










本文紧接上篇博客Hadoop+NFS+ZOOKEEPER实现高可用集群
Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者Yarn。Hadoop2.x也就是Yarn,分别用两个进程来管理这两个任务:
ResourceManger
ApplicationMaster
需要注意的是,在Yarn中我们把job的概念换成了application,因为在新的Hadoop2.x中,运行的应用不只是MapReduce了,还有可能是其它应用如一个DAG(有向无环图Directed Acyclic Graph,例如storm应用)。Yarn的另一个目标就是拓展Hadoop,使得它不仅仅可以支持MapReduce计算,还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理,也就是说,有了Yarn,各种应用就可以互不干扰的运行在同一个Hadoop系统中,共享整个集群资源。
本文实验环境和上文一致,是接上个实验(NFS+HDFS+ZOOKEEPER实现Hadoop集群高可用)来做的,话不多说了,开始!
1. 编辑配置 mapred-site.xml 文件
[hadoop@rhel65-lockey1 hadoop]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[hadoop@rhel65-lockey1 hadoop]$ vim etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定 yarn 为 MapReduce 的框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2. 编辑配置 yarn-site.xml 文件
[hadoop@rhel65-lockey1 hadoop]$ vim etc/hadoop/yarn-site.xml
<configuration>
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property><!-- 指定 RM 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.5.91</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.5.95</value>
</property>
<!-- 激活 RM 自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.5.92:2181,172.25.5.93:2181,172.25.5.94:2181</value>
</property>
</configuration>3. 服务测试
最好是把 RM 与 NN 分离运行,这样可以更好的保证程序的运行性能
首先在主机1上开启yarn
[hadoop@rhel65-lockey1 hadoop]$ sbin/start-yarn.sh
此时可以看到1上多了一个进程ResourceManager
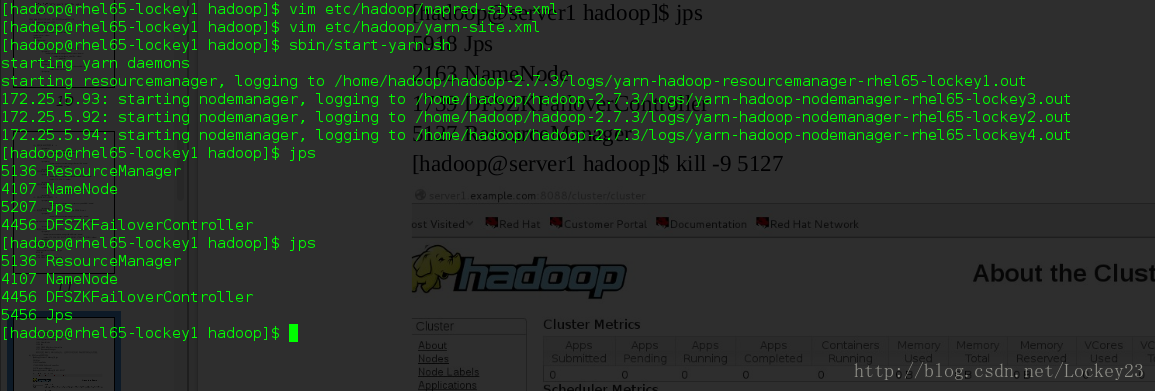
但是这个进程不会在5上自动启动,所以需要手动去5上进行启动
sbin/yarn-daemon.sh start resourcemanager

这个时候通过浏览器访问两台主机的8088端口可以看到两台主机有不同的ResourceManager HA state:
