







一、Python基础补充
map函数
map(function,iterable,…)
第一个参数接受一个函数,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。
把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list
del square(x):
return x ** 2
map(square,[1,2,3,4,5])
# 结果如下:[1,4,9,16,25]
lambda匿名函数
map(lambdax, y : (x**y,x+y),[2,4,6],[3,2,1])
# 结果如下[(8,5),(16,6),(6,7)]
zip函数
zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象,它返回了一个 zip 对象,通过 tuple, list 可以得到相应的打包结果
位置对应的截取
import numpy as np
a=[1,2,3,4,5]
b=(1,2,3,4,5)
c=np.arange(5)
d="zhang"
zz=zip(a,b,c,d)
print(zz)
#输出:[(1, 1, 0, 'z'), (2, 2, 1, 'h'), (3, 3, 2, 'a'), (4, 4, 3, 'n'), (5, 5, 4, 'g')]
长度不一样时
import numpy as np
a=[1,2,3]
b=[1,2,3,4]
c=[1,2,3,4,5]
zz=zip(a,b,c)
print(zz)
输出:[(1, 1, 1), (2, 2, 2), (3, 3, 3)]
打包:zz=zip(a,b,c)
解包:x,y,z=zip(*zz)
import numpy as np
a=[1,2,3]
b=[4,5,6,7]
c=[8,9,10,11,12]
zz=zip(a,b,c)
print(zz)
x,y,z=zip(*zz)
print(x)
print(y)
print(z)
#输出:
#[(1, 4, 8), (2, 5, 9), (3, 6, 10)]
#(1, 2, 3)
#(4, 5, 6)
#(8, 9, 10)
enumerate
enumerate 是一种特殊的打包,它可以在迭代时绑定迭代元素的遍历序号
L = list('abcd')
for index, value in enumerate(L):
print(index, value)
#0 a
#1 b
#2 c
#3 d
也可以用zip实现这功能
for index,value in zip(range(lenge(L)),L):
print(index, value)
要对两个列表建立映射时,用zip可实现
L1, L2, L3 = list('abc'), list('def'), list('hij')
dict(zip(L1, L2))
#结果: {'a': 'd', 'b': 'e', 'c': 'f'}
二、Numpy基础补充
np数组的构造
1,array([ ])
import numpy as np
np.array([1,2,3])
