







目录
1、项目背景
数据
用户数据表user_table字段:
用户行为数据表Data_Action_201602.csv、Data_Action_201603.csv、Data_Action_201604.csv

2、标记高潜用户
高潜用户应该具备以下特征:
- 有购买行为
- 对一个商品购买和其他交互行为(浏览点击收藏等)时间差应该多于一天
问题:数据量太大每个csv中有100多万条数据—分数据块读取
1,数据合并提取
# 读取文件数据。迭代器,1万条1万条的读取
def read_actionData(filePath,size=10000):
df = pd.read_csv(filePath,header=0,iterator=True)#迭代器格式,一部分一部分的读取
chunks = [] #保存数据块的列表
loop = True #循环起始值
while loop:
try:
chunk = df.get_chunk(size)[['user_id','sku_id','type','time','cate']]
chunks.append(chunk)
except StopIteration:
loop = False
print('StopIteration is stopped')
df_ac = pd.concat(chunks,ignore_index=True)
return df_ac
#讲多个表的数据合并在一起
df_ac =[]
df_ac.append(read_actionData(filePath='Data_Action_201602.csv'))
df_ac.append(read_actionData(filePath='Data_Action_201603.csv'))
df_ac.append(read_actionData(filePath='Data_Action_201604.csv'))
df_ac = pd.concat(df_ac,ignore_index=True)
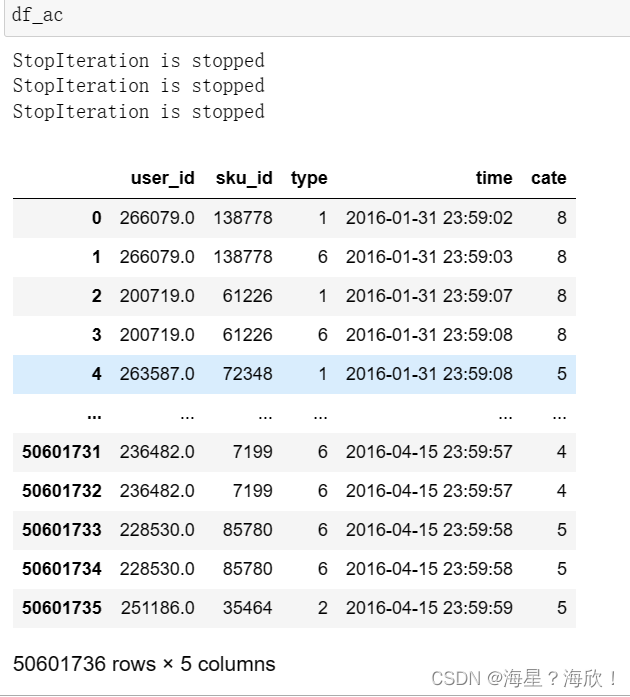
