







1. Selenium介绍
Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户操作一样。支持的浏览器包括IE(7,8,9,10,11),Mozilla Chrome,Safari,Google Chrome,Opea等。最初是为网站自动化测试而开发的,就像玩游戏用的按键精灵,可以按指定的命令自动操作。
Selenium可以根据的指令让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生等。
1.1 Selenium工作原理
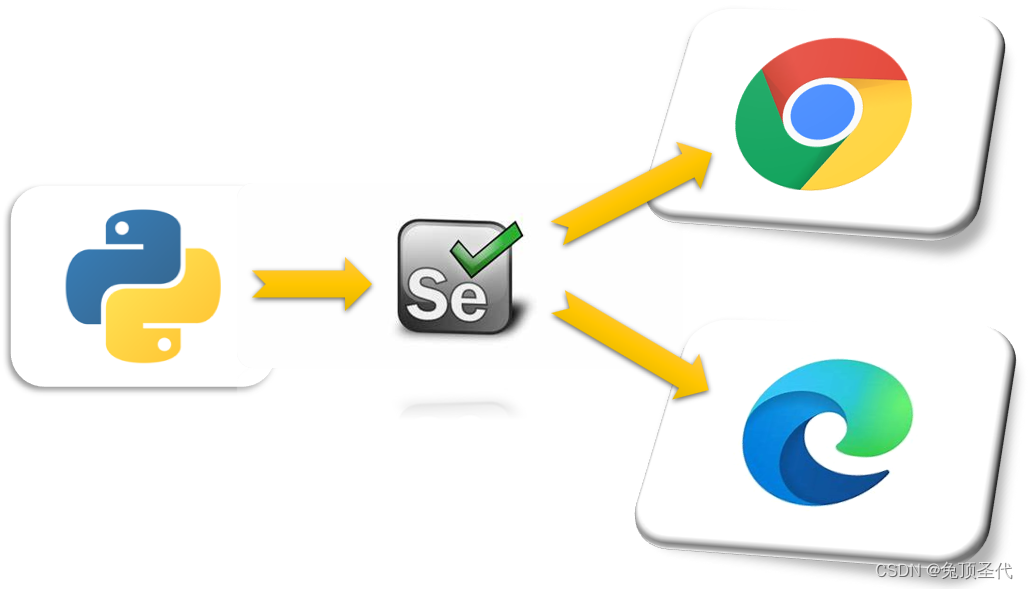
如图所示,通过Python来控制Selenium,然后让Selenium控制浏览器,操控浏览器,这样就实现了使用Python间接操控的浏览器。
1.2 浏览器的配置与驱动
1.2.1 浏览器的版本号
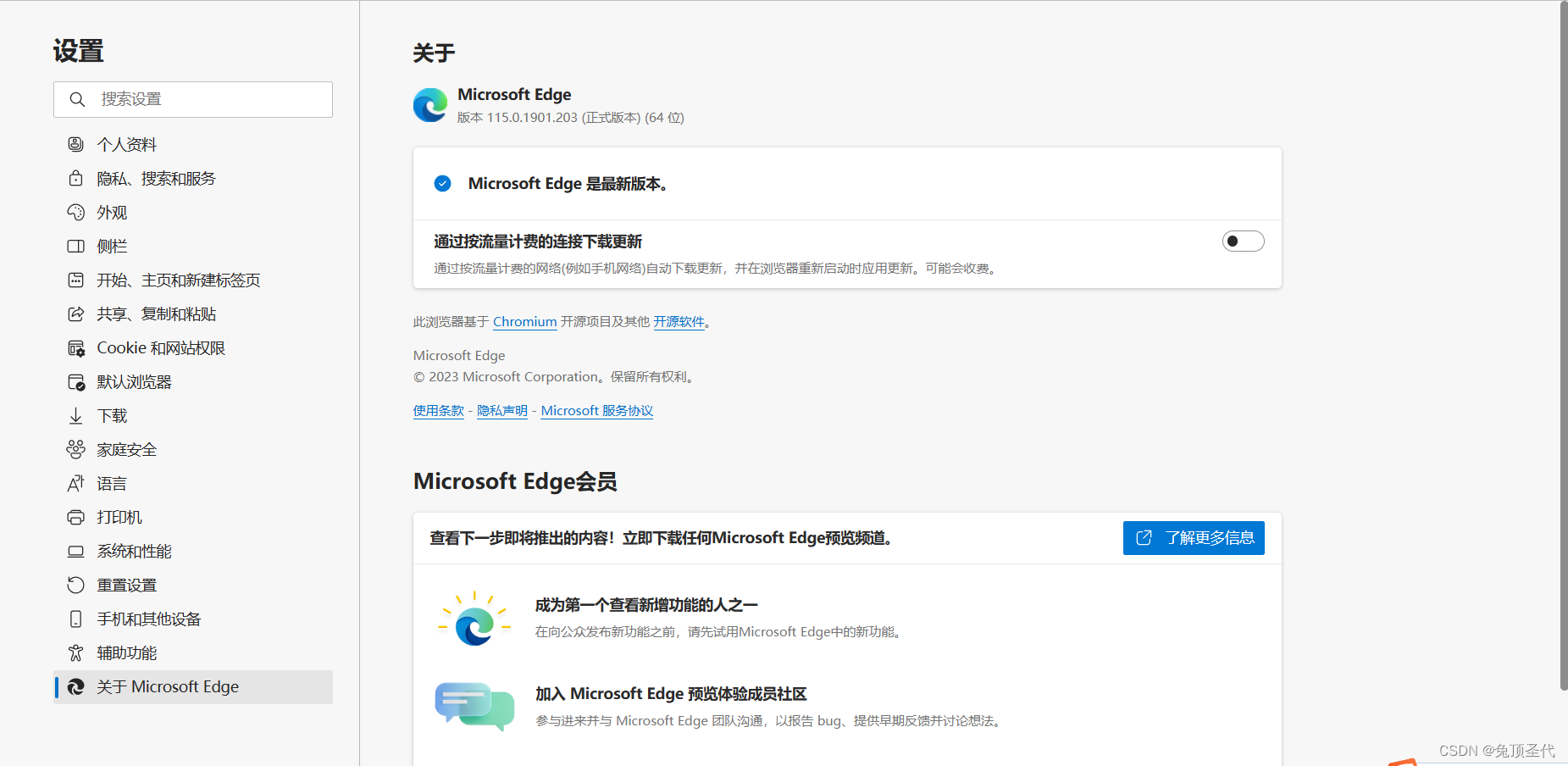
这里选择的是电脑自带的Microsoft Edge,打开设置—关于Microsoft Edge。查看Edge的版本115.0.1901.203。
1.2.2 浏览器的驱动
输入驱动器下载网址:Microsoft Edge WebDriver - Microsoft Edge Developer
根据自身浏览器版本下载对应的驱动器。
打开文件,把驱动器拖拽到PycharmProject文件夹中即可使用(这里拖拽到Python文件目录下也是可以的)
2. Selenium使用
2.1 快速入门
from selenium import webdriver
driver = webdriver.Edge()
driver.get('https://www.baidu.com/') # 打开百度首页
driver.quit() # 退出浏览器2.2 元素提取
通过selenium的基本使用可以简单定位元素和获取对应的数据,以下是定位元素的方法:
find_element(By.ID, 'id属性值') # (根据id属性值获取元素)
