







正则表达式在爬虫和处理字符串的过程中常常会被用到,例如解决下面两个问题
(1)去除爬取到的结果里面的特殊字符/[^]
(2)我只想让文本中留下中文字符。
python的re包提供了强大的正则表达式应用,能让我们方便的解决类似上面的问题。具体的步骤也比较简单
(1)首先我们要根据正则表达式的规则写出我们想要去寻找或者匹配的模式,例如:[^\u4E00-\u9FD5]+,是说匹配除了中文以外的字符
(2)用re.compile()函数可以将我们写好的表达式生成一个模式对象,该对象具有查询,替换等功能
(3)拿着该对象,re的功能函数,例如search,sub,以及我们想要操作的字符串,我们可以做点什么了~
下面先简要的总结一下常用的正则表达式规范:
(不熟练的话基本每次写每次查。。。所以要经常practice啊)
1.正则表达式:
| 通配符 | . | 匹配任意一个字符(除换行符) |
| 特殊字符转义 | \ | python\.org,为了获得re中的单个反斜线,需要使用两个反斜线 python\\.org |
| 原始字符串 | r'..' | r'python\.org' 如此不需要再使用两个反斜杠 |
| 字符集 | [] | 匹配在一个范围内的单个字符'[abc]d'可以匹配ad,bd,cd '[a-z]d'可以匹配a-z26个字母中的任意一个 '[a-zA-Z0-9]'可以匹配大小写字母和数字的一个 |
| 反转字符集 | ^ | '[^abc]'匹配除了abc外的字符 |
| 选择符 | | | 'python|perl'匹配python或者perl |
| 子模式 | () | 用'()'把需要选择性匹配的部分括起来 'p(ython|erl)' |
| 可选项 | ? | ?表示前面的子模式可以出现一次或者不出现 r'(http://)?(www\.)?python\.org' |
| 重复子模式 | * | (abc)* abc重复0次或多次 r'w*\.python\.org'可匹配www.python.org |
|
| + | (abc)+重复1次或多次 |
|
| {m,n} | (abc){m,n}重复m~n次 |
| 脱字符 | ^ | 只在字符开头匹配 '^ht+p'匹配'http://'不匹配'www.http' |
| 末尾 | $ | 'abc$'匹配以'abc'结尾的字符串 |
当当当,下面重点来了,我们写好了正则表达式该对字符串做点什么了是不是
所以我们再来介绍一些常用函数
2. re函数,模式的方法
重中之重,我们需要首先把刚才写好的正则表达式变成一个模式对象,那就是用re.compile.
虽然直接用re的函数和用模式对象的方法可以达到相同的效果,而re函数里可以不用compile,直接应用正则表达式,但我们依然推荐先将正则表达式compile,因为再大型项目中,一个pattern要应用N次的时候,用compile速度会快很多。
| pattern = re.compile(r'[A-Za-z0-9._+]+@[A-Za-z]+\.(com|org|edu|net)') | 生成模式对象pattern |
| re.search(pattern,string) pattern.search(string) | 字符串中查找模式,返回true,false,找到第一个返回 |
| re.match(pattern,string) pattern.match(string) | 在字符串开头匹配 |
| re.match(r'abc$',string) | 从开头匹配到结尾$,只能匹配abc |
| re.split(pattern,string) | re.split('[. ]+','a…b c')->['a','b','c']类似字符串的split |
| re.findall() | 返回所有匹配项的列表 |
| re.sub(pattern,要替换的,string) | 替换 |
| re.escape(string) | 自动将string里可能被当成正则运算符的转义,大量加反斜杠 |
分组
| Group | 把圆括号里匹配到的东西返回出来 |
Group(1)匹配第一个左圆括号的位置,0是全部字符串
3. 小试牛刀

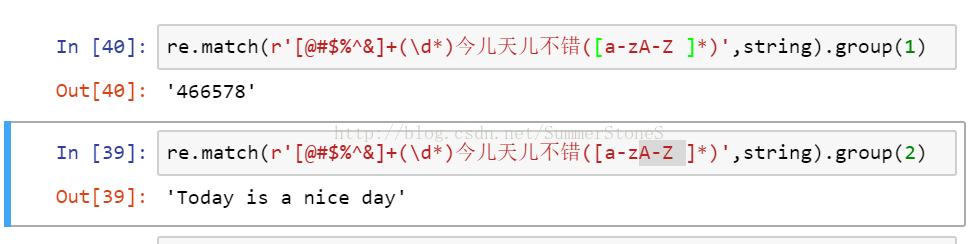
对于search对象我们可以用.span()取出span的内容,即开始的位置,和匹配到的字符串长度;用.group()可以取出match里的内容,如果我们预先用多个()构成正则表达式即我们要匹配多个模式,那么group(1),group(2)等表示我们要取第几个子模式
关于\的用法,因为python内置里‘\’就有转义的含义,所以在python中如果希望把\当成普通字符,要么可以\\,要么r'df\df'可以实现反转义,在re中,正则表达式里\会再一次被认为是转义符,所以我们需要首先让我们写的表达式里的\是个普通的\,再被re读取成模式时当成转义符
更多的表达式查询可以参见w3school
re.findall(re.compile(r'[A-Z]\w+'),string) 找出所有大写字母开头的单词
r'\w+'找出所有单词
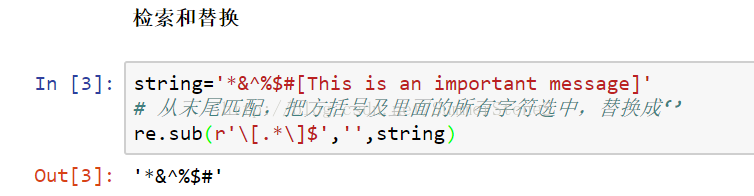
r'\[.*\]' 找出任何在方括号里的东西 square bracket
r'[\w\s]+:' 例如,匹配 ARTHUR:














 1860
1860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









