







1、最佳实战
1.1 表的分类
维度建模中表的类型:事实表和维度表
事实表又可以分为:事务事实表、周期快照事实表、累积快照事实表
事实表:一般指现实存在的业务对象,比如用户、商品、商家、销售员等

维度表:对应一些业务状态,代码的解释表,也称为码表
通常使用维度对事实表中的数据进行统计、聚合运算
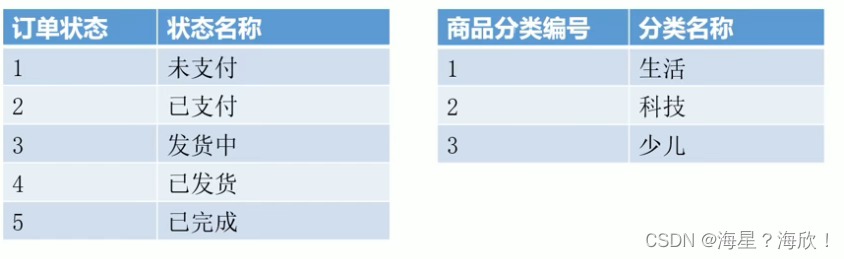
事务事实表:随着业务不断产生的数据、一旦产生不会再变化,如交易流水、操作日志、出库入库记录

周期快照事实表:随着业务周期型的推进而变化,完成间隔周期内的度量统计,如年、季度累计
使用周期+状态度量的组合,如年累计订单数,年是周期,订单总数是量度
分析压力大

累积快照事实表:记录不确定周期的度量统计,完全覆盖一个事实的生命周期,如订单状态表
多个时间字段,用于记录生命周期中的关键时间点
一条记录,对此记录不断更新
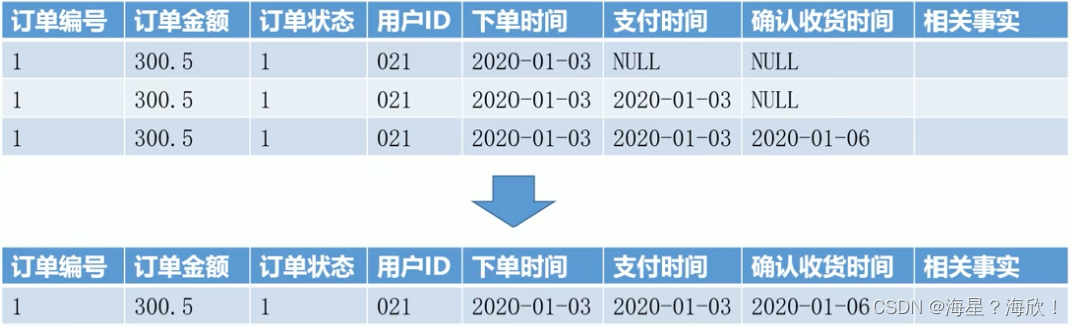
一条事件只有一个记录
累积快照事实表的实现:
实现方式一:使用日期分区表,全量数据记录
存储大量永远不更新的冷数据,对性能影响较大,适用数据量小的情况
实现方式二:存储周期内数据,周期外的冷数据存储到归档表
实现方式三:-使用最多且最好的
使用日期分区表,以业务实体的结束时间分区,每天的分区存放当天结束的数据,设计一个时间非常大的分区,如9999-12-31,存放截止当前未结束的数据
拉链表:记录每条信息的生命周期,用于保留数据的所以历史状态
拉链表将表数据的随机修改方式,变为顺序追加
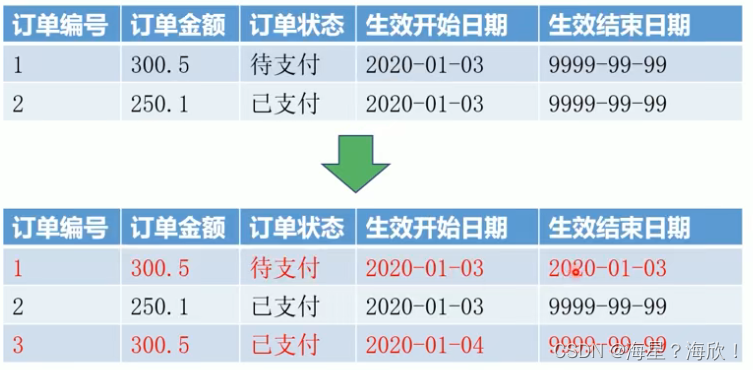
金额300.5的那个信息,上表中结束日期9999-99-99,说明此状态未结束,下表,日期改为了2020-01-03,说明状态已结束,且新增了一条记录,已支付状态,结束日期也是9999-99-99
1.2 ETL策略
两种:全量同步,增量同步
全量同步:
数据初始化装载一定使用全量同步的方式
增量同步:
传统数据整合方案中,大多采用merge方式(update +insert)
大数据平台不支持update操作,可采用全外连接+数据全量覆盖方式
1.3 任务调度
为什么需要任务调度?
- 解决任务单元间的依赖关系
- 自动化完成任务的定时执行
常见任务类型?
shell、java程序、Mapreduce程序、SQL脚本
常见调度工具?
Azkaban、Oozie
2、项目实战
2.1 项目概述
背景:
某电商企业,因数据积存、分析需要,筹划搭建数据仓库,提供数据分析访问接口
项目一期需要完成数仓建设,并完成用户复购率的分析计算,支持业务查询需求
复购率:
指在一段时间间隔内,多次重复购买产品的用户,占全部人数的比率