find_element(By.NAME, 'name属性值') # (根据标签的name属性) find_element(By.CLASS_NAME, '类属性值') #(根据类名获取元素) find_element(By.LINK_TEXT, '标签文本') #(根据标签的文本获取元素,精确定位) find_element(By.PARTIAL_LINK_TEXT, '标签文本') #(根据标签包含的文本获取元素,模糊定位)
find_element(By.TAG_NAME, '标签名') #(根据标签名获取元素)
find_element(By.XPATH, 'xpath语法') #(根据xpath获取元素) find_element(By.CSS_SELECTOR, 'css语法') # (根据css选择器获取元素)
find_element只会查找页面中符合条件的第一个节点,并返回。如果想获取多个元素可以在element后面加s,这样返回的是列表。

2.2.1 ID
id定位就是通过元素的id属性来定位元素,在html中元素的id是唯一的。
![]()
2.2.2 NAME
html规定name属性来指定元素名称,name的属性值在当前文档中可以不是唯一的,name定位就是根据name属性来定位,如果存在多个相同属性,那么默认定位到的是第一个。
![]()
2.2.3 CLASS_NAME
html规定class来指定元素的类名,class定位就是根据class属性来定位。在html中元素的class不是唯一的,是可以重复的。如果存在多个相同属性,那么默认定位到的是第一个。
![]()
2.2.4 LINK_TEXT
通过超链接的文本定位元素。link_text定位的是超链接的全部文本内容,所以匹配条件为绝对匹配(精确匹配)。

2.2.5 PARTIAL_LINK_TEXT
partial_link_text为link_text的补充,partial_link_text定位的是超链接的局部文本内容,所以匹配条件为部分匹配就满足条件,只截取一部分字符串,进行模糊匹配。

2.2.6 TAG_NAME
html通过tag来定义一类功能,比如html是网页的根标签,head是头部标签,title是网页自身的标题标签,body是主体标签。由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。
2.2.7 XPATH
