







介绍
传统监督学习: 对于一个给定训练数据集,通过训练使模型可以识别训练数据集,并将其泛化到测试数据集中。要求测试数据集中数据标签类别包含在训练数据集中。
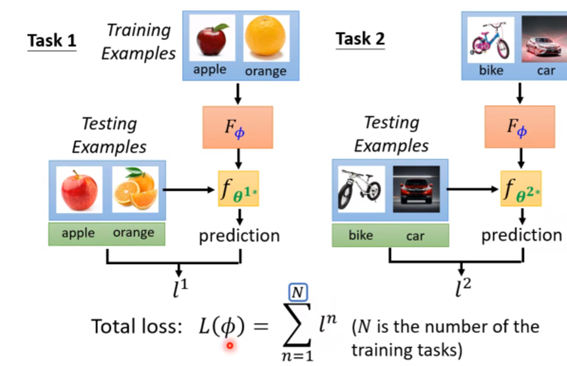
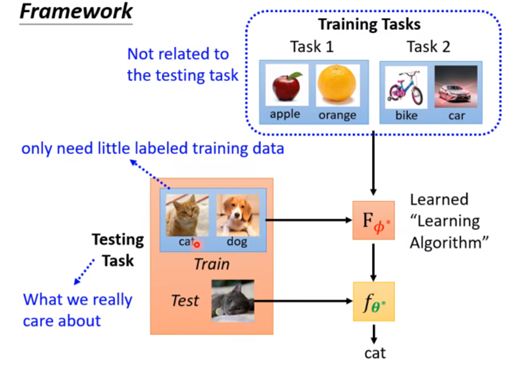
元学习(Meta-learning): 目的是让模型learn to learn,使模型可以区分不同的事物。意思是让模型自己学会学习。few-shot learning 是Meta learning的一种实例,依靠少量的样本完成自主推理的过程。
小样本学习的实际训练集和测试集是由一个个的Task组成的,所以为了进行区分,每个任务内部的训练集(Training Set)更名为支持集(Support Set)、测试集更名为查询集(Query Set)。总的来说,support set用于训练得到每个类别的learning算法,而query set用于评价learning算法的好坏。
Prototypical networks
为了减少因数据量过少而导致的过拟合的影响,将样本投影到一个度量空间,且在这个空间中同类样本距离较近,异类样本的距离较远。每一个support instance创建一个原型(RNN编码)表示(protoypicla representation) ,并将同一类别的instances的编码求和取平均,作为该类别的原型表示,对于一个需要分类的target query,采用计算每一类别的原型向量和查询点的距离来确定target query的类别 。
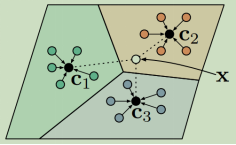
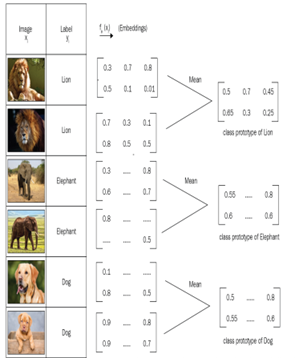
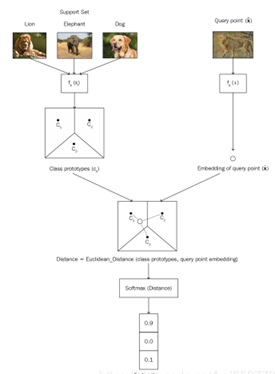
但是原型网络是粗糙的,没有考虑数据中不同的噪音对实验的影响,噪音有可能会削弱原型的区分度。
模型
N-way K-shot
在每个任务中,从训练集中采样N个类别,每个类别采样K+Q个样本。然后将这个任务的数据分为support set和query set,其中support set包含N个类别,每个类别K个样本,query set包含N个类别,每个类别Q个样本。本文中作者采用的N=5或10,K=5或10
