



常见电平协议
5V TTL电平:2.4~2.5V为高电平(逻辑1)。0~0.5V为低电平(逻辑0)
RS232:-15 ~ -3V为高电平(逻辑1),+3 ~ +15V为低电平(逻辑0)
通信协议
IIC协议
IIC为什么要加上拉电阻?
- 实现线与逻辑:IIC中多个设备共享同一条总线,上拉电阻可以将总线拉至高电平(空闲状态),任何设备都可以通过将总线拉低来发送信号。
- IIC总线的两个引脚都配置为开漏输出,开漏输出无法输出高电平,只能输出低电平,上拉电阻提供了将总线拉回高电平的能力。加入上拉电阻后可以让引脚输出高电平。
- 防止总线冲突:当多个设备同时访问总线,上拉电阻配合开漏输出可以防止短路。
- 定义总线空闲状态:上拉电阻确保总线在无设备通信时保持高电平,也就是空闲状态。
经典的上拉电阻阻值为4.7KΩ。
IIC为什么要使用开漏输出?
- 实现线与功能。开漏输出允许多个设备同时共享同一条总线而不造成冲突。
- 电平转换:不同电压域的设备可以在同一总线上通信,只需使用与最高电压匹配的上拉电阻。
- 时钟同步:开漏结构可以使从设备通过拉低SCL线延长时钟周期,保证较慢的从设备与主设备同步。
- 仲裁机制:在多主机环境中,开漏结构可以实现无损仲裁(低电平优先)
IIC的地址位数是多少
一般是7位地址格式,传输时占一个字节,7位地址+1位读写位。理论上可用的是127个(2^7-1),0x00地址保留。实际可用的是126个,0x00和0x7F地址保留。
可拓展10位地址格式。理论上可用也是1023(2^10-1),0x00地址保留
IIC有几根线?
两根线,SCL和SDA。
IIC的通信速率有哪些?
标准模式100Kbps。
快速模式400Kbps。
更快的有1Mbps。
IIC总线处于空闲状态时,SCL和SDA都需要处于高电平状态。
IIC可以挂载多个设备,这个时候需要区分是谁在使用IIC总线,开漏输出可实现线与功能,0 & 1 & 0 = 0。
如果使用推挽输出,当一个设备输出高电平,一个设备输出低电平时,则会导致短路烧毁设备。
IIC时序
IIC通信总共有三种信号:开始信号,停止信号,应答信号。
开始信号:SCL为高电平时,SDA从高电平变为低电平,即出现下降沿为开始。
停止信号:SCL为高电平时,SDA从低电平变为高电平,即出现上升沿为结束。
读取数据时,SCL为高电平时,SDA必须为稳定电平。数据按MSB(高位优先)优先传输。
应答机制:每传输8位数据,接收方就要给出ACK应答位(低电平)表示成功接收。NACK则表示接收失败。
如何计算IIC总线上拉电阻的阻值?
R:上拉电阻阻值。Tr:要求的上升时间。Cb:总线电容。
计算公式:后续补上。
实际选择建议:低速场景,4.7KΩ - 10KΩ。
标准模式,4.7KΩ。快速模式,2.2KΩ - 4.7KΩ。高速模式:1KΩ - 2.2KΩ。
硬件IIC和软件IIC的区别
可以从实现方式,速度,稳定性,灵活性方面讨论。
实现方式上的区别。硬件IIC:通过MCU内部的专用硬件模块实现时序,软件只负责发出命令。软件IIC:通过控制GPIO来模拟IIC的SCL和SDA信号来产生IIC的时序。
速度上的区别。硬件IIC速度比较快。软件IIC速度比较慢,而且会占用CPU
稳定性上的区别。硬件IIC稳定性较高。软件IIC稳定性相对较低。
灵活性上,软件IIC的IO口可以随意设置,更加灵活,而硬件IIC的IO口是固定的。
IIC如何实现多主机通信?
1. 总线仲裁。采用低电平优先原则。总线采用线与逻辑,谁先发送低电平,谁将先获得总线控制权。
2. 时钟同步。因为是线与逻辑,只有当所有设备同时释放SCL时,总线才会被拉高。因此所有设备会以最慢的设备的时钟速率运行,以保证时钟同步。
3. 冲突检测。主机发送每一位数据时都会检查SDA线实际电平,如果检测到的电平与期望发送的不同,则失去仲裁权。
IIC的时钟同步和时钟拉伸是什么?
时钟同步:I2C总线上的SCL线是所有设备逻辑与的结果。当任一设备将SCL拉低,总线SCL就为低电平。只有当所有设备都释放SCL(高阻态),SCL才会变为高电平,这确保了最慢的设备也能跟上通信节奏。
时钟拉伸:从设备可以通过持续拉低SCL来延长时钟周期。这样从设备可以有更多时间处理数据。主设备必须等待SCL实际变为高电平后才能继续。这是I2C协议中从设备控制通信速度的机制。
I2C通信中常见的问题及解决方案?
日后再补充。
总线死锁,症状:SDA或SCL被某个设备一直拉低。解决方案: 软件复位:主机产生9个时钟脉冲,尝试完成被中断的传输。硬件复位:复位所有I2C设备。电源循环:关闭再打开电源
地址冲突,症状:多个设备使用相同地址解决方案: 使用带地址选择引脚的器件使用I2C地址转换器使用多总线设计
时序问题,症状:高速通信时数据错误。解决方案: 减小上拉电阻值(注意功耗增加)减少总线电容(缩短线长、减少设备数量)降低通信速率
噪声干扰,症状:通信不稳定,偶发错误解决方案: 使用屏蔽线缆增加滤波电容优化PCB布局,避免I2C线与高速信号线并行
SPI协议
SPI的基本原理和特点
一种高速,全双工,同步的串行通讯。总共有4根通讯线。
特点:
- 同步通信
- 全双工传输
- 一主多从,可连接多个从机设备
- 传输速率高,可达几十MHz。
SPI有几种工作模式?有什么区别?
工作模式有4种(2^2 = 4),由时钟极性CPOL和时钟相位CPHA决定。
时钟极性CPOL决定SCLK空闲时的电平。时钟相位CPHA决定在几个时钟边沿采样。
以工作模式0举例:CPOL = 0,CPHA = 0
SCLK时钟空闲时为低电平,数据在时钟上升沿采集。(第一个时钟边沿采集)
以此类推,CPOL = 1,CPHA = 1,SCLK空闲时为高电平,数据在时钟下降沿采集。(第二个时钟边沿采集)
SPI的有几根线,可以去除几根线
SPI总共有4根线。
SCLK:时钟线,用于同步数据传输时的时序控制
MOSI:主设备输出,从设备输入线。
MISO:主设备输入,从设备输出线。
CS:片选线,用于选择对应的从机设备。
如果不需要双向通信,MOSI,MISO其中一根线可以去除。如果是一对一通信,CS片选线也可以去除。最少两根线即可。
SPI和IIC的寻址区别
SPI引脚:MISO,MOSI,SCLK,
CS:片选引脚,选择对应的设备进行通信。
IIC寻址方式:
SDA,SCL。通过7位或10位的从机地址进行寻址。
SPI与IIC,UART相比有哪些优缺点?