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。
绝对路径定位存在很大的问题就是如果页面元素改变,Xpath会随着页面的布局的改变而改变,不利于维护。性能差,因为使用这种方式进行定位,Webdriver会将整个页面的所有元素进行扫描来找到我们所需的元素,所以当脚本中大量使用XPath方式定位,会大大降低脚本的执行速度。
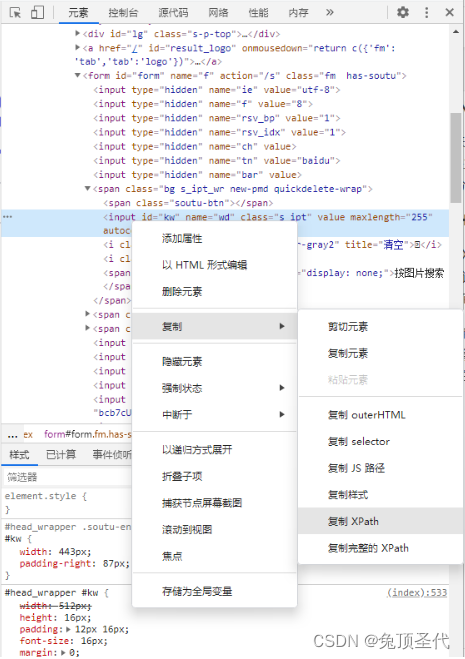
关于XPATH的具体用法。
2.2.8 CSS_SELECTOR
CSS Selector语法选择元素原理为通过css样式进行选择。CSS配合HTML来工作,它实现的原理是匹配对象的原理,而XPATH是配合XML工作,它实现的原理是遍历的原理,在两者设计上,CSS性能更为优秀。
关于CSS_SELECTOR的具体用法。
2.3 浏览器对象的常用方法
当我们通过selenium实例化一个浏览器对象时,可以针对此对象进行操作,常见的操作有:
| 函数 | 用法 |
| driver.get('url') | 根据url地址访问站点 |
| driver.page_source | 查看页面渲染之后的html数据 |
| driver.get_cookies() | 查看页面请求后生成的cookies,可以用此方法拿到加密的cookies |
| driver.current_url | 查看当前页面的url |
| driver.maximize_window() | 最大化浏览器 |
| driver.minimize_window() | 最小化浏览器 |
| driver.close() | 关闭当前页面,注意不是关闭整个浏览器 |
| driver.quit() | 关闭浏览器 |
| driver.back() | 回退到上一级页面 |
| driver.forward() | 前进到下一级页面 |
| switch_to() | 切换窗口以及嵌套网页 |
| click() | 执行点击操作 |
| text | 获取元素包含的文本内容 |
| get_attribute('属性名') | 获取元素的属性值 |
| send_keys('context') | 键入文本 |
| clear() | 清空输入框 |
关于close()和quit()的区别:
当使用close方法的时候,关闭当前窗口,如果它是当前打开的最后一个窗口,则退出浏览器,但是通过查看任务管理器发现,EdgeDriver进程仍存在内存中。如果使用quit方法,整个浏览器都直接关闭,EdgeDriver进程也会被结束。
3. Selenium进阶
3.1 进入嵌套页面
嵌套页面就是在一个HTML页面中嵌套了子页面。嵌套页面的表现形式以及在HTML源代码表现形式如下图:
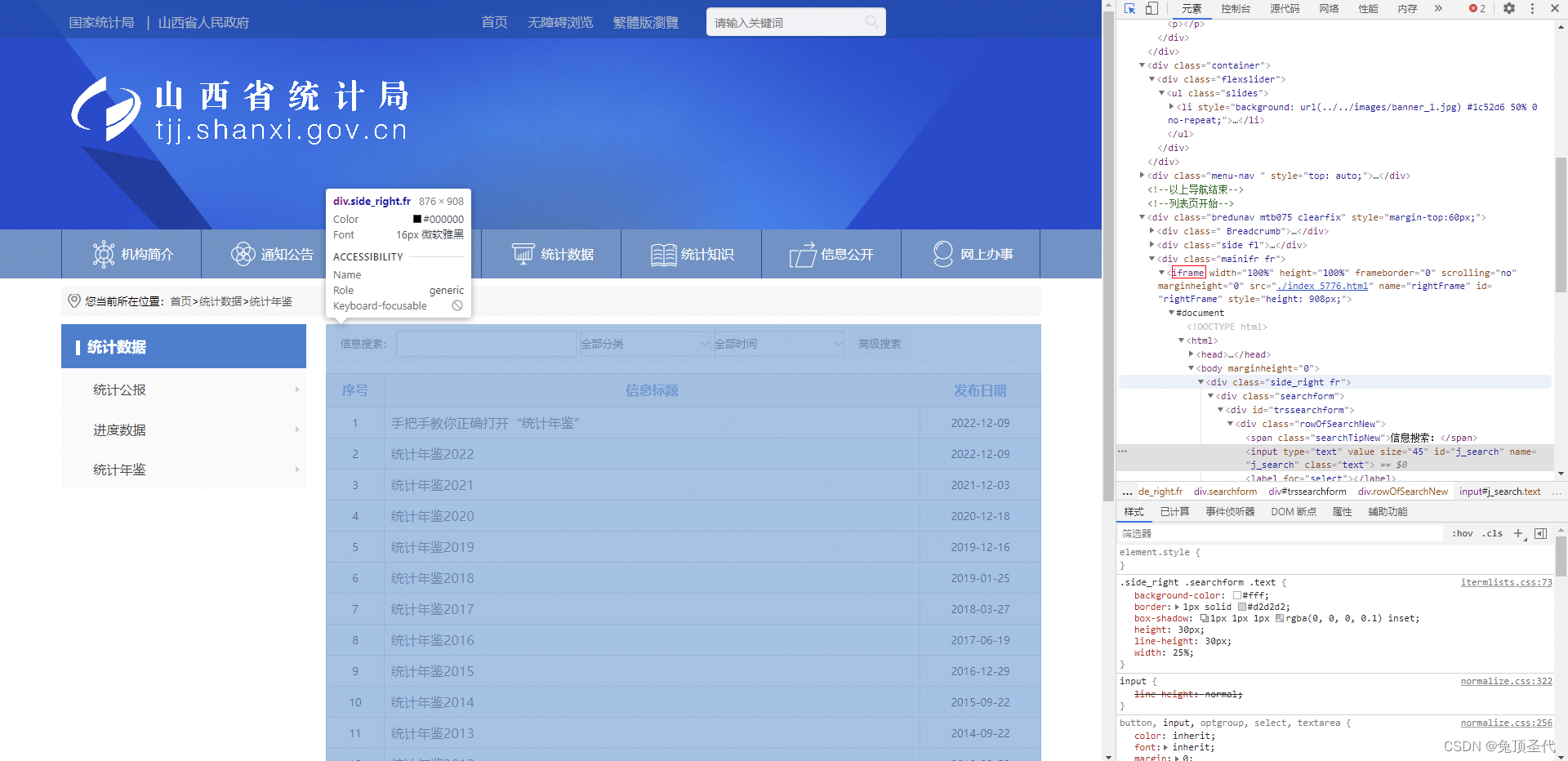
在我们使用selenium操作此类网页时一定要注意操作的页面是不是在嵌套页面,使用selenium获取嵌套页面的数据,首先我们要进入到嵌套页面里面,不然是获取不到数据的。进入嵌套页面可以使用实例化浏览器对象的switch_to.frame()方法。
如下代码的操作是向信息搜索中键入“统计年鉴2022”并点击高级搜索。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Edge()
driver.get('http://tjj.shanxi.gov.cn/tjsj/tjnj/')
driver.implicitly_wait(10)
driver.maximize_window()
driver.switch_to.frame(driver.find_element(By.XPATH, '//*[@id="rightFrame"]'))
driver.find_element(By.XPATH,'//*[@id="j_search"]').send_keys('统计年鉴2022')
driver.find_element(By.XPATH,'//*[@id="search_button"]').click()
time.sleep(5)
driver.quit()3.2 驱动器切换窗口
点击某个按钮后,页面是在一个新的浏览器中出现。例如运行3.1的代码后,此时的浏览器停留在了名为“山西省统计局”的页面上,但是selenium的driver还停留在旧页面上,导致无法操作。需要使用selenium的窗口切换功能,将driver切换到新页面之后再进行操作。
driver.switch_to.window(driver,window_handles[-1]) #切换到最新窗口里面的参数如果为0就是浏览器的第一个窗口,参数为1就是第二个,依此类推......
