






写在前面:上一期我写了一篇关于如何加载MOE模型(以Mixtral 8x7B为例)以及其在加载过程中遇到的一些错误解决方法(等我一下,我修改一下wuwu)。并在最后说到我将写一个有关MOE的基础知识的blog,以对上一篇做一个补充。同样的,但从基础知识层面肯定是不够的,下一期我们将来debug(bert那一期说了这么debug哦!)一下!那现在你准备好了嘛?让我们一起来看看到底啥是MOE!
一. 大模型时代的挑战与 MoE 的崛起
大模型的核心就在于“大”——参数量大,数据规模大等等,例如随着模型的发展,参数量从千万级一路飙升至千亿乃至万亿级别。这给传统的、参数全部参与每次计算的“密集模型”(Dense Model)的训练和推理带来了严重的挑战。
- 高昂的训练成本: 训练一个拥有数千亿甚至万亿参数的密集模型,需要海量的计算资源(GPU/TPU)、巨大的能耗以及超长的训练时间。
- 巨大的推理开销: 即使在模型训练完成后,每次进行预测(推理)时,仍然需要将模型的全部参数加载到计算设备中,并执行大量的计算。这导致推理延迟高、硬件要求严苛,难以在资源受限的环境下高效部署。
- 内存限制: 加载和运行巨大的模型需要巨大的内存和显存(RAM/VRAM),这超出了普通硬件的能力范围,因此面临内存溢出(OOM)的问题。
然而,混合专家模型(Mixture of Experts, MoE) 作为一种“稀疏激活”的模型架构,应运而生。下面我们就来看看什么是MOE吧!
二. 什么是混合专家模型 (MoE)?
1. 形象描述(比喻)
在第一部分中,我们讨论了LLM面临的挑战。那么,混合专家模型(MoE)是如何试图解决这些问题的呢?
我们都知道,在Transformer 模型中每个 attention 层后跟着一个巨大的 Feed-Forward Network, FFN)的神经网络架构。它的核心思想是:与其使用一个庞大无比的网络来处理所有类型的输入,不如使用多个相对较小的、各有所长的“专家”网络,并设计一个机制来决定将不同的输入分配给哪些专家进行处理。
想象一下,现在有一个非常复杂的问题需要解决,这个问题涵盖了数学、历史、编程等多个领域。如果只有一个人,他可能需要花费大量时间去查阅资料来回答所有领域的问题。但如果有一组专家团队,包括数学家、历史学家和程序员,并且你还有一个聪明的“调度员”,能够根据问题的类型(输入)将其精准地转交给最擅长解决这类问题的专家团队(或其中的一两个专家),那么整个解决过程就会高效得多。
在混合专家模型中,这个“专家团队”就是专家网络 (Expert Networks),它们通常由多个并行的前馈神经网络(FFN)组成,每个 FFN 可以被视为一个“专家”。而那个“聪明的调度员”,就是门控网络 (Gating Network),也被称为 路由器 (Router)。专家网络和路由器就是MOE的两个重要组成部分。如下图所示:
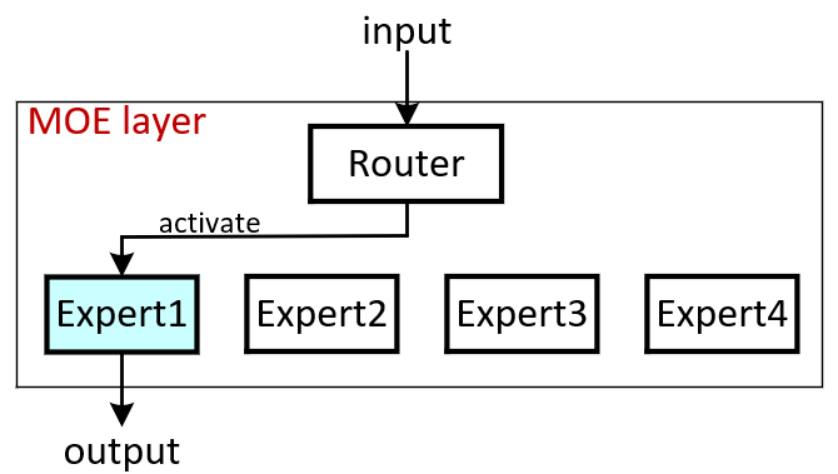
当一个输入(例如一个 Token 的表示向量)进入 MoE 层时,门控网络(router)会对其进行分析,并输出一组概率(有N个专家就有N个概率值),这时根据概率值的大小选择专家进行激活(一般采取Top-K的方式:即选择概率值最高的K的专家进行激活)。这些被选中的几个专家会被激活,参与计算,并将它们的输出进行某种方式的组合,形成 MoE 层的最终输出。
读到这里,你可能会想:“为什么代替FNN层,不代替注意力机制这些呢?” 主要原因:是FFN的特性决定的。FFN层主要负责对每个token独立地进行非线性变换。这意味着FFN的计算是局部的,并且各个token之间的计算是独立的。而自注意力机制需要考虑上下文语境(多个token之间要交互)。
我们继续往下看看MOE和传统的Dense的区别到底在哪里!