优点:
- SPI速度快,可达几十MHZ。
- 全双工通信,效率高。
缺点:
- 需要的信号线多,4根。
- 无应答机制,无法确认数据是否正确接收。
- 通信距离有限
- 多个从设备时需要多个片选线,占用IO多
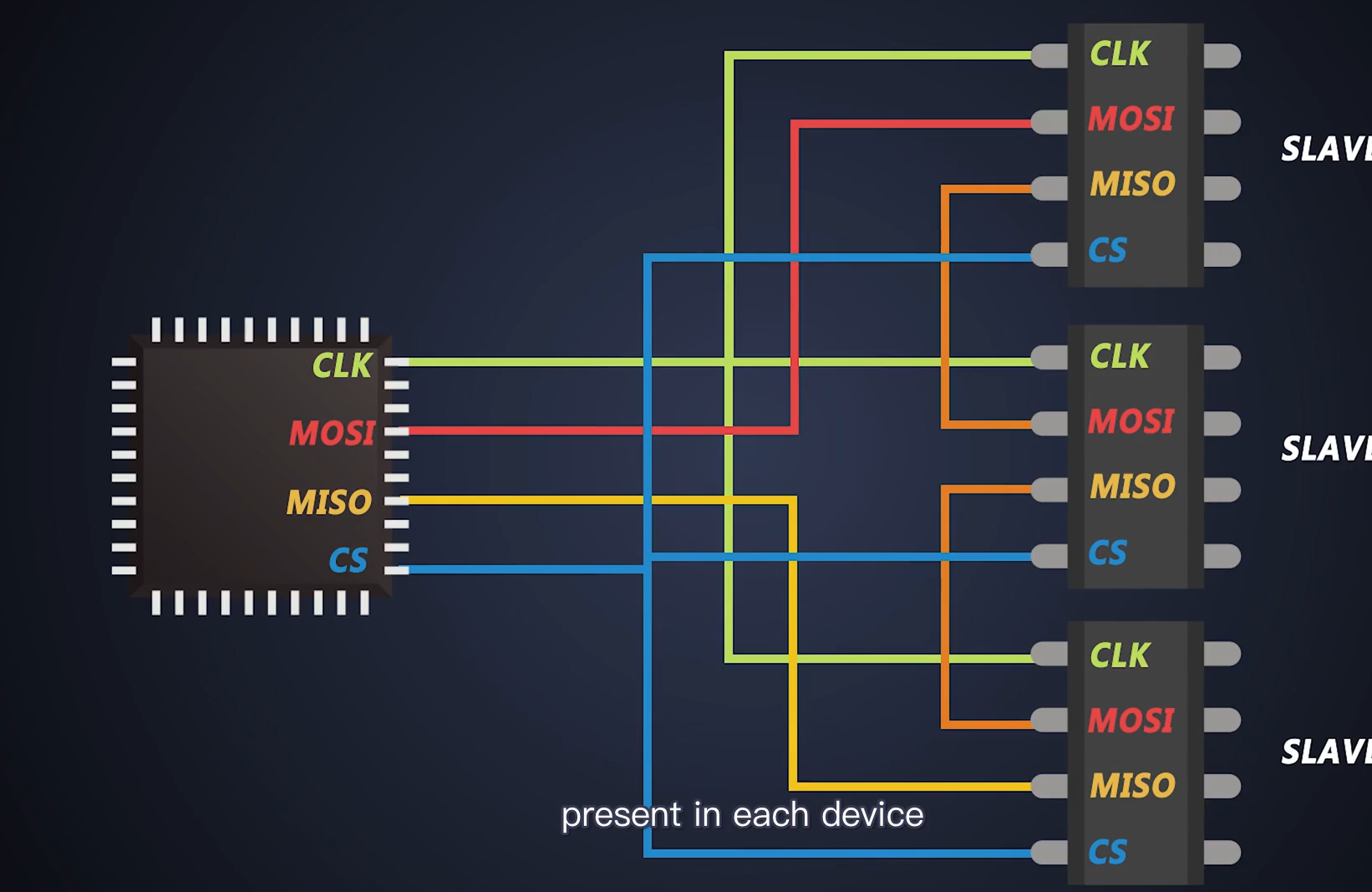
SPI的菊花链和独立模式
SPI的菊花链模式:共用一根片选线, 数据经过一个设备后再传递给下一个设备。
SPI的独立模式:每个从设备都有自己的片选线。
SPI菊花链的连接图
DualSPI和QualSPI
MOSI,MISO设置为双向数据信号。
DualSPI支持两根信号线同时传输,等效时钟工作频率翻倍。
QualSPI支持四根信号线同时传输,等效时钟工作频率翻四倍。

SPI的传输流程
首先把对应从设备的片选线拉低,主机发出时钟信号,然后根据设置的工作模式,在特定的时钟边沿进行采样。主机先发起通讯,写入一字节数据。这个字节数据的意义主要是取决于目标设备,常见的7位地址+1位读写位。然后从机就会在特定的时钟边沿通过MISO发出数据给主机。
传输数据过程,是MSB高位优先,发送到移位寄存器。
传输完成后,主设备拉高片选先,结束通信。
UART协议
UART通信需要哪些信号线,每条线的作用是什么?
TX:发送数据。
RX:接收数据。
UART的帧格式是什么?
起始位:1位。
数据位:5-9位。通常是8位,LSB(先发送低位)
校验位:0-1位,可选。
停止位:1-2位,固定为高电平。
UART常用的波特率有哪些?如何选择合适的波特率
常用波特率:
- 9600bps,低速通信,稳定性好。
- 115200bps,常用高速率。
选择考虑因素
- 通信距离:距离越长,波特率越低。
- 抗干扰要求:波特率越低,抗干扰性越好。
UART,IIC,SPI的区别
通信方式的区别
UART:异步通信的方式,没有时钟线
IIC和SPI都是同步通信,有时钟线SCL,SCLK
接线的区别
UART:TX,RX
SPI:SCLK(时钟线),CS(片选引脚),MOSI(主机输出从机输入),MISO(主机输入从机输出)
IIC:SDA(数据线),SCL(时钟线)
设备数量
UART:一对一通信
IIC:多主机和多从机之间的通信
SPI:一主机多从机
传输速度
UART:115200,9600
IIC:标准模式(100kbps),快速模式(400kbps),高速模式(3.4Mbps)
工作模式
UART:全双工,半双工
IIC:半双工,具备应答机制
SPI:全双工,不具备应答机制
CAN通信
异步串行。
CAN总线的数据帧类型有哪些?各自特点是什么?
数据帧,遥控帧,错误帧,过载帧,间隔帧。
标准格式和拓展格式的区别
标准格式ID为11位,范围0x000-0x7FF。数据段长度最大八字节。
拓展格式ID为29位,范围0x00000000-0x1FFFFFFF。数据段长度最大64字节。
CAN通信的数据段包含多少位()?标准帧多少位
标准帧数据段最多包含8字节,拓展帧数据段最大可包含64字节。
CAN通信协议和UART,I2C、SPI通信协议的比较
UART:全双工,异步,点对点通信。适用于两个设备互相通信。
I2C:半双工,同步,一主多从
SPI:全双工,同步,一主多从(高速)
CAN:半双工,异步,多个主控互相通信。
CAN通信如何配置?
首先是先配置好波特率,
根据需求进行模式的选择,一般,测试用回环模式,多设备通信用正常模式。
然后是根据需要接收的报文进行过滤器的配置。根据想要的报文数量确定是列表模式还是屏蔽模式。
CAN总线的仲裁机制是如何工作的?