目前大多数有效的文本分类方法都是基于大规模的标注数据和大量的参数,但是当有监督的训练数据较少且难以收集时,这些模型就不适用了。在本文中,作者提出了一个层次注意原型网络 (HAPN)用于小样本文本分类。作者设计了特征级、词级和实例级的多重交叉注意增强语义表达能力的模型空间。作者验证了模型基于两个标准基准fewshot 文本分类数据集- FewRel和 CSID,并实现最先进的性能。
Instance Encoder
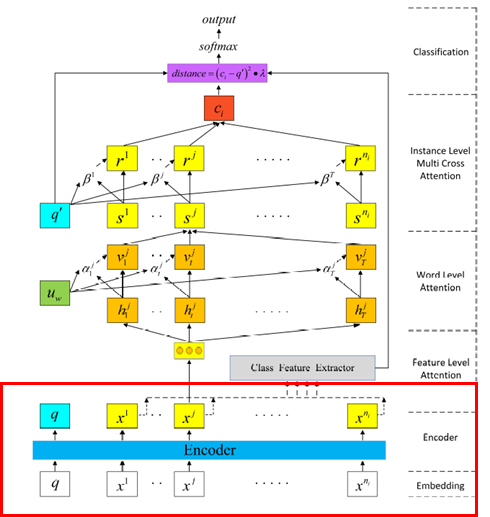


Prototypical Networks

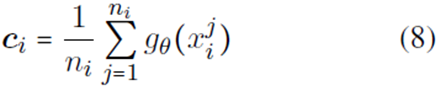
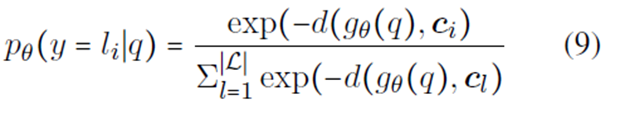
Hierarchical Attention
Feature Level Attention(feature exactor)
given a support set Si of class li
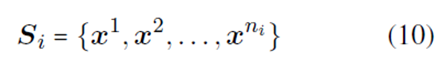
to get the score vectors![]() of class li
of class li
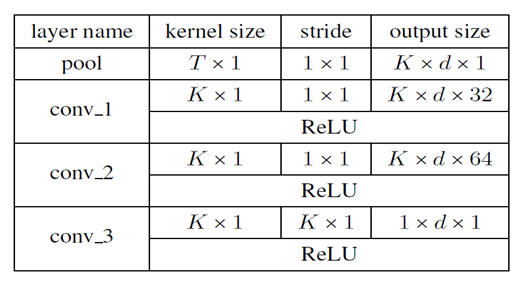
Word Level Attention
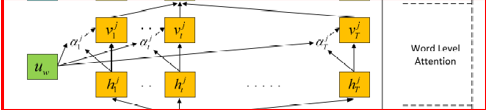
to get the important words and assemble them to a more infortmative instance vector
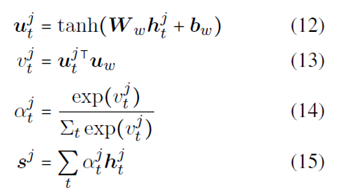
New distance calculation method
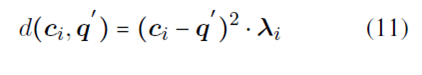
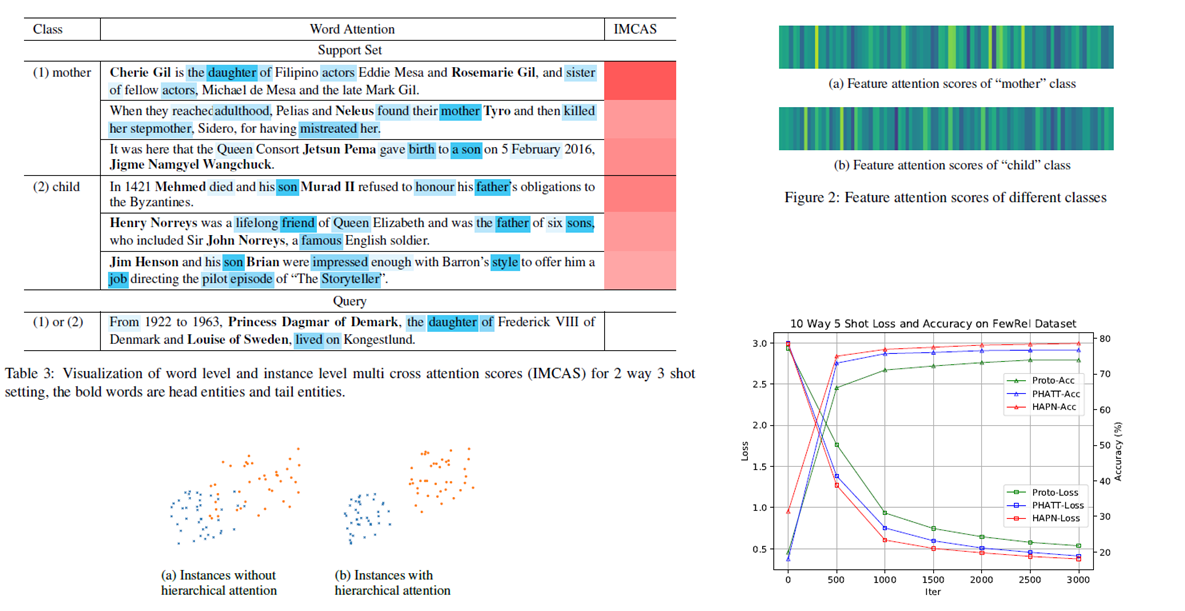
Instance Level Multi Cross Attention
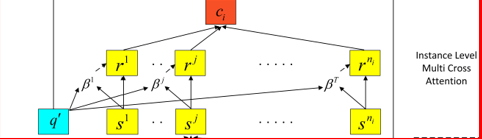
