






写在前面:现目前关于transformer的教程,网上的大多数教程要么只有环境的安装(也不知道什么时候安装哈哈哈),要么是只给出代码(可能还存在一些问题,并且根本不知道怎么样才能跑起来,常常会发出一个疑问:这些代码写在哪里呀)。总言之,缺少一个从环境部署到项目跑通的一个全栈式流程。因此,在本教程中,我将为你提供这样的全栈式流程(哦对了,之所以不手搓,是因为我想直接debug别人的代码来理解,其实这也是对于初学者比较好的方式)。此外,我还将告诉你,你在搭建过程中可能遇到的一些问题的解决方法。如果你已经准备好了,那我们开始吧!!!
一. 环境搭建(基于pytorch的安装)
这是因为现在主流的项目都是基于pytorch的。那么在安装pytorch之前,需要先具备Anaconda环境。如果已经有Anaconda的同学可以直接跳到1.2节。
检查环境中是否已经安装Anaconda
$ conda -version
conda: command not found命令没有找到,说明Linux中没有安装Anaconda。如果安装了Anaconda,则会显示版本号。
1.1 Anaconda安装
1.查看版本
查看Linux版本对应的Anaconda的版本,Anaconda的官网(https://repo.anaconda.com/archive/),xxx为服务器的名称,因为我是在服务器上使用的,你的linux环境也可以,这个不是重点,重点是架构类型。
$ uname -a
Linux xxx 6.8.0-57-generic #59~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Wed Mar 19 17:07:41 UTC 2 x86_64 x86_64 x86_64 GNU/Linux #xxx为你服务器的名称x86_64 → 选 x86 版本
aarch64/arm64 → 选 ARM64 版本
s390x → 选 IBM Z 版本我的是x86_64的,所以选择x86版本。
![]()
2.使用wget下载
$ wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh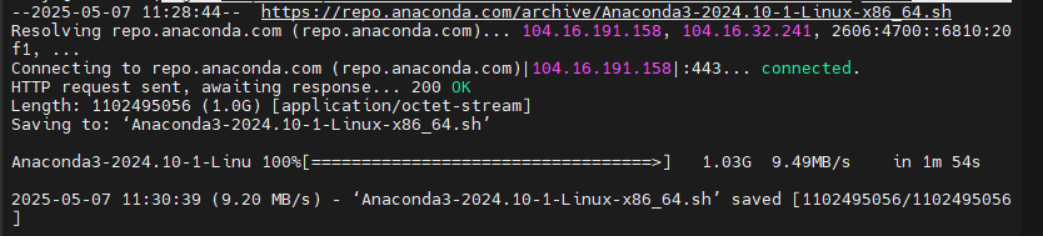
然后开始安装,安装命令如下:
$ bash Anaconda3-2024.10-1-Linux-x86_64.sh
$Anaconda3-2024.10-1-Linux-x86_64.sh是你下载的安装包的名称,你的可能不叫这个输入之后,需要一直按回车键知道出现询问 yes or no(其实就是我们在windows下询问是否接受xxx协议)时,在命令行输入yes即可(表示接受)。然后需要你确认安装路径,如果不需要修改直接按回车即可,如果需要修改输入你指定的路径即可。(无论是否修改,都需要记住这个路径!!!!)