# array([1, 2, 3])
2,等差序列 np.linspace, np.arange
np.linspace(1,5,11) # 起始、终止(包含)、样本个数
np.arange(1,5,2) # 起始、终止(不包含)、步长
3,特殊矩阵zeros, eye, full
np.zeros((2,3)) # 传入元组表示各维度大小
np.eye(3) # 3*3的单位矩阵,一定是方阵
np.eye(3, k=1) # 偏移主对角线1个单位的伪单位矩阵
np.full((2,3), 10) # 元组传入大小,10表示填充数值
np.zeros((2,3)) # 传入元组表示各维度大小
#array([[0., 0., 0.],
# [0., 0., 0.]])
np.eye(3) # 3*3的单位矩阵
#array([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
np.eye(3, k=1) # 偏移主对角线1个单位的伪单位矩阵
#array([[0., 1., 0.],
# [0., 0., 1.],
# [0., 0., 0.]])
np.full((2,3), 10) # 元组传入大小,10表示填充数值
#array([[10, 10, 10],
# [10, 10, 10]])
np.full((2,3), [1,2,3]) # 每行填入相同的列表
#array([[1, 2, 3],
# [1, 2, 3]])
4,随机矩阵np.random
最常用的随机生成函数为 rand, randn, randint, choice ,它们分别表示0-1均匀分布的随机数组、标准正态的随机数组、随机整数组和随机列表抽样
np.random.rand
np.random.rand(3) # 生成服从0-1均匀分布的三个随机数
#array([0.61056105, 0.07458226, 0.3922192 ])
np.random.rand(3, 3) # 注意这里传入的不是元组,每个维度大小分开输入
#array([[0.60036189, 0.11756866, 0.74270676],
# [0.06377773, 0.77984446, 0.18479501],
# [0.09558558, 0.67462215, 0.40496545]])
服从区间a到b上的均匀分布:
a, b = 5, 15
(b - a) * np.random.rand(3) + a
uniform也可以实现上面作用,a到b上的均匀分布
np.random.uniform(5, 15, 3)
randn 生成了 标准正态分布的标准正态分布
对于服从方差为sigma平方,均值为 mu的一元正态分布可以如下生成:
sigma, mu = 2.5, 3
mu + np.random.randn(3) * sigma
同样,normal也可以实现上面作用,方差为sigma平方,均值为 mu的一元正态分布
np.random.normal(3, 2.5, 3)
randint 可以指定生成随机整数的最小值最大值(不包含)和维度大小
low, high, size = 5, 15, (2,2)
np.random.randint(low, high, size)
choice 可以从给定的列表中,以一定概率和方式抽取结果,当不指定概率时为均匀采样,默认抽取方式为有放回抽样
my_list = ['a', 'b', 'c', 'd']
np.random.choice(my_list, 2, replace=False, p=[0.1, 0.7, 0.1 ,0.1])
#array(['b', 'c'], dtype='<U1')
np.random.choice(my_list, (3,3))
#array([['d', 'd', 'd'],
# ['b', 'a', 'b'],
# ['c', 'c', 'd']], dtype='<U1')
当返回的元素个数与原列表相同时,不放回抽样等价于使用 permutation 函数,即打散原列表
np.random.permutation(my_list)
# array(['d', 'a', 'b', 'c'], dtype='<U1')
np数组的变形与合并
转置 a.T
合并 :
np.r_[a,b] 将数组a,b上下合并
np.c_[a,b] 将数组a,b左右合并
一维数组和二维数组进行合并时,应当把其视作列向量,在长度匹配的情况下只能够使用左右合并的 c_ 操作:
import numpy as np
print(np.c_[np.array([1,2]),np.zeros((2,3))])
#[[1. 0. 0. 0.]
# [2. 0. 0. 0.]]
print(np.r_[np.array([1,2]),np.zeros(2)])
#[1. 2. 0. 0.]
print(np.array([1,2]))
#[1 2]
维度变化reshape
target = np.arange(8).reshape(2,4)
target
Out[66]:
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
target.reshape((4,2), order='C') # 按照行读取和填充
Out[67]:
array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])
target.reshape((4,2), order='F') # 按照列读取和填充
Out[68]:
array([[0, 2],
[4, 6],
[1, 3],
[5, 7]])
由于被调用数组的大小是确定的, reshape 允许有一个维度存在空缺,此时只需填充-1即可.
所以,target.reshape((4,-1))同上述中的target.reshape((4,2))
np数组的切片与索引
np.ix_()
可以利用 np.ix_ 在对应的维度上使用布尔索引,但此时不能使用 slice 切片
target = np.arange(9).reshape(3,3)
target
Out[74]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
target[np.ix_([True, False, True], [True, False, True])]
Out[76]:
array([[0, 2],
[6, 8]])
target[np.ix_([1,2], [True, False, True])]
Out[77]:
array([[3, 5],