to highlight the importance of support instances which are useful clues to classify a query instance correctly
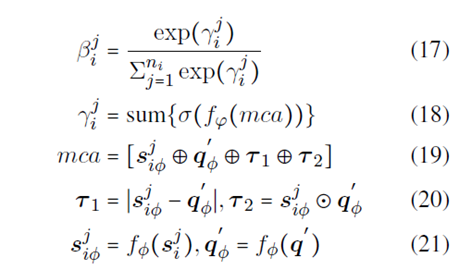
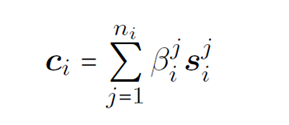
实验
数据集
FewRel:它由来自维基百科的 100 个关系上的 70000 个实例组成,每个关系包括 700 个实例。它还标记了每个实例中的头部和尾部实体,平均token数为 24.99。 FewRel 有 64 个用于训练的关系,16 个用于验证的关系,以及 20 个用于测试的关系
CSID:意图检测是从现实世界的开放域聊天机器人中提取的数据集。在 character studio 平台中,这个聊天机器人应该在某个时候改变它的字符样式,以适应不同的用户群和环境,因此对话查询意图检测成为一项重要任务。 CSID由128个意图的24596个实例组成,每个意图包括30到260个实例,每个实例中的平均token数为11.52。我们分别使用 80、18 和 30 个意图进行训练、验证和测试。
结果
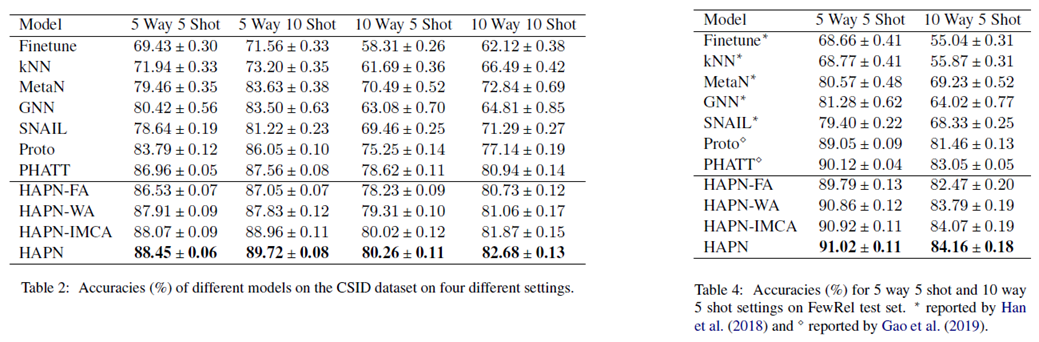
总结
为了解决few-shot learning 中易受噪声实例影响这一问题(由于任务的背景是在few-shot学习中,用来计算类原形的样本数量往往很少。如果出现错误实例或者是和常规句子语义偏差较大的正确实例的话,对于类原形的影响是非常的巨大。
初始原型网络
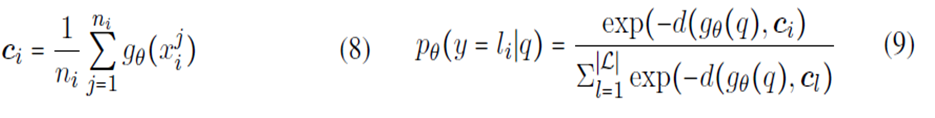
加入word level attention 、feature level attention

加入instance level attention,引入加权平均的思想,降噪
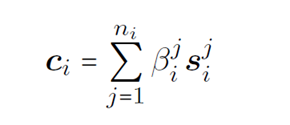
突出了少量数据的重要信息,学习了更具辨别力的原型表示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