2.2 数据描述




2.3 架构设计
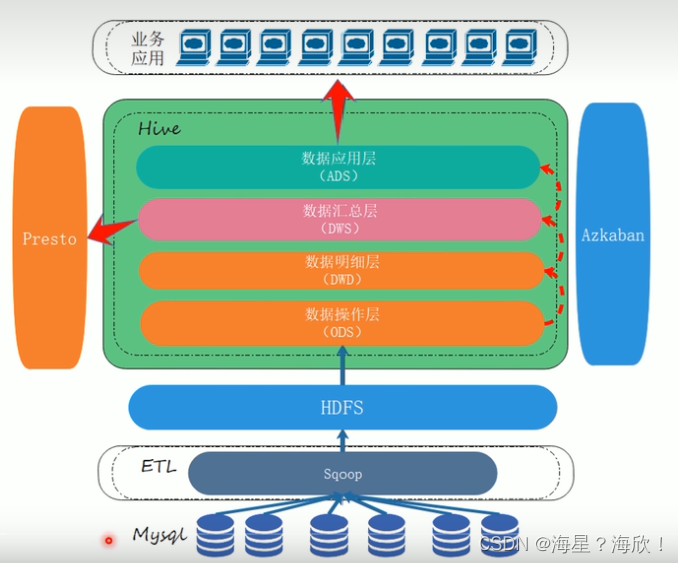
一开始,业务数据存放在Mysql中
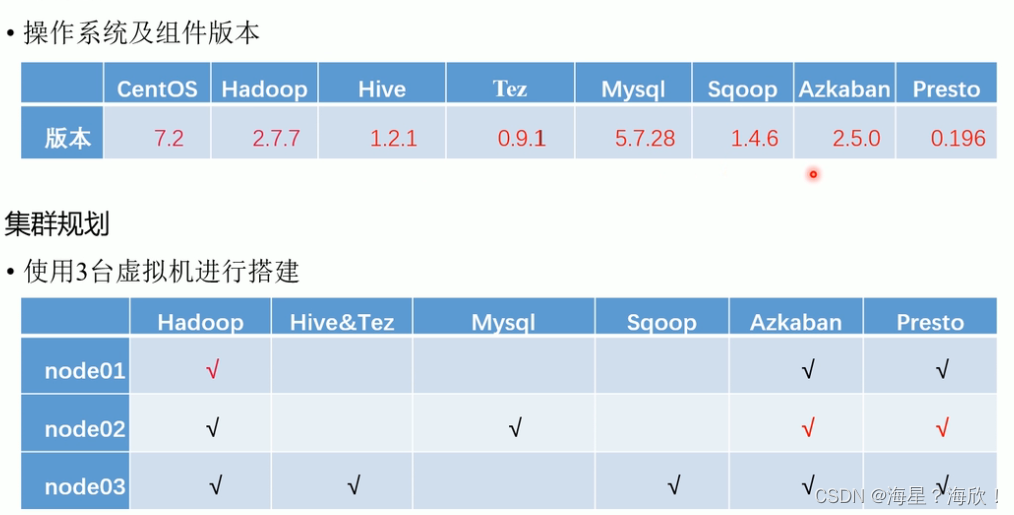
2.4 环境搭建
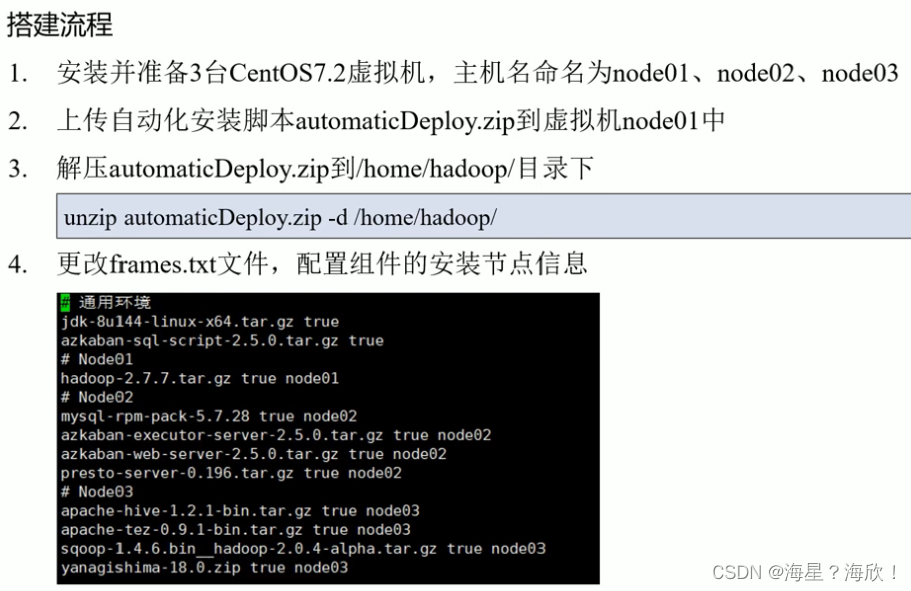
