




 这篇文章介绍了PET(Pattern-ExploitingTraining)这一半监督学习技术,它利用BERT的预训练知识进行少量样本的文本分类。PET通过构造完形填空问题,将预训练模型参数有效利用,尤其在资源匮乏的NLP场景中提升效果。方法包括Pattern-Verbalizer-Pair、知识蒸馏和iPET迭代,显著扩大了有标注数据的应用范围。
这篇文章介绍了PET(Pattern-ExploitingTraining)这一半监督学习技术,它利用BERT的预训练知识进行少量样本的文本分类。PET通过构造完形填空问题,将预训练模型参数有效利用,尤其在资源匮乏的NLP场景中提升效果。方法包括Pattern-Verbalizer-Pair、知识蒸馏和iPET迭代,显著扩大了有标注数据的应用范围。
PET(Pattern-Exploiting Training)出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021),是一种半监督的训练方法。

目标
由于大量的language、domain和task以及人工标注数据的成本,在NLP的实际使用中,通常只有少量带标签的示例,所以few-shot是值得研究的部分;如果依然使用传统的监督学习方法,容易过拟合,效果会非常差,因为当仅有很少的样本时,仅有的文本无法让模型知道要具体如何进行分类
在本文中,作者提出了Pattern-Exploiting Training(PET),一种半监督的训练方法,将一句完整的输入样本构造成完形填空的语句后再进行输入预处理模型。
先前的预训练模型
BERT的预训练其中一个任务是MLM,就是去预测被【MASK】掉的token,采用的是拿bert的最后一个encoder(base版本,就是第12层的encoder的输出,也即下图左图蓝色框)作为输入,然后接全连接层,做一个全词表的softmax分类(这部分就是左图的红色框)。但在fine tuning的时候,我们是把MLM任务的全连接层抛弃掉,在最后一层encoder后接新的初始化层来做具体的下游任务。
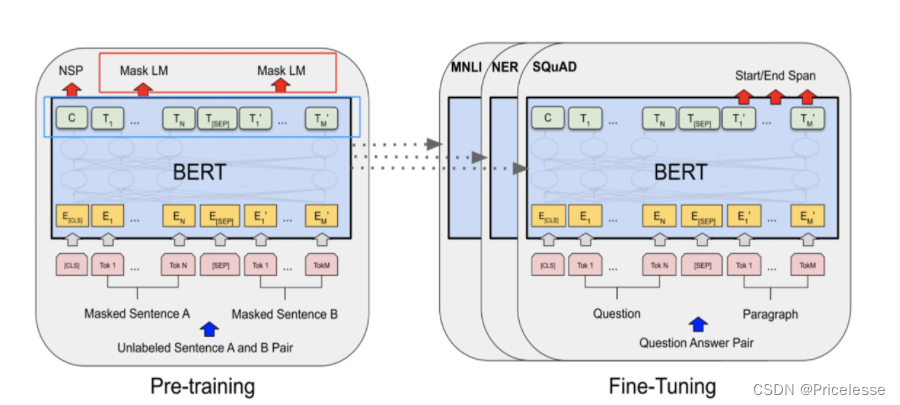
能不能通过某些巧妙的设计,把MLM层学习到的参数也利用上?
举例:
输入一条汽车论坛的评论,输出这个评论是属于【积极】or【消极】每个类别如果只有10个labeled数据,1K条unlabeled数据。
现在通过改造输入,如下图,

model对下划线__部分进行预测。BERT预训练时MLM任务是预测整个词表,而这里把词表限定在{好,差},cross entropy交叉熵损失训练模型。预测时,假如预测出好,即这个样例预测label就为积极,预测为差,这个样例就是消极。
「BERT预训练时的MLM层的参数能利用上」。而且「即使model没有进行fine tunning,这个model其实就会含有一定的准确率
参数说明
Pattern-Verbalizer-Pair
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