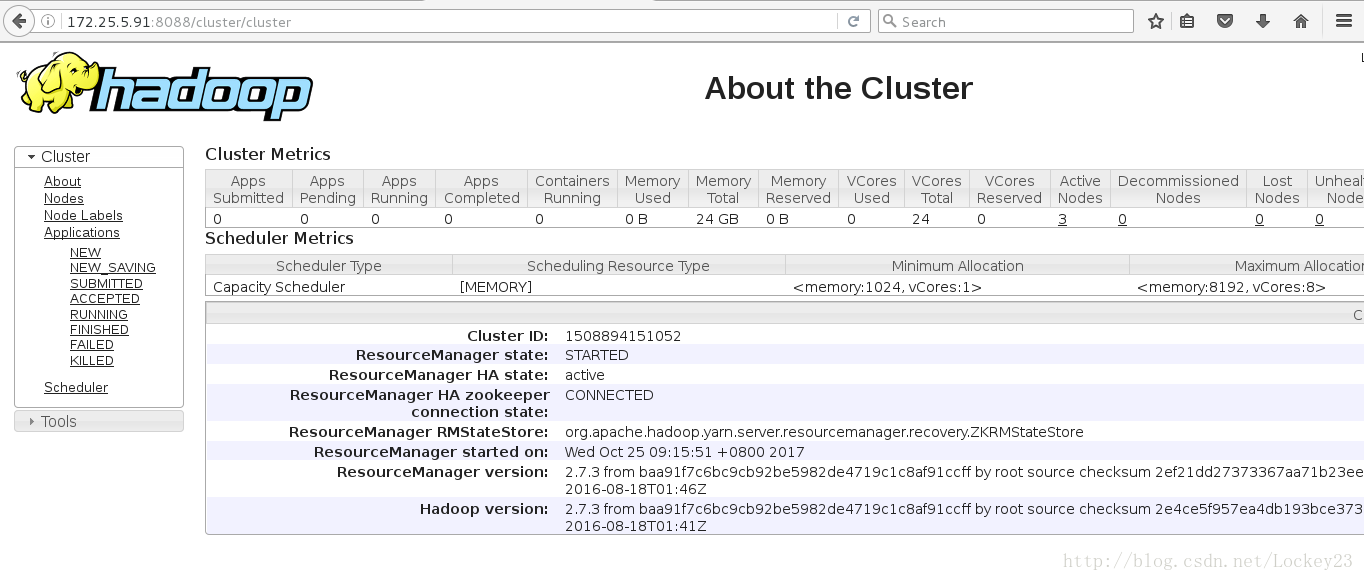
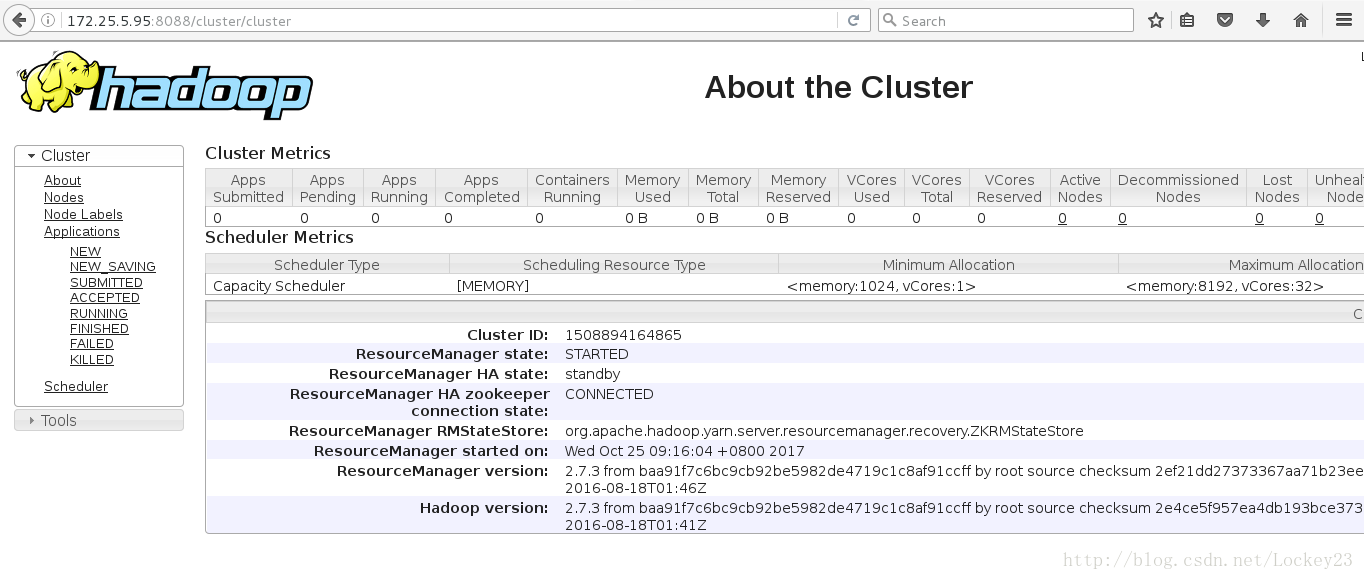
可以将active节点的对应ResourceManager的进程干掉,这个时候再去查看会发现另一边变成了active
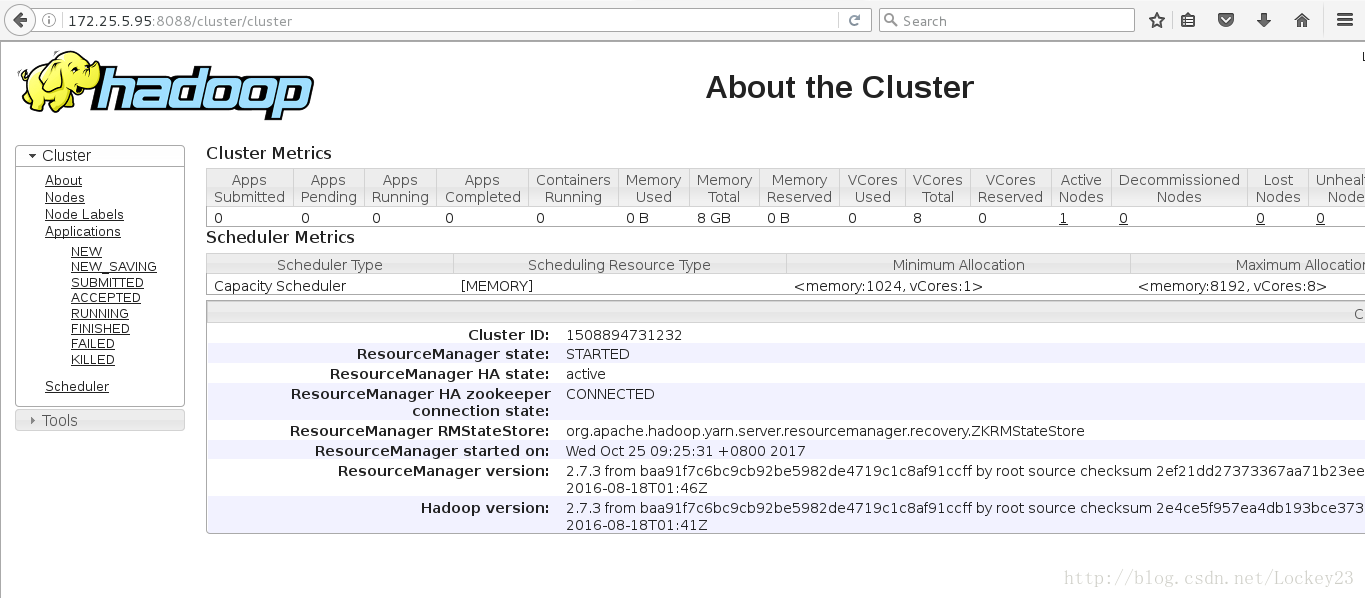
这个时候再去启动被干掉的ResourceManager,他就会成为standby状态
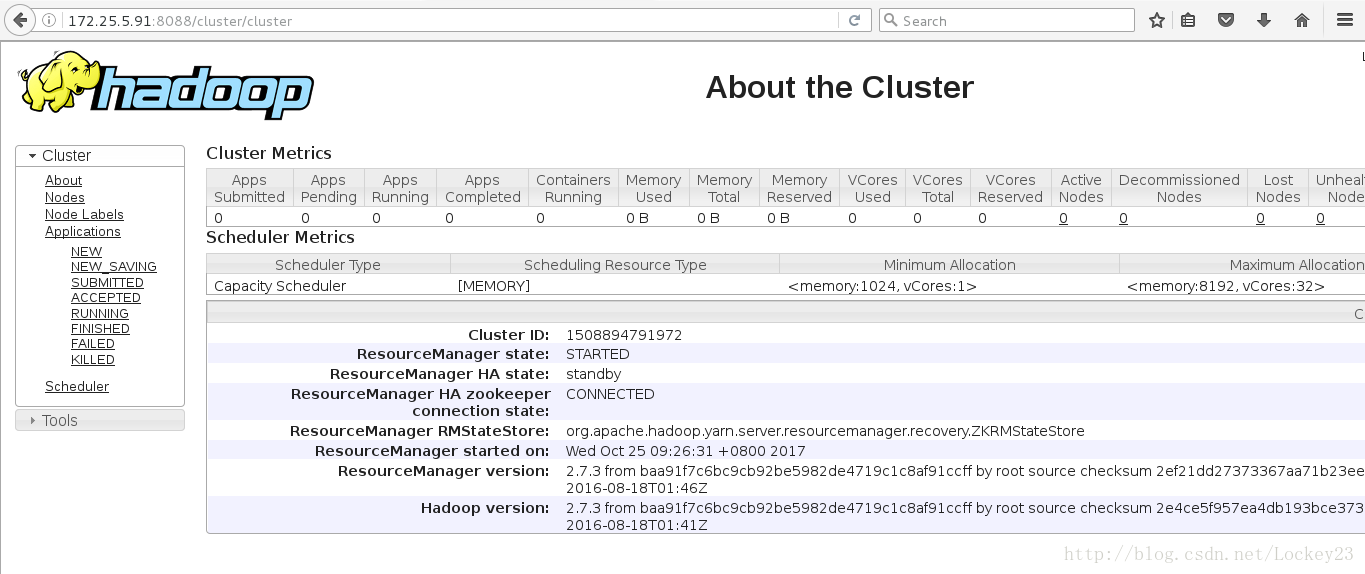
也可以在命令行中通过在任意ZK节点上运行以下命令来进行查看
[hadoop@rhel65-lockey2 zookeeper-3.4.9]$ bin/zkCli.sh -server 127.0.0.1:2181

关于hadoop集群常用的命令如下:
bin/hdfs namenode -format #格式化 HDFS 集群
sbin/start-dfs.sh #启动 hdfs 集群
sbin/stop-dfs.sh#停止hdfs 集群
bin/hdfs zkfc -formatZK#格式化 zookeeper
sbin/hadoop-daemon.sh start namenode#启动namenode
sbin/start-yarn.sh #启动 yarn 服务
sbin/stop-yarn.sh #关闭 yarn 服务
sbin/yarn-daemon.sh start resourcemanager#启动resourcemanager















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