df_ac
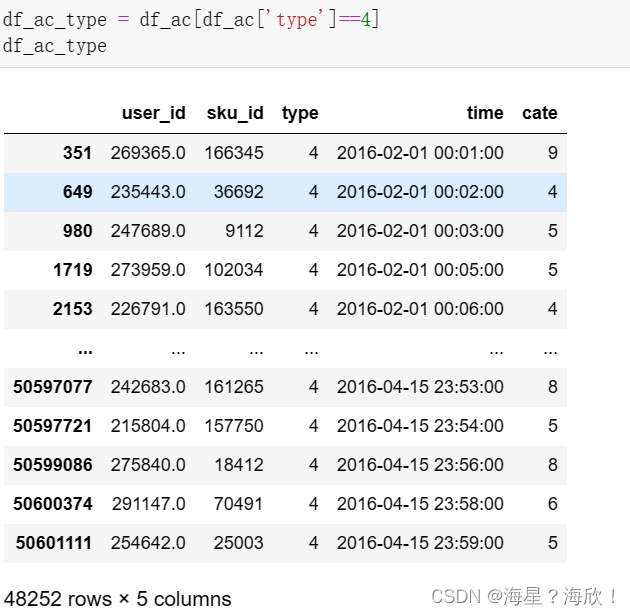
2,下单人群–type为4的数据
针对的是已经下单用户
df_ac_type = df_ac[df_ac['type']==4]
df_ac_type
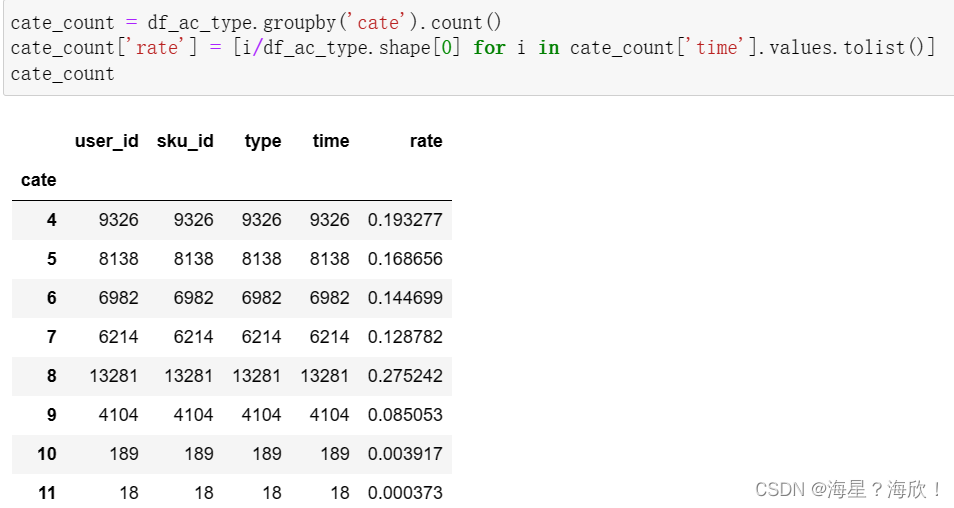
3,查看每类商品用户下单的占比
cate–商品种类
cate_count = df_ac_type.groupby('cate').count()
cate_count['rate'] = [i/df_ac_type.shape[0] for i in cate_count['time'].values.tolist()]
cate_count
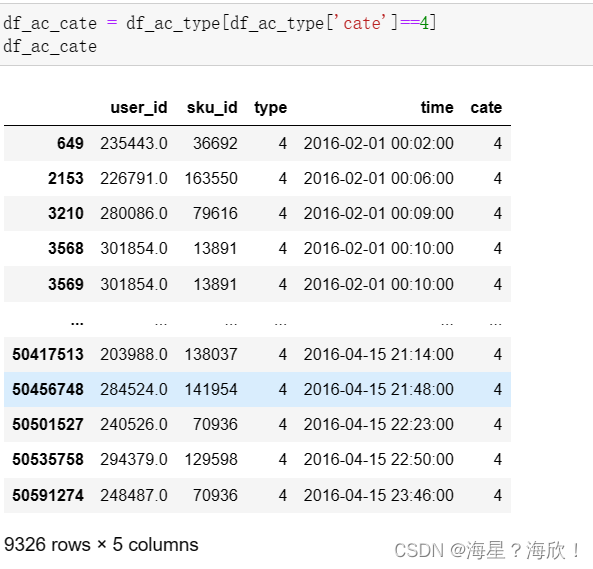
4,选取第四类产品的数据
下单人群中第四类产品:
df_ac_cate = df_ac_type[df_ac_type['cate']==4]
df_ac_cate
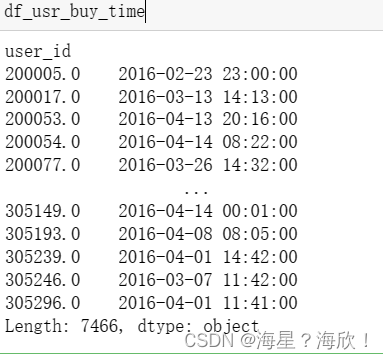
5,计算每个用户的最后购买时间
def last_time(user):
return user['time'].max()
df_usr_buy_time = df_ac_cate.groupby(by='user_id').apply(last_time)
#按照用户id分组,取时间中的最大时间--下单时间
df_usr_buy_time
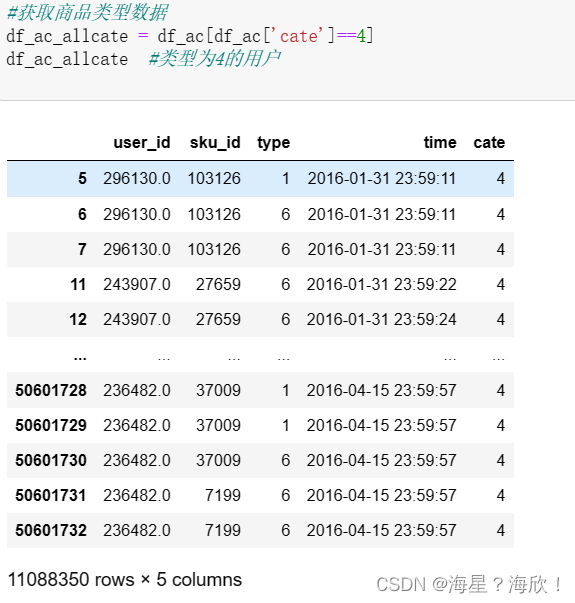
6,最早与该商品发生交互的日期
#获取商品类型数据
df_ac_allcate = df_ac[df_ac['cate']==4]
df_ac_allcate #类型为4的用户
#筛选df_usr_buy_time中每个用户的行为数据
df_all_buy_ac = pd.merge(df_usr_buy_time.to_frame(),df_ac_allcate,left_on = 'user_id',right_on = 'user_id')