CAN总线采用非破坏性总线仲裁机制。
先判断优先级,ID越小,优先级越高。发送节点在发送数据时,通过线与机制,逐位比较ID。
当节点发送隐性位1,但是总线为显性0时,则自动退出仲裁并转为接收状态,不会破坏高优先级的消息传输。
CAN总线的仲裁机制(非破坏性仲裁)
多个节点同时发送数据时,通过标识符优先级竞争总线。
标识符ID越小。优先级越高。
节点在发送时同时监听总线,若发现更高优先级信号,则自动退出发送,等待总线空闲后重试。
CAN报文怎么发送的
8. CAN有用中断吗
对can的理解
多主通信:任何节点可主动发送数据。
非破坏性仲裁:ID 越小优先级越高,仲裁时不破坏报文。
差分信号:抗干扰能力强,适合工业环境。
错误检测与恢复:支持 CRC 校验、自动重传。
应用:汽车电子(如 ECU 通信)、工业自动化。
CAN通信的数据段包含多少位?标准帧多少位
can通信的话怎么用的,是调库吗
RS485
传输距离远,连接简单。
支持一对多
如果stm32要用RS485通信,则要使用SP3485芯片,将TTL电平进行转换。
RS232和RS485的区别
RS232
全双工通信。信号线:TX,RX,GND。
用于点对点的通信。传输距离较短(15m左右)

RS485
半双工通信。只有两根线。采用差分传输。RS485抗干扰能力比RS232强(使用了双绞线将两根信号线缠绕在一起),传输距离远(1.5Km)
可用于一对多,多对多通信。传输速率上,RS485比RS232快。

UART和USART的区别
UART
- 通信方式:仅支持异步通信,即发送端和接收端不使用统一的时钟信号。
- 时钟信号:无时钟信号,数据帧通过预定义的波特率进行同步。
- 工作原理:发送端在开始位后发送数据,接收端在没有时钟的情况下依赖波特率进行解释数据。
- 应用场景:适用于点对点的低速数据通信。
USART
- 通信方式:支持同步和异步通信。异步模式依靠波特率同步。同步模式依靠发送端和接收端共享时钟信号,数据和时钟同步传输。
- 时钟信号:同步模式下使用时钟信号进行同步。
- 工作原理:异步模式与UART相同。同步模式下,发送和接收数据与时钟信号严格同步,提高通信的准确性和速度。
- 应用场景:适用于需要高速和高可靠性的串行通信,以及需要同步时钟的场合。
异步通信和同步通信
异步通信定义:数据的发送和接收是独立进行的,发送方和接收方不需要同时进行操作,发送方可以在发送完完整数据后继续执行其他任务,接收方是在数据到达后进行处理。
异步通信特点:非阻塞,无需等待响应,适合用于延迟较大的场景。
同步通信定义:发送方在发送数据后会等待接收方的响应,才能继续执行,发送方和接收方必须在相同的时间节点进行操作。如IIC中要发送对应的应答信号,ACK。
同步通信特点:阻塞,需要等待响应,适合用于延迟较小的场景。
什么是交叉编译
交叉编译指的是在一个平台上编译另一个平台的可执行程序。
在Ubuntu上使用交叉编译工具链将.c转化为可执行程序再烧录到ARM开发板上。
MCU相关
STM32的启动流程
从0x0处取值,赋值给栈顶指针SP。然后取0x4处的值,给PC指针,stm32会根据0x4的这个地址的值跳转到其所对应的地址去执行指令。根据BOOT的引脚,地址的跳转一般有三种情况,主闪存启动,系统存储器启动,SRAM启动。
主闪存启动也就是Flash memory启动。把0x0000 0000 映射成0x0800 0000。
具体的表现大概就是,上电后,执行一个复位中断,运行SystemInit初始化函数,执行__main函数,然后运行用户main()。
STM32的启动方式
一般而言,STM32有三种启动方式。可通过BOOT0,与BOOT1引脚来改变启动方式。
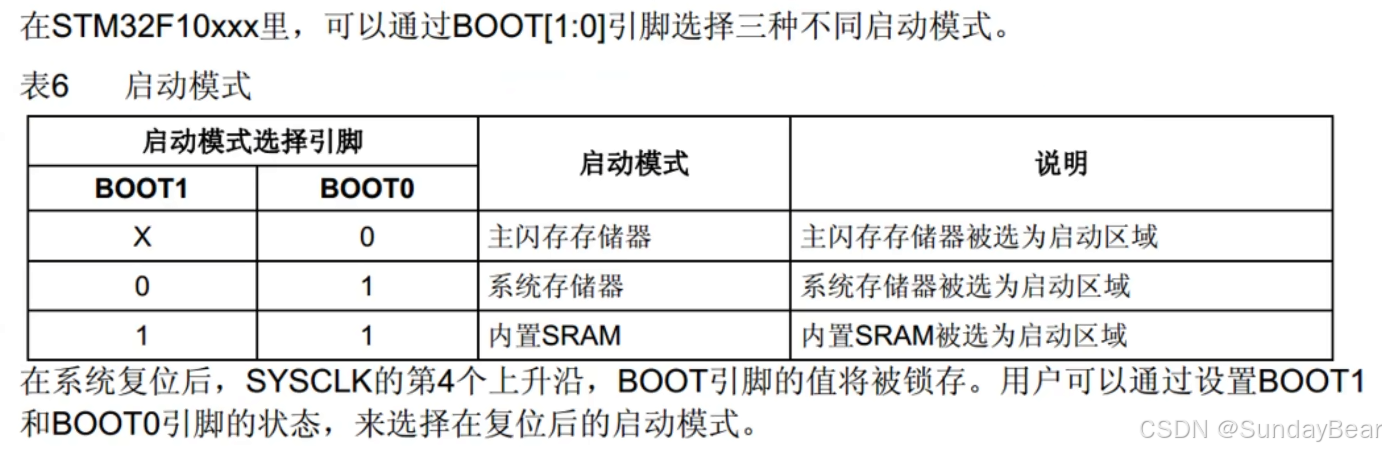
程序都是从0地址开始执行的,,到达0地址后,又会根据BOOT引脚的不同,映射到不同的位置执行程序。
如果设置了主闪存启动,则会映射到Flash memory执行程序。通过0x0800 0000开始就是存放代码的位置。
如果设置了系统存储器启动,则会映射到System memory执行程序。System memory存放着出厂自带的boot loader程序,是用于串口下载的引导程序。所以如果从系统存储器启动,其实是执行串口下载程序,boot loader会将下载的程序存放进Flash。下载完程序后,再设置会主闪存启动,这样复位后就可以正常启动程序了。
如果设置了内置SRAM启动,则会映射到SRAM执行程序。
小结
一般我们默认主闪存启动,也就是利用ST-Link等下载器进行下载程序。
系统存储器模式则是用于串口下载,我们就可以省去买下载器的钱了(doge)。
SRAM启动模式用于调试程序。
什么是中断
暂停当前任务,去处理更加紧急的任务。当中断发生时,处理器会停止当前执行的代码,保持现场,并跳转到中断处理函数中去执行,当执行完成后又返回现场继续执行。
什么是看门狗定时器
概念的简单理解:看门狗定时器是一个硬件计计时器,要求系统在规定时间内定期对其进行复位(喂狗),如果没有喂狗,定时器溢出后会触发预定的响应,例如系统复位或重启。
作用:防止系统长时间卡死。
提高系统可靠性。
系统卡死时,恢复程序运行。
GPIO工作模式
共有八种模式:
输出分为推挽输出,开漏输出,复用推挽输出,复用开漏输出。复用功能:GPIO引脚用于外设功能,如UART,SPI,PWM等。
输入分为上拉输入,下拉输入,浮空输入,模拟输入。
推挽输出(最常用):
对高低电平均有驱动能力,不用设置上拉电阻。可简单理解既可输出高电平,也可输出低电平。
输出可1可0。
开漏输出:
只对低电平有驱动能力,想要输出高电平必须设置上拉电阻。简单理解,只能输出低电平,无法输出高电平。只能输出0。
上拉输入:
可读取引脚电平,内部外接上拉电阻,悬空时默认高电平。
下拉输入:
可读取引脚电平,内部外接下拉电阻,悬空时默认低电平。
浮空输入:
可读取引脚电平,若引脚悬空,电平为不确定状态。
模拟输入:
GPIO无效,引脚直接接入内部ADC
什么是DMA
DMA是一种无需cpu参与就可以让外设和系统之间的内存进行双向的数据传递。
DMA:直接内存存取器。可以减轻CPU的负担,提高系统的运行效率。
bootloader
如何设置app程序的中断向量偏移表?
