图,描述RDD的血缘关系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