#将上面两个表按照用户id合并起来
#获取每个用户行为的最开始的时间
def first_time(user):
return user['time'].min()
df_use_ac_firsttime = df_all_buy_ac.groupby(by='user_id').apply(first_time)
df_use_ac_firsttime

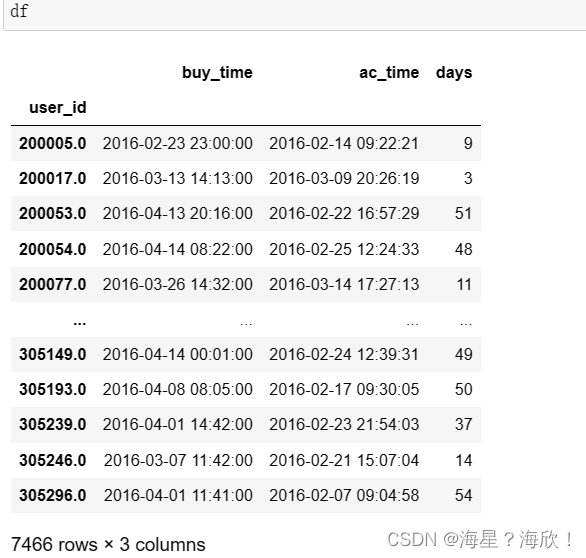
7,计算最早交互时间和最后购买时间差
df = pd.merge(df_usr_buy_time.to_frame(),df_use_ac_firsttime.to_frame(),on='user_id')
df.columns = ['buy_time','ac_time']
df['days'] = (df['buy_time'].astype('datetime64')-df['ac_time'].astype('datetime64')).dt.days
df
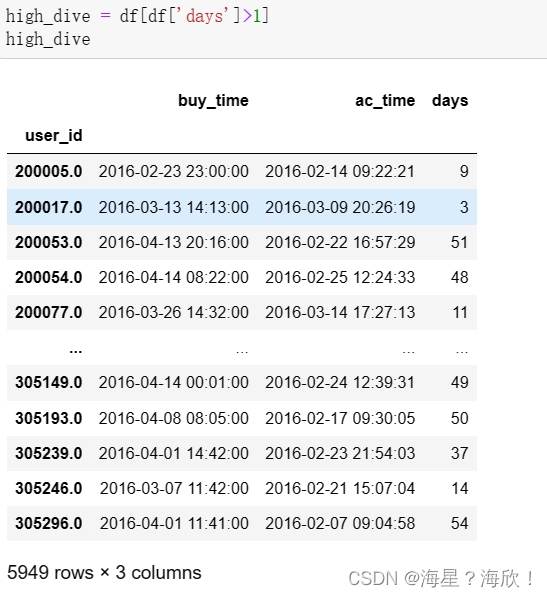
8,获取高潜用户
high_dive = df[df['days']>1]
high_dive
3、基于高潜用户信息进行分析
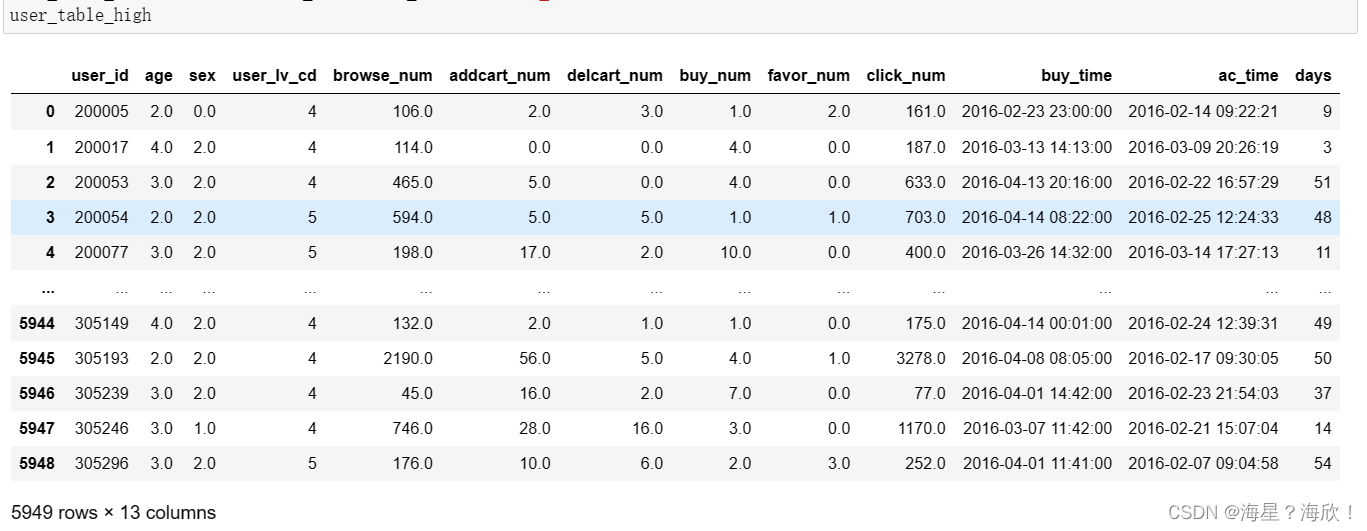
3.1 筛选高潜用户静态数据
user_table = pd.read_csv('user_table.csv')
#将两个时间进行合并high_divd和user_table
user_table_high = pd.merge(user_table,high_divd,on='user_id')
user_table_high
3.2 高潜客户的客户等级分布
user_lv_count = user_table_high.groupby(by='user_lv_cd').count()
#饼图
import matplotlib.pyplot as plt
import matplotlib