通过设置中断向量表偏移寄存器SCB,设置中断向量表的偏移量。
如何跳转到app的主函数?
先获取app程序的复位向量地址,然后通过汇编指令设置栈顶指针MSP,之后执行跳转。
中断优先级怎么分配?
中断优先级分为抢占优先级和响应优先级。抢占优先级高的中断可以打断抢占优先级低的中断,而响应优先级则是多个相同抢占优先级中断发生时起作用,响应等级越高,越先响应。
实际项目中通常利用NVIC控制器设置相关的中断的抢占和响应优先级。
芯片如何选型?
常见思路:IO口的数量;预估代码量大小(是否涉及复杂的算法和协议),选择需要的flash大小
MQTT的通信过程
-
创建客户端
-
指定IP地址和端口号
-
进行连接
-
发布主题或者订阅主题
-
数据传输
-
断开连接
C语言相关
一个.c文件转化为可执行程序的过程
- 预处理。将头文件宏定义展开,生成没有注释的源代码。.i
- 编译。将预处理得到的源代码转换成汇编代码。.s
- 汇编。将汇编的代码转换为机器码生成的对应目标文件。.o
- 链接。将所有.o文件链接成一个可执行程序
环形缓冲区
环形缓冲区经常被用于串口通信,socket,使用环形缓冲区可以将数据保存下来,使用R,W指针来进行数据的操作。
#include <stdio.h>
#include <stdbool.h>
#include <string.h>
#define BUFFER_SIZE 10 // 定义缓冲区大小
typedef struct {
char buffer[BUFFER_SIZE]; // 缓冲区数组
int head; // 缓冲区头部索引
int tail; // 缓冲区尾部索引
} RingBuffer;
// 初始化环形缓冲区
void initBuffer(RingBuffer *rb) {
rb->head = 0;
rb->tail = 0;
memset(rb->buffer, 0, BUFFER_SIZE); // 清空缓冲区
}
// 检查环形缓冲区是否为空
bool isEmpty(RingBuffer *rb) {
return rb->head == rb->tail;
}
// 检查环形缓冲区是否已满
bool isFull(RingBuffer *rb) {
return (rb->tail + 1) % BUFFER_SIZE == rb->head;
}
// 向环形缓冲区写入数据
bool writeBuffer(RingBuffer *rb, char data) {
if (isFull(rb)) {
return false; // 缓冲区满,无法写入
}
rb->buffer[rb->tail] = data;
rb->tail = (rb->tail + 1) % BUFFER_SIZE;
return true;
}
// 从环形缓冲区读取数据
bool readBuffer(RingBuffer *rb, char *data) {
if (isEmpty(rb)) {
return false; // 缓冲区空,无法读取
}
*data = rb->buffer[rb->head];
rb->head = (rb->head + 1) % BUFFER_SIZE;
return true;
}
int main() {
RingBuffer rb;
initBuffer(&rb);
// 写入数据
char dataToWrite = 'A';
writeBuffer(&rb, dataToWrite);
printf("写入: %c\n", dataToWrite);
// 读取数据
char dataRead;
if (readBuffer(&rb, &dataRead)) {
printf("读取: %c\n", dataRead);
} else {
printf("缓冲区为空,无法读取\n");
}
return 0;
}
什么是FIFO(环形缓冲区)
可以使用软件实现,一个环形缓冲区。
使用场景:串口通信,数据采集,DMA,音频处理。
先进先出,使用FIFO可以减轻CPU的负担。
大小端的概念和判断
概念:指的是多字节的数据再内存中的存储顺序方式,在不同的计算机中会使用不同的字节顺序表示数据。
大端存储:高字节在低地址,低字节在高地址。
小端存储:高字节在高地址,低字节在低地址。
全局变量和静态变量的存储位置
静态区一般包含data段,bss段以及常量区。
已初始化的全局变量和静态变量(包括静态局部和静态全局)都在data段。未初始化的全局变量和静态变量都在bss段。常量区用于存储常量数据。
内存映射的原理:
-
将一块内存空间映射到不同的进程空间中
数组和链表的区别
- 数组内存连续,链表内存不连续。
- 数组访问速度比链表快
- 链表增删操作比数组快
指针和数组
- 数组是一块连续的内存空间,大小在编译时确定,利用下标访问元素。
- 而指针是一个变量,存的是地址值,大小固定,可以指定不同类型的数据,通过解引用操作访问内存中的数据。
指针函数和函数指针
指针函数是函数。一个返回值为指针的函数。
函数指针是指针,定义为指向函数的指针。
区别
指针函数是函数,它返回一个指针。
函数指针是指针,它指向一个函数。
示例代码
#include <stdio.h>
#include <stdlib.h>
// 定义一个指针函数,返回一个指向整数的指针
int* pointerFunction(int num) {
// 分配内存
int* p = (int*)malloc(sizeof(int)); // 动态分配内存
if (p != NULL) { // 检查内存分配是否成功
*p = num; // 将num的值存储在分配的内存中
}
return p; // 返回指向这块内存的指针
}
// 定义一个函数,用于释放内存
void freeMemory(int** ptr) {
if (*ptr != NULL) { // 检查指针是否指向有效的内存
free(*ptr); // 释放指针指向的内存
*ptr = NULL; // 将指针设置为NULL,防止野指针
}
}
int main() {
int* ptr = NULL; // 初始化指针为NULL
// 调用指针函数,并接收返回的指针
ptr = pointerFunction(100);
if (ptr != NULL) {
printf("Value: %d\n", *ptr); // 输出指针指向的值
}
// 定义一个函数指针
void (*funcPtr)(int**);
funcPtr = freeMemory; // 将函数的地址赋给函数指针
// 通过函数指针调用函数
funcPtr(&ptr); // 传递ptr的地址
// 检查内存是否已释放
if (ptr == NULL) {
printf("Memory has been freed.\n");
}
return 0;
}
指针的大小
指针的大小和编译器的位数有关。在32bit位系统下指针的大小是4个字节(32bit = 4byte),64bit位系统下指针的大小则是8个字节(64bit = 8byte)。
指针的大小是固定的,和指针的类型没有关系。
野指针
野指针定义:指向不可用内存的指针。
为什么会产生野指针?