3.3 页面滑动操作
在使用selenium操作网页时,有的网页需要滚动鼠标滚轮下拉 页面,才会给我们加载页面的下部分数据。JavaScript 可以直接在浏览器中运行,那么这样的操作可以让selenium执行 JavaScript代码来完成。
- 向上/下拉动固定距离
js="var q=document.documentElement.scrollTop=750"
driver.execute_script(js)- 拉到底部
js = "window.scrollTo(0, document.body.scrollHeight)"
driver.execute_script(js)
- 拉到顶部
js = "window.scrollTo(0, 0)"
driver.execute_script(js)
3.4 鼠标动作链
有些时候,需要在页面上模拟一些鼠标操作,比如双击、右击、拖拽甚至按住不动等,可以通过导入 ActionChains 类来做到。
拖动鼠标:
ActionChains: ActionChains() --> 直接传入driver --> ActionChains(driver)实例化
perform --> 执行动作
drag_and_drop(source,target) 将source元素拖动到 元素被放置的位置target
| click() | 单击指定的元素 |
| click_and_hold() | 按住元素上的鼠标左键,并保持 |
| context_click() | 对元素执行上下文单击 |
| double_click() | 双击一个元素 |
这段程序就是将放灰色方块拖拽到深灰色方块的动作链,应用在滑动验证码中也是一样的道理
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains # 导入鼠标动作链功能
import time
driver = webdriver.Edge()
driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.switch_to.frame(0)
driver.maximize_window()