2. Dense model VS. Sparse model
关键点在于“混合”和“专家”:
- 专家 (Experts): 指的是多个独立的子网络,它们可以学习处理输入的不同方面或不同类型的数据。
- 混合 (Mixture): 指的是门控网络如何根据输入动态地选择和组合这些专家的输出。
更重要的是,MoE 是一种稀疏激活 (Sparsely Activated) 的模型。这意味着在任何一个特定的时刻,对于任何一个特定的输入,MoE 层中只有一小部分参数(即被门控网络选中的专家的参数)会被用于实际计算。这与密集模型形成鲜明对比,密集模型在处理任何输入时都需要激活和计算几乎所有参数。
但是,通过这种设计,MoE 模型可以在不显著增加每次计算成本(FLOPs)的情况下,极大地增加模型的总参数量(因为专家数量可以很多),从而提升模型的容量和学习更复杂、更细致模式的能力。所以,在很多论文中提到,MOE也会面临着内存瓶颈!!(下一期我会讲到)
我们先抛开这个缺点,来看一下门控网络和专家网络是怎么工作的!
三. MoE 的组件:门控网络与专家网络(图解+代码解析)
注意:我们的实例代码是huggingface的transformers库中的Mixtral 8x7B模型。代码路径为:./tansformers/src/transformers/model/mixtral/modeling_mixtral.py
1. MOE的计算过程(Top-2为例)
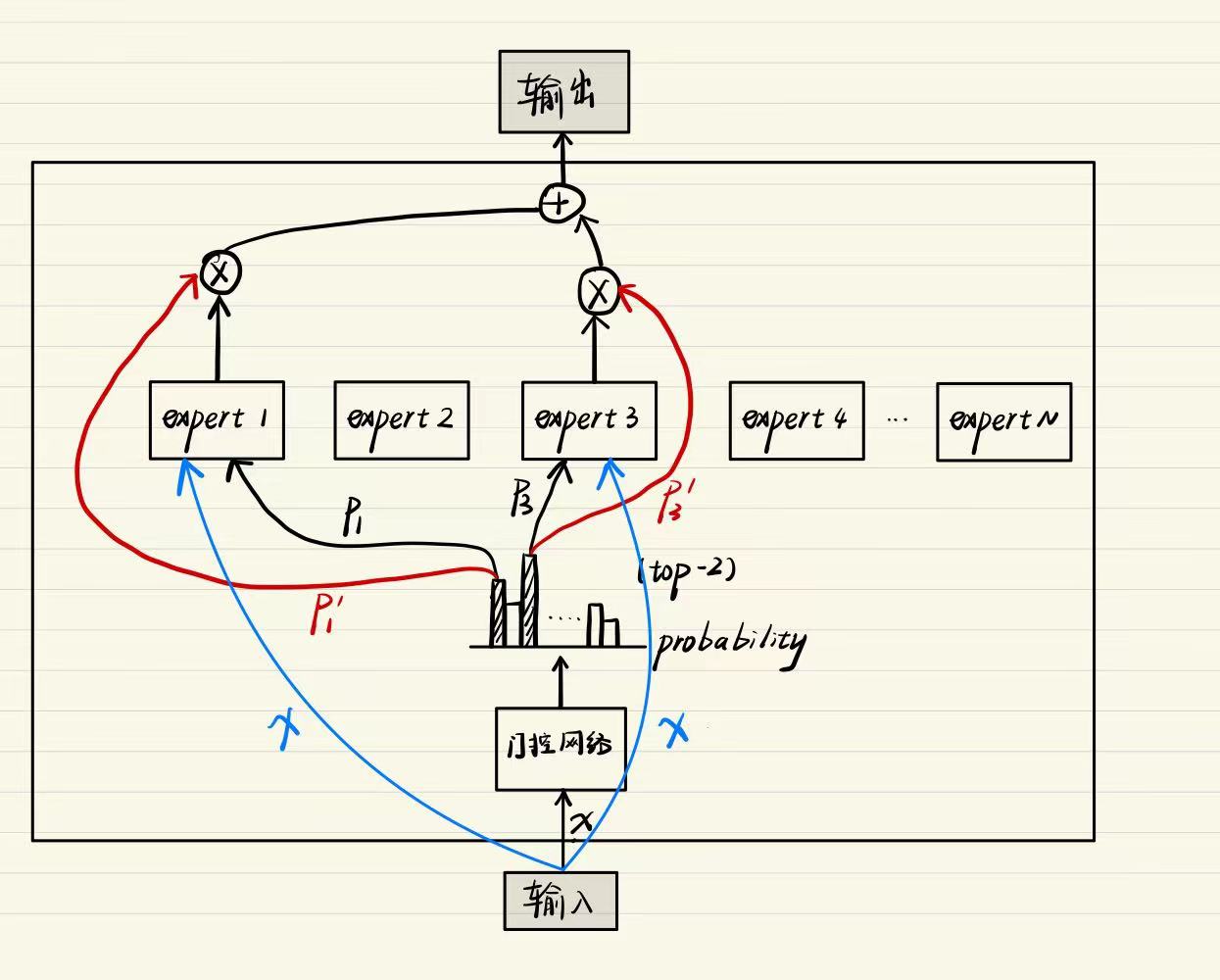
在以top-2专家的例子中,门控网络负责产生概率,并根据概率值选择数值最高的两个专家并激活,这两个专家就负责计算。同时,还需要重新使用归一化计算概率值,使得两个专家的概率(权重)之和为1,这是因为后续我们要对两个专家输出进行加权求和。
2. Mixtral 8x7B的关键类
对啦对啦,这个里面的类挺多的。想要快速查找,ctrl+F可以打开文本的搜索框o!
1. 代码嵌套结构的overall
下图就是modeling_mixtral.py中的函数嵌套结构,你可以选择MixtralForCausalLM等下游任务类开始看,重点关注他们调用的类。MixtralForCausalLM类会调用MixtralMode类,这就是Mixtral模型的主体。
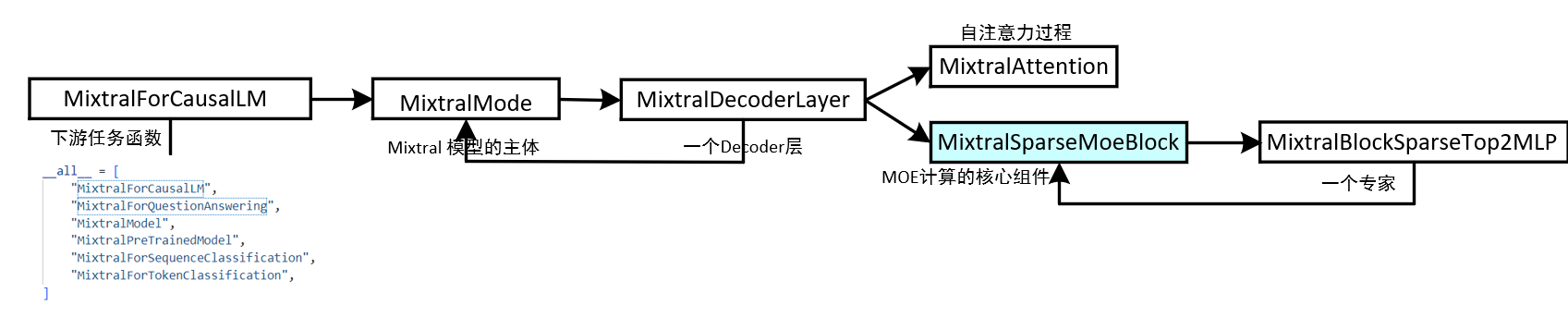
在MixtralMode类中,你可以看到下面这行代码,会有一个循环,遍历的次数是层数(这个层数表示的是decoder层),并且其中会调用一个MixtralDecoderLayer类,这个类就是实现一个具体的Decoder类。
self.layers = nn.ModuleList(
[MixtralDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)接着,在MixtralDecoderLayer类中,包含两个关键组件,一个是注意力机制(参考上一期的Bert模型中的实现),一个是MOE组件,这也是我们今天的重头戏。
2. MixtralSparseMoeBlock 类
我们直接来看代码。我会对每一行重要命令添加注释。大家比对着看就行,其实它的命名什么的也能看出函数的作用。
首先在initial里面,我们会看到一行循环代码。这一行代码中会调用一个MixtralBlockSparseTop2MLP类,这个类是处理每个专家。我们待会儿看看。