1.当指针被创建时,没有给指针赋值。
2.当指针被free或delete后,没有把指针赋值为NULL,这个时候指针也为野指针。
3.当指针越界的时候也算野指针。
数组和链表的区别
数组的地址空间是连续的,而链表的地址空间是不连续的。
数组的访问速度比较快。数组直接通过下表访问,链表则需要遍历。
链表增删改查的速度比数组快。
宏函数注意点
因为宏定义是直接替换,并不会判断运算符之间的执行顺序,变量之间建议加括号。
//宏函数
#define MIN(a, b) (a)<=(b)? (a) : (b)
#include< >和#include" "的区别
使用#include< >,系统会从标准库路径中去搜索,对于搜索标准库中的文件速度会比较快。
使用#include" ",系统会从用户工作路径中搜索,对于自己定义的文件速度会比较快。
全局变量和局部变量的区别
1.作用域。全局变量的作用域是程序块,局部变量的作用域是当前函数内部。
2.生命周期。全局变量的生命周期是整个程序。 局部变量的生命周期是当前函数。
3.存储方式。局部变量是存储在栈里面的,全局变量是存储在全局数据区中的。
4.使用方式不同,全局变量在程序的各个部分都可以使用到、局部变量只能在函数的内部去使用。
如何防止重复引用头文件
使用预处理指令
#ifndefHEADER_LFILE_NAME_H
#defineHEADER_FILE_NAME_H||头文件内容
#endif//HEADER_FILE_NAME_H
使用#pragmaonce
#define和typedef的区别
1.#define是一个预处理指令,typedef是一个关键字
2.#define不会做正确性检查,直接进行替换。typedef会做正确性检查。
3.define没有作用域的限制,typedef是有作用域的限制。
#define 定义的宏没有作用域限制,它们在整个源文件中都是可见的。
typedef 定义的类型别名遵循C语言的作用域规则。
4.#define通常用于定义常量和宏,typedef则用于定义类型别名。
define和const
define是预处理指令,在预处理阶段执行。常用于定义常量和宏,条件编译,宏函数。define只进行文本替换,没有类型检查。
const是c和c++关键字,用于创建具有常量值的变量,本质是只读变量。
有时在函数的形参中,如果我们不希望后续传入的参数被人修改,可以使用对函数的形参使用const修饰。
static关键字作用
-
限定作用域,定义的静态函数或局部变量只能在当前文件中使用。
-
修饰变量时,变量存储在静态存储区,不随着函数的调用结束或块的结束而销毁,存在于程序的整个生命周期。即生命周期变长。
-
在函数体中使用static去定义变量那么这个变量只会被初始化一次。
-
在函数内部定义的静态变量无法被其他函数使用。
修饰函数中的局部变量时,会延长其生命周期至程序结束,且变量只初始化一次。常用于状态机编程、计数器等场景,这可以避免定义过多的局部变量。
修饰函数时,让函数的作用域仅限当前文件,外部文件无法调用。常用于隐藏模块的内部实现,防止外部调用,增加封装性。
修饰全局变量时,限制变量的作用域仅限当前文件,外部文件无法使用该变量,常用于避免全局变量的命名冲突或不必要的修改,增加模块的独立性。
小结:
限定作用域,加长生命周期,只初始化一次,无法被其他函数调用。
volatile关键字作用
- 指示编译器不要对其所修饰的变量进行优化,确保每次访问这个变量的时候都要访问主存来获取最新的值,而不是从寄存器或者缓存中读。
- 由于CPU可能乱序执行的原因,volatile只保证所修饰变量的可见性,而不能保证原子性。
- 具体的使用场景包括:多线程操作同一变量;读写硬件寄存器;中断服务程序中变量的赋值操作。
extern 关键字
- 告诉编译器这个函数实现或者变量的定义在别的文件实现。
- 可以实现跨文件使用全局变量和函数
内存泄漏
内存泄漏指的是程序运行的时候,动态分配的空间没有被回收或者是释放,导致这个内存空间还占据着系统的资源。
内存对齐
内存对齐是指在内存中分配变量或数据结构时,按照某个数(通常是2、4、8等)的倍数进行对齐。这样做可以提高内存访问的效率,因为现代的CPU访问对齐的内存地址比访问非对齐的内存地址要快。
代码示例1
#include <stdio.h>
// 定义一个结构体,用于演示内存对齐
struct MyStruct {
char a; // 占用1字节
double b; // 占用8字节(大多数平台上double占用8字节)
};
int main() {
// 定义一个结构体变量
struct MyStruct s;
// 打印结构体变量的起始地址
printf("Address of s: %p\n", (void*)&s);
// 打印结构体变量中成员a和b的地址
printf("Address of s.a: %p\n", (void*)&s.a);
printf("Address of s.b: %p\n", (void*)&s.b);
// 计算结构体的大小
printf("Size of MyStruct: %zu bytes\n", sizeof(struct MyStruct));
return 0;
}
输出结果:
最后得到的字节数为16字节。尽管char只占一个字节,但是在同一结构体中,double占了8字节,因此为了内存对齐,char在存储时也会占据8字节。所以结构体的最终的大小为16字节。
代码示例2

所占字节16
代码示例3

所占字节24
结构体内变量的排序也会对内存对齐的结果产生影响。从上往下,如果小的两个数据类型在前且不大于大的数据类型,则放在同一内存块中,如示例2。如果大的数据类型排中间,则每个数据都按最大的内存块对齐,如果示例3.
typedef与define区别
- 类型信息:typedef用于起别名(别名保留了原始类型的所有信息,包括类型的大小和其他属性),但不会创建新的类型;define可以用于创建常量、宏和简单的字符串替换。
- 类型安全:typedef提供了类型安全,编译器可以对其进行类型检查;define 是简单的文本替换,可能导致不容易察觉的错误。
- 使用方法:typedef使用方式更加广泛,可以与结构体、数组、指针、权举等等结合使用。
sizeof与strlen区别
- 属性:sizeof是C语言的运算符,结果在编译阶段就可以确定;strlen是C语言的库函数,需要在运行时才能计算出结果。
- 作用:sizeof 用于获取数据类型或变量占用的内存大小(以字节为单位);strlen用于计算字符串的长度(不包括结尾的空字符10')。
- 参数:sizeof的参数可以是数据的类型,也可以是变量;而strlen只能以结尾为’\0'的字符串作参数。
回调函数
回调函数概念
- 回调函数就是在某个事件或条件触发时由别的函数调用的函数。
回调函数特点
- 作为参数传递。回调函数本质是一个函数指针或函数引用,可以传递给其他函数。
- 延迟执行。回调函数通常不会立即执行,而是在某个事件,条件或者另一函数调用的特定时刻执行。
- 灵活性。通过回调函数,程序可以在不同的上下文中执行不同的操作,增加代码的灵活性和复用性。
回调函数的常见应用
- 异步编程。
- 事件驱动编程。
- 库函数或系统调用。
内联函数
1.内联函数是一种特殊的函数声明方式,通过在函数前面加上inline关键字,来指示编译器在调用这个函数时将他展开,而不是直接进行调用。
2.减小函数调用的开销。
3.可以提高执行效率。
4.允许编译器进行优化来提示性能。
memcpy和strcpy的区别
1.memcpy用于复制任意类型的内存数据,比如结构体,字符串,数组,它是按照字节数来进行复制。使用memcpy需要手动指定需要复制的字节数。
2.strcpy专门用于复制以\0结尾的C语言字符串,遇到\0的结束复制。
代码示例
#include <stdio.h>
#include <string.h>
int main() {
char src[] = "Hello, World!"; // 定义源字符串
char dest[20]; // 定义目标字符串数组,足够大以存储复制的内容
// 使用 strcpy 复制字符串
strcpy(dest, src); // 复制 src 到 dest,包括终止字符 '\0'
printf("After strcpy: %s\n", dest); // 输出复制后的字符串
// 清空 dest 以便再次使用
memset(dest, 0, sizeof(dest));
// 使用 memcpy 复制字符串,不包括终止字符
memcpy(dest, src, strlen(src)); // 复制 src 到 dest,不包括 '\0'
dest[strlen(src)] = '\0'; // 手动添加终止字符
printf("After memcpy: %s\n", dest); // 输出复制后的字符串
return 0;
}
sizeof 和 strlen的区别
sizeof是C语言中的运算符,关键字。用于计算数据类型/变量所占的字节数。在程序的编译期执行。
strlen是一个函数。用于计算字符串的长度。在程序的运行时执行。
细节:如果同时将sizeof 和strlen用于计算字符串大小,sizeof算出的结果会比strlen算出的结果多1。原因:sizeof会将字符串中的终止字符'/0'也计算进去,而strlen只计算到‘/0’之前(不包含‘/0’).
