









 本文详细介绍如何在CentOS6.5环境下安装配置Scala2.10.4和Spark1.6.0,并确保其与已有的JDK1.8和Hadoop2.6.0环境兼容。此外,还提供了测试Spark是否正确安装的方法。
本文详细介绍如何在CentOS6.5环境下安装配置Scala2.10.4和Spark1.6.0,并确保其与已有的JDK1.8和Hadoop2.6.0环境兼容。此外,还提供了测试Spark是否正确安装的方法。
当时上云计算课的时候,搭建的Hadoop+开发IDE及插件+spark的笔记,这里是第二部分Spark+Scala环境搭建。
一、 系统环境
CentOS 6.5
Jdk 1.8
Hadoop 2.6.0
二、下载安装Scala
我们默认jdk云云都已经安装配置好了(JDK+Hadoop的安装配置见另一篇文章),只是单纯的安装配置Scala。Scala的安装和配置较为简单。
首先,我们选择从官网(http://www.scala-lang.org/download/all.html)下载Scala,这里我们选择的版本是Scala 2.10.4,同jdk、hadoop的安装一样,将包解压,解压后的文件夹重命名为scala-2.10.4,放到/usr/BigData目录下。
然后,我们修改/etc/profile文件,在终端上执行命令
gedit /etc/profile在文件后面添加语句:
#Scala环境变量
export SCALA_HOME=/usr/BigData/scala-2.10.4
export PATH=\$SCALA_HOME/bin: $PATH然后执行命令 source /etc/profile ,使配置立即生效。至此,Scala的配置就完成了。我们在终端执行命令
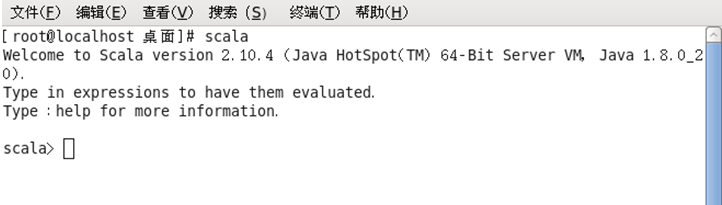
scala出现下图所示内容,证明scala安装配置成功。
三、下载安装Spark
从Spark官网(http://spark.apache.org/downloads.html)下载
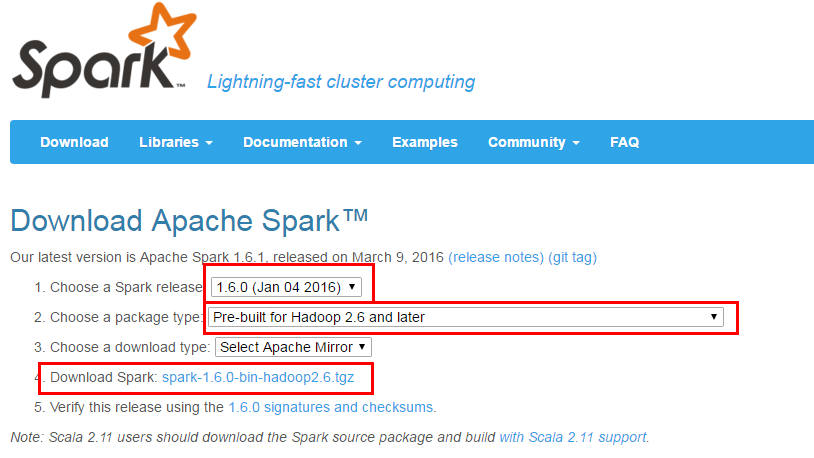
这里我们选择Spark1.6.0,因为我们已经搭建好了Hadoop 2.6.0的环境,所以包类型选择图示的。
下载完成后,解压,将解压得到的文件夹重命名为spark-1.6.0,并复制到/usr/BigData目录下。
四、配置Spark
1.进入/usr/BigData/spark-1.6.0/conf目录下,复制一个spark-env.sh.template的副本,命名为spark-env.sh,编辑该文件,再文件最后加上下面的语句:
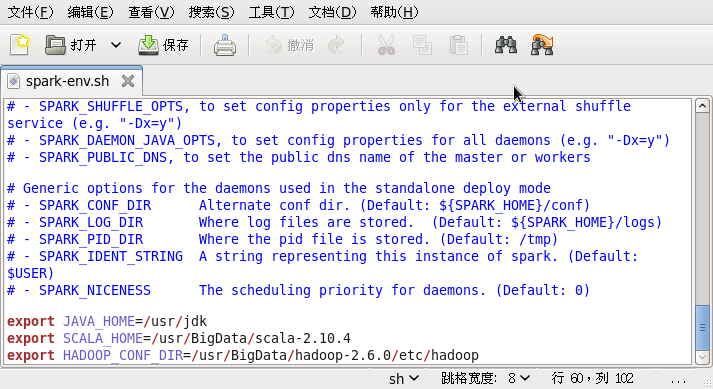
export JAVA_HOME=/usr/jdk