self.experts = nn.ModuleList([MixtralBlockSparseTop2MLP(config) for _ in range(self.num_experts)])接着我们来看 MixtralSparseMoeBlock 的forward(前向传播)。
- 门控网络(计算专家分数和对应的概率)
#将输入hidden_states 送入门控网络(self.gate函数)
#得到每个token分配给每个专家的原始分数
router_logits = self.gate(hidden_states) #shape[batch_size * sequence_length, num_local_experts]
#并对原始分数进行softmax,得到概率分布(路由权重)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)- 选择Top-k个专家
#torch.topk找到每个token概率最高的K个专家
#selected_experts表示被选中的专家索引
#routing_weights现在只包含了被选中的专家的对应权重
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)- 对新的专家概率进行归一化
原因:保证后续对每个token中的专家的加权求和的输出是正确的权重
#对选择的专家的概率(权重)进行归一化,确保每个token中被选中的专家的权重之和为1
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
final_hidden_states = torch.zeros((batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device)大家在debug时可以关注一下几个重要变量的shape。
#shape:
#routing_weights: (batch_size * sequence_length, k)
#selected_experts: (batch_size * sequence_length, k)
#hidden_states 原始形状: (batch_size, sequence_length, hidden_size)
#展平后的 hidden_states: (batch_size * sequence_length, hidden_size)- 对被选中的专家进行编码(一位独热码)
例:如果batch_size = 1, sequence_length = 4(表示有4个token),K = 2(专家数为2)
[[1,2], 表示token1选择的是专家1,2 ---> 一个8位的一位独热码表示:[[01000000],[00100000]]
[2,4], 表示token2选择的是专家2,4
[3,5], 表示token3选择的是专家3,5
[2,6], 表示token4选择的是专家2,6
[6,1]] 表示token5选择的是专家6,1
#.permute(2,1,0)表示维度重排 -----> (k*token_num专家的总数,K,batch_size * sequence_length)
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0- 遍历执行被选中的专家并得到输出
#找出哪些专家在当前批次中至少被一个 token 选中过