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "Hello,World!"; // 定义一个字符串
// 使用 sizeof 获取整个字符数组的大小
int size = sizeof(str); // 获取 str 占用的总字节数
printf("Size of str: %d bytes\n", size); // 输出 str 的大小
// 使用 strlen 获取字符串的实际长度
int length = strlen(str); // 获取 str 的实际字符数,不包括终止字符 '\0'
printf("Length of str: %d characters\n", length); // 输出 str 的长度
return 0;
}
输出结果
Size of str: 13 bytes
Length of str: 12 characters
C语言内存分配的方式
1.静态存储区分配:例如全局变量,静态变量。
2.栈上分配。局部变量。例如函数中定义的局部变量。
3.堆上分配。malloc,new
程序分为几个段
总共是堆栈+三个段。
1.代码段(.text段):用于存储程序的可执行指令,一般是只读的,防止被修改。
2.数据段(.data段):存储已经初始化的全局变量和静态变量。
3.BSS段(.bss段):存储没有初始化的全局变量和静态变量。
4.堆(heap):malloc和free进行管理。
5.栈(stack):存储局部变量,栈的申请和释放由操作系统自行决定。
数组指针和指针数组的区别
简单理解
数组指针是指针。指的是指向数组的指针。
指针数组是数组。里面的每一个元素都是指针。
数组指针
- 定义:数组指针是一个指向数组的指针,它指向整个数组的首地址。
- 特点:它是一个指针,存储的是数组首元素的地址。
- 声明方式:使用
类型 (*)[N]来声明,其中类型是数组元素的类型,N是数组的大小。
指针数组
- 定义:指针数组是一个数组,其中的每个元素都是指针。
- 特点:它是一个数组,每个元素都存储一个指针。
- 声明方式:使用
类型 *数组名[N]来声明,其中类型是指针指向的类型,N是数组的大小。
区别
- 内存表示:数组指针是一个单一的指针,它指向一个数组;指针数组是一个数组,包含多个指针。
- 使用场景:数组指针通常用于函数参数,以传递整个数组;指针数组用于存储多个指针,每个指针可以指向不同的数据。
- 内存分配:数组指针通常在函数内部使用,指向已经存在的数组;指针数组需要单独分配内存。
#include <stdio.h>
int main() {
// 定义一个数组
int arr[5] = {10, 20, 30, 40, 50};
// 定义一个数组指针,指向整个数组
int (*arrayPtr)[5] = &arr; // 指向包含5个整数的数组
// 定义一个指针数组,包含5个指向整数的指针
int *ptrArray[5];
// 初始化指针数组,每个元素指向数组的一个元素
ptrArray[0] = &arr[0];
ptrArray[1] = &arr[1];
ptrArray[2] = &arr[2];
ptrArray[3] = &arr[3];
ptrArray[4] = &arr[4];
// 使用数组指针访问数组元素
printf("Using array pointer: %d\n", (*arrayPtr)[2]); // 输出30
// 使用指针数组访问数组元素
printf("Using pointer array: %d\n", ptrArray[2]); // 输出30的地址,需要解引用
return 0;
}
数组名和指针的区别
1.数组名就是数组首元素的地址,也可以看作一个指针常量,这个指针是不能修改指向的。
2.指针访问数组的时候需要解引用,是间接访问。使用数组名访问数组是直接访问。
3.使用sizeof对指针和数组的大小计算是不同的。指针的大小和编译器的位数有关,使用sizeof计算数组名是整个数组的大小。
常量指针和指针常量
常量指针是指针,意为一个指向常量的指针。这个指针无法修改所指向的数据,但是可以改变指向。
通俗理解:常量指针是指针,指向(无法修改的)常量,但是可以改变指向。
指针常量是常量,意为指针是一个常量,指针指向是固定的,但是可以修改地址中的值。
指针常量的地址是固定,是一个常量,无法修改。但可改变地址中的值。
通俗理解:指针常量是一个指针类型的常量,无法改变指向,但是修改地址中的值。
const int* p;//const 修饰的是int,这是一个指向常量的指针,指针指向的值不能改变,但是指向可以改变
int* const p;//const 修饰的是*p,这是一个指针常量,指针的指向不能改变,指向的值可以改变
如何避免数组/指针越界?
合理应用取余操作,进行边界判断。
i++ % Size
堆和栈的区别
1.创建方式不同。栈是系统自动创建(主要用于保持局部变量),当函数执行完成时,栈被自动销毁。堆是程序员手动进行创建和释放的,由malloc进行创建,free进行释放。
2.空间大小不同。栈的空间是比较小的,而堆的空间比较大。
3.访问速度,栈的访问速度比堆快。
4.栈使用完后会自动销毁,而堆需要程序员手动进行销毁或释放。
队列和栈的区别
1.访问方式不同。栈是先进后出,队列是先进先出。
2.栈只能在栈顶进行操作,队列:在队尾进行插入,在队首删除。
3.应用场景
栈:函数调用,表达式求值。
队列:任务调度,广度优先搜索。
结构体和联合体的区别
struct结构体:不同的成员放在不同的地址中。结构体大小 = 所有成员大小之和(字节对齐)。
union联合体:所有成员共享一块地址。共用体大小 = 成员中占内存最大的成员的大小。
状态机编程
通过定义一系列的状态和触发状态切换的事件来管理复杂行为。最常见的应用场景比如:用户界面的切换(输入完数据后又进入下一个界面)
以下是为自动售货机为案例,使用状态机编程。
#include <stdio.h>
// 定义状态枚举
typedef enum {
WAIT_FOR_MONEY, // 等待投币
SELECT_PRODUCT, // 选择商品
WAIT_FOR_CHANGE // 等待找零
} State;
// 商品价格
const int PRICE_WATER = 1; // 水的价格
const int PRICE_SNACK = 2; // 零食的价格
// 函数声明
void insertMoney(State *state);
void selectProduct(State *state);
void dispenseProduct(State *state);
int main() {
State state = WAIT_FOR_MONEY; // 初始化状态为等待投币
int moneyInserted = 0; // 已插入的金额
int productSelected = 0; // 选择的商品
int change = 0; // 找零
printf("欢迎使用自动售货机\n");
while (1) {
switch (state) {
case WAIT_FOR_MONEY:
insertMoney(&state);
break;
case SELECT_PRODUCT:
selectProduct(&state);
break;
case WAIT_FOR_CHANGE:
dispenseProduct(&state);
break;
default:
printf("未知状态。\n");
return 0; // 退出程序
}
}
return 0;
}
// 用户投币
void insertMoney(State *state) {
int money;
printf("请投币(输入金额):");
scanf("%d", &money);
moneyInserted += money;
if (moneyInserted >= 3) { // 假设最低消费3元
*state = SELECT_PRODUCT; // 进入选择商品状态
printf("请按1选择水,按2选择零食:");
} else {
printf("请继续投币。\n");
}
}
// 用户选择商品
void selectProduct(State *state) {
int choice;
scanf("%d", &choice);
if (choice == 1 && moneyInserted >= PRICE_WATER) {
productSelected = 1; // 用户选择了水
} else if (choice == 2 && moneyInserted >= PRICE_SNACK) {
productSelected = 2; // 用户选择了零食
} else {
printf("余额不足,请继续投币。\n");
*state = WAIT_FOR_MONEY;
return;
}
*state = WAIT_FOR_CHANGE; // 进入等待找零状态
}
// 找零并分发商品
void dispenseProduct(State *state) {
if (productSelected == 1) {
printf("分发水。\n");
change = moneyInserted - PRICE_WATER;
} else if (productSelected == 2) {
printf("分发零食。\n");
change = moneyInserted - PRICE_SNACK;
}
printf("找零:%d元\n", change);
*state = WAIT_FOR_MONEY; // 重置为等待投币状态
}
C++相关
FreeRTOS相关
如何移植FreeRTOS?