虚拟机搭建 - Xshell - 脚本准备 - 集群按照
2.5 项目开发
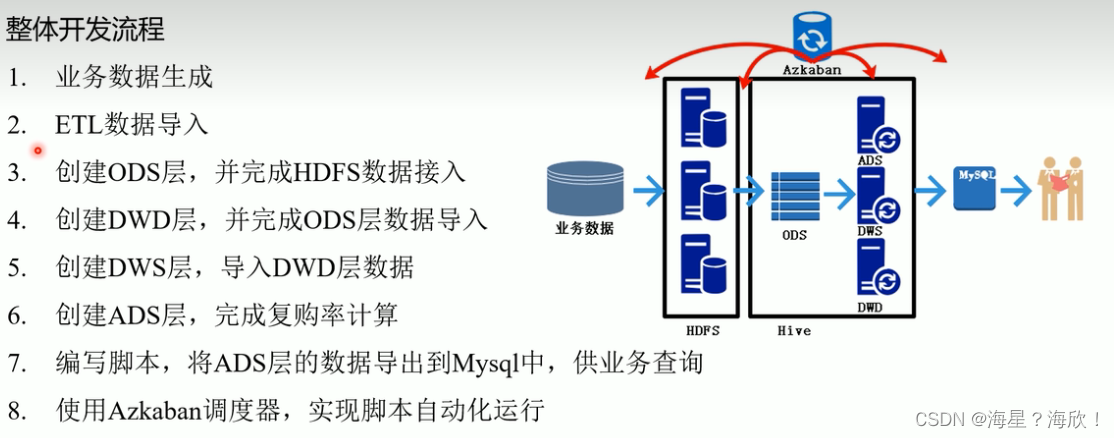
1,业务数据生成:

2,ETL数据导入
后面看不懂了。。。
原视频课程















 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