time.sleep(2) #窗口最大化后等待2s 目的为了观察更清晰
drag = driver.find_element(By.CSS_SELECTOR,'#draggable')
drop = driver.find_element(By.CSS_SELECTOR,'#droppable')
action = ActionChains(driver)
action.drag_and_drop(drag, drop)
action.perform()
time.sleep(5)
driver.quit()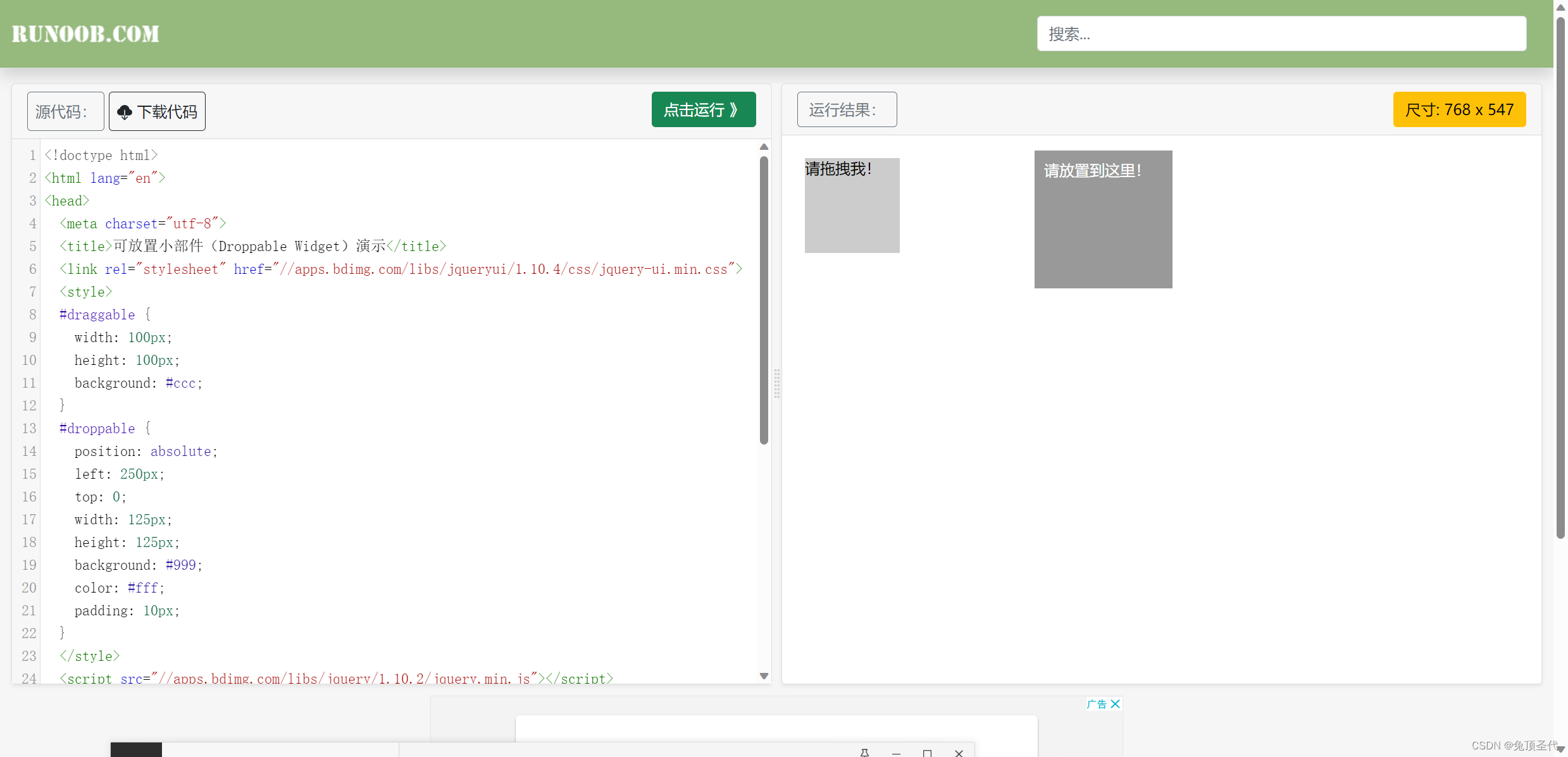
3.5 键盘事件
除了上述的selenium操作之外,键盘事件也是非常重要的,比 如我们需要按回车键,ctrl+c复制等等操作,都离不开键盘事件, 在selenium中,提供了Keys方法来供我们操作键盘。
首先必须先引用selenium中keys包:
from selenium.webdriver.common.keys import Keys
Key()类几乎提供所有按键的方法:
| 引用方法 | 对应事件 |
| send_keys(Keys.BACK_SPACE) | 删除键(BackSpace) |
| send_keys(Keys.SPACE) | 空格键(Space) |
| send_keys(Keys.TAB) | 制表键(Tab) |
| send_keys(Keys.ESCAPE) | 回退键(Esc) |
| send_keys(Keys.ENTER) | 回车键(Enter) |
| send_keys(Keys.CONTROL,'a') | 全选(Ctrl+A) |
| send_keys(Keys.CONTROL,'c') | 复制(Ctrl+C) |
| send_keys(Keys.CONTROL,'x') | 剪切(Ctrl+X) |
| send_keys(Keys.CONTROL,'v') | 粘贴(Ctrl+V) |
| send_keys(Keys.F1) | 键盘 F1 |
| send_keys(Keys.F12) | 键盘 F12 |
selenium所有的send_keys()方法都是基于元素操作的,没有元素无法操作。
3.6 选择标签下拉框