export SCALA_HOME=/usr/BigData/scala-2.10.4 #记得将Scala的环境变量添进去
export HADOOP_CONF_DIR=/usr/BigData/hadoop-2.6.0/etc/hadoop2.修改/etc/profile文件,加上下面的语句
#Spark环境变量
export SPARK_HOME=/usr/BigData/spark-1.6.0
export PATH=$SPARK_HOME/bin:$PATH五、测试
注意,必须安装 Hadoop 才能使用 Spark,但如果使用 Spark 过程中没用到 HDFS,不启动 Hadoop 也是可以的。在 ./examples/src/main 目录下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等语言的版本。我们可以运行一个示例程序来验证spark是否安装成功。进入到/usr/BigData/spark-1.6.0目录下。执行命令:
./bin/run-example SparkPi 2>&1 | grep “Pi is roughly”如果输出π值,证明spark已经可以运行了。
我们也可以启动spark-shell,在spark-1.6.0目录下,执行命令如下
./bin/spark-shell出现scala>提示符,证明成功。
关此部分,可以参照厦门大学数据库实验室网站,有一篇博客(http://dblab.xmu.edu.cn/blog/spark-quick-start-guide/)讲的是spark的安装与基础使用。
具体的程序运行测试会在插件篇中提到。
在JDK+Hadoop+Spark+Scala全部配置完成后,/etc/profile文件如下:
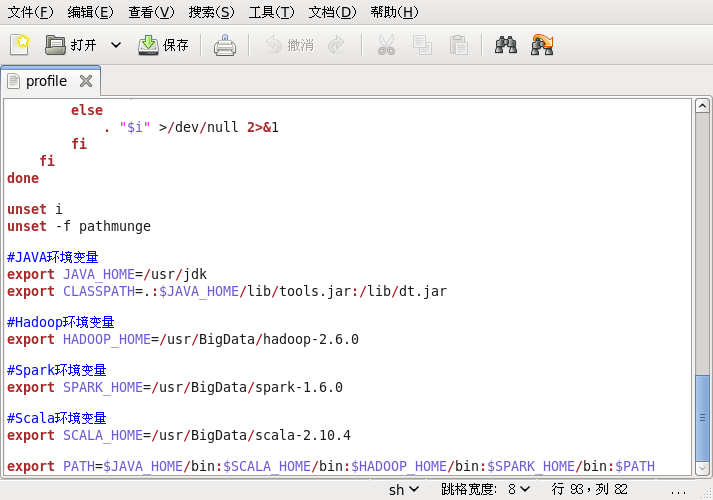
附
#JAVA环境变量
export JAVA_HOME=/usr/jdk
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:/lib/dt.jar
#Hadoop环境变量
export HADOOP_HOME=/usr/BigData/hadoop-2.6.0
#Spark环境变量
export SPARK_HOME=/usr/BigData/spark-1.6.0Hadoo伪分布搭建http://blog.csdn.net/sunglee_1992/article/details/53024652
Scala与MapReduce开发的IDE插件http://blog.csdn.net/sunglee_1992/article/details/53026421















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