首先下载源码,裁剪源码,把不需要的文件删去。添加FreeRTOS源码到工程中,然后配置FreeRTOSConfig.h,添加几个必备的宏定义。同时把裸机自带的SVC、PendSV、SysTick屏蔽掉。
重新配置SysTick中断作为FreeRTOS的时钟源。
FreeRTOS中的调度算法
抢占式调度:高优先级的任务可以打断低优先级任务的执行(适用于优先级不同的任务)
时间片轮转:相同优先级的任务具有相同大小的时间片(1ms),当时间片被耗尽时,任务会强制退出。时间片大小由配置文件中的一个宏定义决定。
协作式调度:使用vTaskDelay()释放cpu的资源让其他任务来运行,信号量,互斥量等来实现。
FreeRTOS中任务的状态
1.就绪态:当任务被创建时就会进入到就绪态。
2.运行态:当任务的代码正在被执行时就是运行态。
3.阻塞态:当任务在等待信号量或者是互斥量等待的时候就会进入阻塞态。
4.挂起态。使用vTaskSuspend()进入到挂起态。
FreeRTOS中的任务同步方式
队列:还可进行数据的传递。
信号量:在FreeRTOS中会分成两种:二进制信号量(实现共享资源的访问),计数型信号量(实现生产者和消费者模型)
互斥量:实现共享资源的访问。
事件组:可以等待多个任务的通知。
任务通知:一种轻量级的任务同步方式,TCB。任务通知不需要创建就可以使用。(用于一对一通信)
FreeRTOS有哪些内存管理算法?各个内存管理算法的特性是什么?大概实现原理是什么样的?
heap1:只分配,不释放。实现逻辑:用一个静态数组作为堆空间实现内存分配。
特点是实现简单,执行速度快,无内存碎片(因不释放),但灵活性极低。
适用场景:内存需求固定的场景(如任务创建后永不删除、队列 / 信号量等资源初始化后不释放),适合资源极度受限的嵌入式设备。
heap_2:支持分配和释放。从空闲块中找到最小的满足需求的内存块。
特点:是支持动态申请和释放。但是不会合并相邻的空闲内存块,易产生内存碎片。
heap_3:同样支持动态申请和释放。通过封装标准 C 库实现的。
特点:实现简单,但是执行时间不确定。依旧存在碎片化问题。
heap_4:支持动态申请和释放。实现逻辑:分配找到第一个足够大的内存块。同时释放时会合并相邻空闲内存块,减少碎片化。
特点:平衡了灵活性和抗碎片能力,是 FreeRTOS 中最常用的算法之一。
适用场景:需要频繁动态分配 / 释放内存(如动态创建 / 删除任务、队列),且对碎片敏感的场景。
heap_5:heap_4的拓展,支持在多个不连续的内存区域上管理内存,初始化时需要指定所有内存区域的地址和大小。
特点:兼容 heap_4 的碎片合并能力,且能利用分散的内存资源。
适用场景:内存物理上不连续的系统(如部分 MCU 有内部 RAM、外部 SRAM 等多个内存区域)。
总结:选择原则
- 若内存需求固定(只分配不释放):选 heap_1(最快、最省资源)。
- 若需动态管理但内存块大小固定:选 heap_2。
- 若依赖系统标准库且实时性要求低:选 heap_3。
- 若需动态管理且怕碎片:选 heap_4(最常用)。
- 若内存物理不连续:选 heap_5。
队列和信号量的区别
队列可以存储数据。
信号量一般不用于存储数据,而用于任务之间的同步和互斥。信号量是只有一个存储空间的特殊队列。
FreeRTOS中的空闲任务
概念:空闲任务默认优先级最低,只在没有其他可运行任务时才会执行。
功能:在系统没有其他优先级任务运行时占用CPU资源,使得系统始终有任务运行。
特点:优先级低;系统自动创建;负责回收被系统删除的任务的资源;可触发低功耗模式;可以处理一些不紧急的后台任务,如系统维护,监控任务状态等。
FreeRTOS中的队列、信号量、互斥量、事件组的底层实现
队列:环形缓冲区(数组+头尾指针)+两个读写阻塞链表。
信号量:队列+两个读写阻塞链表
互斥量:队列(长度为1)+两个读写阻塞链表
事件组:32位位掩码变量+事件等待链表
FreeRTOS中的调度是在哪个中断进行的?
FreeRTOS的调度是通过Tick中断实现的。Tick中断发生时,FreeRTOS会检查任务的优先级和状态,再决定是否进行任务切换。真正的任务切换操作是在PendSV中断执行,Tick中断相当于是发起调度指令。
FreeRTOS中开辟大内存给所有任务调用时需要注意什么?
要使用互斥量来保护其共享内存,确保同一时间只有一个任务可以访问该内存。
FreeRTOS和Linux的区别是什么?(实时性,中断处理,应用场景)
RTOS是硬实时操作系统,可以确保实时性。Linux是软实时操作系统,无法保证严格的实时性。
RTOS的中断处理简单高效,在中断执行少量的代码,避免复杂的上下文切换。
Linux的中断处理分为上半部和下半部,支持复杂的中断处理逻辑,但是开销大。
Free RTOS适用于资源受限的设备,如MCU,强调实时性和低功耗。
Linux适用于资源丰富的设备。
RTOS和前后台程序的区别?
前后台程序:各个模块在死循环中按顺序循环执行,除了中断,各模块之间不会相互打断,上个模块执行完了才会到下一个模块。
RTOS:各个模块任务独立循环工作,时间片消耗完了,就会根据任务的优先级进行切换。
FreeRTOS和RT-Thread的区别
FreeRTOS的任务是如何进行调度的?
抢占式调度:高优先级的任务可以打断低优先级任务的执行(适用于优先级不同的任务)
时间片轮转:相同优先级的任务具有相同大小的时间片(1ms),当时间片被耗尽时,任务会强制退出。时间片大小由配置文件中的一个宏定义决定。
协作式调度:使用vTaskDelay()释放cpu的资源让其他任务来运行,也可信号量,互斥量等来实现。
FreeRTOS中什么时候发生任务调度?
一般在Tick中断中发生调度,而真正的任务的切换在PendSV中断中执行,同时会保存当前上下文信息,恢复下一个任务的上下文。
在FreeRTOS中若是配置为非礼让+非抢占,则当前任务会一直得到执行,为什么?