expert_hitted = (expert_mask.sum(dim=(-1, -2)) > 0).nonzero(as_tuple=True)[0].tolist()
#遍历执行专家计算(所以被选中过的专家)
for expert_idx in expert_hitted:
#获取当前正在处理的专家网络模块
expert_layer = self.experts[expert_idx]
idx, top_x = torch.where(expert_mask[expert_idx])
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
#对当前专家的输出进行加权
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None]
#对所有专家进行求和
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))到此MOE模块就执行结束了。这时候你可能会问:“主包主包,你说的MixtralBlockSparseTop2MLP类在哪里用到了,你说这不是每个专家的计算嘛?在遍历过程中也没看见呢?”
主包回答:在遍历执行过程中有一个被忽略的核心:self.experts[expert_idx],我们返回到 MixtralSparseMoeBlock 类的initial处,可以看见self.experts的初始化调用了MixtralBlockSparseTop2MLP类,这个我说过是处理每个专家的计算。现在明白怎么调用的了吧!!下面我们就来看看这个MixtralBlockSparseTop2MLP类吧!
3. MixtralBlockSparseTop2MLP类
这个类代码很少,主要就是扮演着FFN的角色。我们可以看见里面有三个关键的矩阵:w1,w2,w3。在论文中,他一般不会用这么没有含义的名称哈!
w1 --------> 上行矩阵(Up-projection)
w2 --------> 下行矩阵(Down-projection)
w3 --------> 门控矩阵(Gate)那我们来看看代码(forward)
#self.w1()作用是将输入 hidden_states 从 hidden_dim 维度投影到更高的 ffn_dim 维度
#然后经过一个激活函数 (self.act_fn)
#self.w3()接收原始的 hidden_states 作为输入,并将其投影到 ffn_dim 维度
#self.w3()输出会与 w1 经过激活函数后的输出 进行逐元素相乘(*)。逐元素相乘就是对应位置的元素相乘放在新张量的对应位置。(这个逐元素相乘的操作就是“门控”的核心,因为它允许 w3 的输出(作为门)来选择性地放大或抑制 w1 路径上的信息。)
current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.w3(hidden_states)
#最后self.w2()将输入 current_hidden_states 从 ffn_dim 维度投影到原始的 hidden_dim 维度
current_hidden_states = self.w2(current_hidden_states)
四. 未来展望
还没想好明天更新什么呢!晚上睡觉前想想hhh。哦对,上一期的模型加载还没修改完成哈哈哈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