有时候会碰到标签的下拉框。直接点击下拉框中的选项不一定可行。Selenium专门提供了Select类来处理下拉框。 其实 WebDriver 中提供了一个叫 Select 的方法,可以帮助完成这些事情。
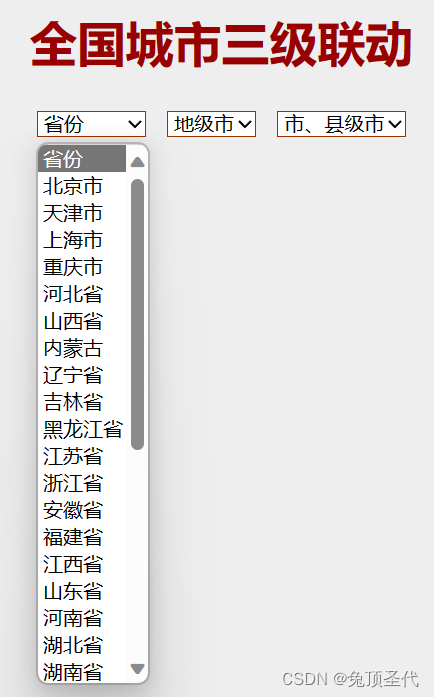
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
import time
driver = webdriver.Edge()
driver.get('https://www.jq22.com/demo/shengshiliandong/')
driver.implicitly_wait(10)
element = driver.find_element(By.CSS_SELECTOR,'#s_province')
select = Select(element)
time.sleep(3)
"""选择下拉框的方法"""
# 根据索引取下拉框, 从1开始
select.select_by_index(1)
time.sleep(3)
# 根据下拉框的 value 取值
select.select_by_value('河北省')
time.sleep(3)
# 根据下拉框标签的文本取下拉框
select.select_by_visible_text('吉林省')
time.sleep(3)
driver.quit()4.Selenium总结
优点:可以模拟浏览器,相当于用户用程序调动浏览器,让浏览器打开需要爬取的页面,可以大量避免被封,因为我们在用Python的requets库发出网络情况时候,您必须先构造http请求头。但是有些网站反爬很严格,可以直接识别出来您当前的访问是否正常用户行为。所以如果在用request请求时被目标网站反爬识别,导致无法爬取的话,那么这个时候只有使用这个selenium框架就是最好技术选择方式。
缺点:速度慢,适合每天爬取数据量要求不高的爬虫工作。因为selenium框架是必须要打开浏览器,然后模拟点击网页,无法大量爬取数据。















 6109
6109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