Freertos的任务调度机制?(与之前的类似)
抢占式调度:高优先级的任务可以打断低优先级任务的执行(适用于优先级不同的任务)
时间片轮转:相同优先级的任务具有相同大小的时间片(1ms),当时间片被耗尽时,任务会强制退出。时间片大小由配置文件中的一个宏定义决定。
协作式调度:使用vTaskDelay()释放cpu的资源让其他任务来运行,也可信号量,互斥量等来实现。
如何划分的任务的优先级。
- 紧急程度:对响应时间要求严格的任务(如传感器数据采集、紧急故障处理)分配高优先级;非紧急任务(如日志记录、状态上报)分配低优先级。例如,电机过流保护任务优先级需高于人机交互任务。
- 执行频率:高频任务(如 1ms 周期的 PID 控制)通常需要较高优先级,避免被低频任务阻塞;但需注意 “高频高优先级任务不应长期占用 CPU”,否则会饿死低优先级任务。
- 资源依赖:若任务 A 依赖任务 B 的输出(如任务 B 预处理数据后,任务 A 才能计算),则任务 A 优先级可低于或等于任务 B,避免 A 因等待 B 而无效占用 CPU。
- 优先级反转防护:需预留 “优先级继承” 的缓冲空间(如通过信号量的优先级继承机制),防止低优先级任务持有资源时,高优先级任务被阻塞导致的实时性下降。
任务的时间片大小是如何考虑的。
时间片(Time Slice)是同优先级任务轮转调度时的 “单次运行最大时长”,其大小需平衡 “响应速度” 与 “切换开销”,具体考虑:
- 任务响应需求:时间片应略大于同优先级任务的 “最小处理单元”。例如,多个串口数据解析任务(同优先级),若单帧数据解析需 5ms,则时间片可设为 10ms(避免频繁切换);若任务需快速响应(如按键扫描),时间片可缩小至 1-2ms。
- 系统时钟节拍(Tick):时间片通常是系统 Tick 的整数倍(如 FreeRTOS 中,Tick 默认 1ms),便于与系统定时器同步。例如,Tick=1ms 时,时间片可设为 1、2、5 个 Tick(即 1ms、2ms、5ms)。
- 切换开销:时间片过小会导致任务切换频繁(保存 / 恢复上下文耗时),增加 CPU 负担;过大则会导致同优先级低延迟任务 “等待过久”。例如,在 100MHz CPU 上,单次任务切换耗时约 1-2μs,若时间片设为 1ms,切换开销占比约 0.2%,可接受;若设为 100μs,切换开销占比会升至 2%,需谨慎。
讲讲pendsv,哪些情况会触发pendsv。
endSV(Pending Supervisor Call)是ARM Cortex-M 内核中专门用于 “低优先级任务切换” 的系统中断,其核心特性是 “可悬起”(即可以被高优先级中断打断,待高优先级中断处理完再执行),确保任务切换不干扰紧急中断。
触发 PendSV 的典型场景:
- 任务主动放弃 CPU(如调用
vTaskDelay()延迟、xSemaphoreTake()等待信号量阻塞); - 高优先级任务就绪(如低优先级任务运行时,高优先级任务被唤醒,系统需要切换到高优先级任务);
- 任务优先级动态变化(如通过
vTaskPrioritySet()提升某任务优先级,导致需要立即切换); - 系统主动请求切换(如 FreeRTOS 的
taskYIELD()函数,主动触发任务调度)。
对于任务切换选用的是pendsv,为什么不用定时器中断呢?
定时器中断(如 SysTick)的核心功能是提供系统时钟基准(如 1ms 一次,用于任务延迟、超时判断),而任务切换选择 PendSV 而非定时器中断,本质是避免高优先级中断被任务切换干扰,具体原因:
- 优先级差异:定时器中断(SysTick)优先级通常较高(需保证时间基准准确),若用它做任务切换,可能在高优先级中断(如电机故障中断)处理过程中强制插入任务切换,导致中断处理延迟甚至数据丢失。而 PendSV 优先级被设计为系统最低,只会在所有高优先级中断处理完成后才执行,确保中断不被打扰。
- 灵活性:任务切换的触发是 “动态按需” 的(如任务阻塞、高优先级任务就绪时立即切换),而定时器中断是 “固定周期” 的,无法实时响应动态切换需求。例如,某高优先级任务在 2ms 时就绪,若依赖 10ms 一次的定时器中断切换,会导致该任务被延迟 8ms 执行,违背实时性要求。
- 减少冗余切换:定时器中断若触发切换,可能在 “无任务需要切换” 时(如当前任务仍需运行)也执行切换流程,增加不必要的 CPU 开销;而 PendSV 仅在 “确实需要切换” 时被触发(由系统主动标记),更高效。
RT-Thread相关
线程是怎么调度的
从调度机制的角度回答:通过优先级调度,时间片轮转的算法机制进行调度。高优先级线程可以抢占低优先级线程,高优先级线程优先执行,如果高优先级任务不休眠,则低优先级任务将无法执行。相同优先级的线程间采用时间片轮转的机制,时间片消耗完后进行线程切换,执行下一个线程。
介绍下信号量和互斥量,说一些其区别和使用场景
信号量和互斥量都是用于解决线程间的同步和互斥。信号量有计数型信号量或者二值信号量,信号量值可以大于1。而互斥量的计数值只有0和1,此外互斥量因为有优先级继承机制,因此可以解决优先级反转的问题。信号量主要用于多线程间的同步,互斥量主要用于对互斥资源的保护,以及解决优先级反转的问题。
上下文切换的过程
首先是Tick中断执行,发现有线程需要调度,Tick中断发出需要调度的指令,PendSV中断去执行线程间的切换,也包含上下文切换。首先会保存当前上下文信息,如寄存器值,SP指针,局部变量,返回地址等。同时恢复下一个线程的上下文信息,同样也是恢复它的寄存器值,SP指针,局部变量和返回地址等。
线程是怎么切换的,保存在哪里的,在哪里运行
线程间切换主要是通过保存当前上下文信息,恢复下一个线程上下文信息进行切换。这些上下文信息包括(寄存器,局部变量,返回地址,SP指针等)。
这些信息都是保存在我们最开始分配的线程栈中。因为是栈,运行的话就是在RAM中。
SP指针解释一下,这个是在什么场景下会使用
SP指针是堆栈指针,指向当前线程栈的顶部。这个栈里存储着上下文信息,如寄存器值,局部变量,返回地址等。
使用场景:发生线程切换时,RT-Thread需要保存和恢复线程的SP指针,以便切换下一个线程时能够恢复下个线程的上下文状态。
RTOS主要是互斥量和信号量之间的应用场景和区别,底层实现需要看看源码,主要是看线程调度、互斥量信号量、内存分配的实现即可,大多数RTOS的实现都是差不多的,如果平台是32的话还需要搞懂PendSV和SVC做了什么事情。。
Linux相关
进程和线程的区别
1.进程是资源分配的基本单位,线程是进程中的执行单元以及CPU调度和执行的基本单位。进程>线程。
2.资源占用:每一个进程都有自己独立的地址空间。线程是共享进程的地址空间。
3.容错性:当一个进程出现问题不会影响到其他的进程的执行。一个线程崩溃可能会影响到其他线程。
4.调度和切换:进程是一个独立的单位,需要恢复的上下文内容比较多,消耗的资源也就比较多,线程消耗的资源比较少。
进程的状态
1.创建状态:当调用fork进入创建状态。
2.就绪状态:进程已经准备好,但是还没有运行。
3.运行状态:进程已经获得系统的资源可以运行。
4.阻塞状态:等待信号量或者互斥量等事件的时候会进入这个状态。
4.终止状态:进程结束。


















 5814
5814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