[6, 8]])
np.where()
a = np.array([-1,1,-1,0])
np.where(a>0, a, 5) # 对应位置为True时填充a对应元素,否则填充5
# array([5, 1, 5, 5])
nonzero, argmax, argminnonzero 返回非零数的索引, argmax, argmin 分别返回最大和最小数的索引
a = np.array([-2,-5,0,1,3,-1])
np.nonzero(a)
Out[83]: (array([0, 1, 3, 4, 5], dtype=int64),)
a.argmax()
Out[84]: 4
a.argmin()
Out[85]: 1
any, all
any 指当序列至少 存在一个 True 或非零元素时返回 True ,否则返回 False
all 指当序列元素 全为 True 或非零元素时返回 True ,否则返回 False
cumprod, cumsum, diff
cumprod, cumsum 分别表示累乘和累加函数,返回同长度的数组, diff 表示和前一个元素做差,由于第一个元素为缺失值,因此在默认参数情况下,返回长度是原数组减1
a = np.array([1,2,3])
a.cumprod()
Out[90]: array([1, 2, 6], dtype=int32)
a.cumsum()
Out[91]: array([1, 3, 6], dtype=int32)
np.diff(a)
Out[92]: array([1, 1])
统计函数
max, min, mean, median, std, var, sum, quantile
target = np.arange(5)
target
Out[94]: array([0, 1, 2, 3, 4])
target.max()
Out[95]: 4
np.quantile(target, 0.5) # 0.5分位数
Out[96]: 2.0
但是对于含有缺失值的数组,它们返回的结果也是缺失值,如果需要略过缺失值,必须使用 nan* 类型的函数,上述的几个统计函数都有对应的 nan* 函数。
target = np.array([1, 2, np.nan])
target
Out[98]: array([ 1., 2., nan])
target.max()
Out[99]: nan
np.nanmax(target)
Out[100]: 2.0
协方差和相关系数分别可以利用 cov, corrcoef
np.cov(数组1,数组2)
np.corrcoef(数组1,数组2)
axis=0 时结果为列的统计指标,当 axis=1 时结果为行的统计指标
target = np.arange(1,10).reshape(3,-1)
target
Out[107]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
target.sum(0) #列和
Out[108]: array([12, 15, 18])
target.sum(1) #行和
Out[109]: array([ 6, 15, 24])
向量与矩阵的计算
向量内积: a.dot(b)
向量范数和矩阵范数: np.linalg.norm
矩阵乘法: @
三、练习
1,矩阵乘法的实习
三重循环
import numpy as np
m1 = np.random.rand(2,3)
m2 = np.random.rand(3,4)
res = np.empty((m1.shape[0],m2.shape[1]))
print(res)
for i in range(m1.shape[0]):
for j in range(m2.shape[1]):
item = 0
for k in range(m1.shape[1]):
item += m1[i][k]*m2[k][j]
res[i][j] = item
print((np.abs((m1@m2-res)<1e-15)).all())
#True
列表推导式
res2 = [[sum([M1[i][k] * M2[k][j] for k in range(M1.shape[1])])
for j in range(M2.shape[1])] for i in range(M1.shape[0])]
2,更新矩阵

三重循环可实现
import numpy as np
a = np.array(range(1,10)).reshape(3,3)
print(a)
def changejuzheng(a):
b = np.empty(a.shape)
for i in range(a.shape[0]):
for j in range(a.shape[1]):
item = 0
for k in range(a.shape[0]):
item += 1/a[i][k]
b[i][j] = a[i][j]*item
return b
print(changejuzheng(a))
同样一行代码也可,sum(1)指对行求和
B = A*(1/A).sum(1).reshape(-1,1)
输出:
[[1.83333333 3.66666667 5.5 ]
[2.46666667 3.08333333 3.7 ]
[2.65277778 3.03174603 3.41071429]]
3,卡方统计量
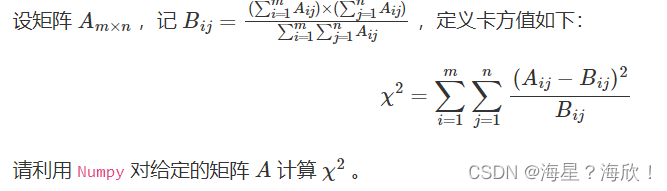
np.random.seed(0)
A = np.random.randint(10, 20, (8, 5))
B = A.sum(0)*A.sum(1).reshape(-1, 1)/A.sum()
res = ((A-B)**2/B).sum()
res
# 11.842696601945802
4,求连续整数的最大长度
输入一个整数的 Numpy 数组,返回其中严格递增连续整数子数组的最大长度。例如,输入 [1,2,5,6,7],[5,6,7]为具有最大长度的递增连续整数子数组,因此输出3;输入[3,2,1,2,3,4,6],[1,2,3,4]为具有最大长度的递增连续整数子数组,因此输出4。
f = lambda x:np.diff(np.nonzero(np.r_[1,np.diff(x)!=1,1])).max()
f([1,2,5,6,7])
#3
f([3,2,1,2,3,4,6])
#4















 6703
6703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