plt.pie(user_lv_count['user_id'].values.tolist(),
labels=user_lv_count.index.tolist(),
autopct='%1.1f%%')
plt.show()

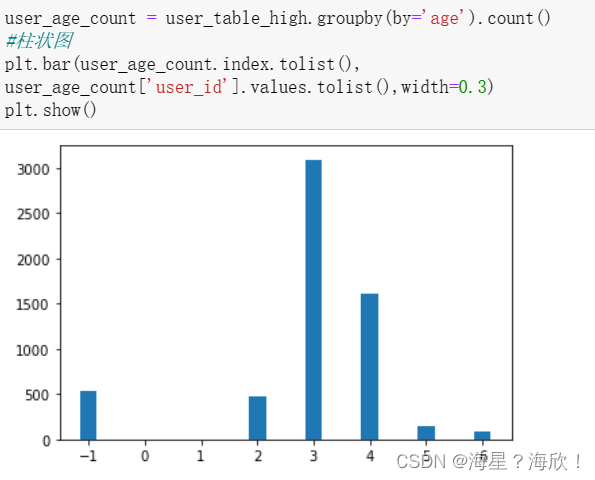
3.3 高潜用户的年龄段对比
user_age_count = user_table_high.groupby(by='age').count()
#柱状图
plt.bar(user_age_count.index.tolist(),
user_age_count['user_id'].values.tolist(),width=0.3)
plt.show()
3.4 根据df_ac_cate 和高潜用户id匹配出高潜用户的购买该商品记录
df_buy_high = df_ac_cate[df_ac_cate['user_id'].isin(high_dive.index.tolist())]
df_buy_high

#将数据列转换为时间格式
df_buy_high['time'] = df_buy_high['time'].astype('datetime64')
df_buy_high
3.4 计算周一到周五每天的购买数量
#使用lambda匿名函数将时间time转化为星期(周一为1)
df_buy_high['weekday'] = df_buy_high['time'].apply(lambda x:x.weekday()+1)
df_buy_high_count = df_buy_high.groupby(by='weekday').count()
plt.bar(df_buy_high_count.index.tolist(),
df_buy_high_count['user_id'].values.tolist())
plt.show()
















 3915
3915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