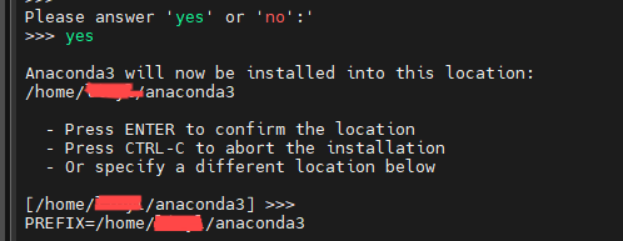
等待安装完成后,他会出现询问你是否初始化配置命令。直接输入yes即可。它会自动帮你初始化配置文件~/.bashrc
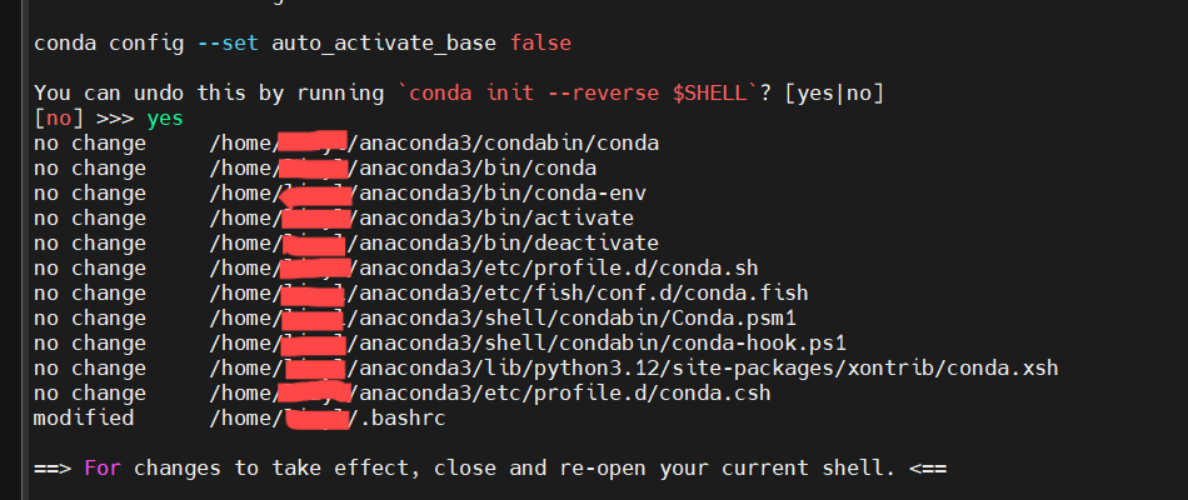
完成之后,你的~/.bashrc文件中将自动出现这一段信息。下面我们将会告诉你怎么打开~/.bashrc文件并完成环境变量的配置。
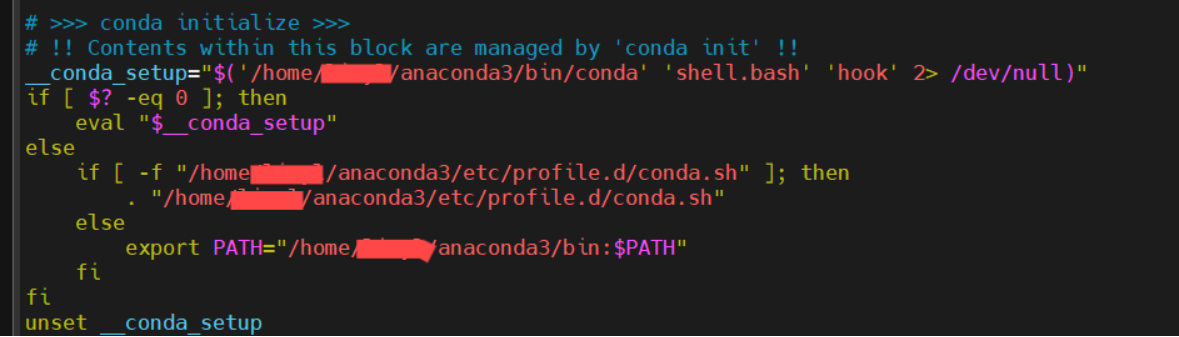
3.修改环境变量
进入到配置文件中,在文档末尾加入Anaconda的路径即可。
$ vim ~/.bashrc #打开配置文件现在你就进入了文件中,在文档末尾加入Anaconda的路径即可。
#添加路径(Linux的基本操作:A 切换到insert模式,输入export路径(下面这一段)即可,然后按esc,输入“:wq!”即可保存退出)
export PATH="/home/你的用户名/anaconda3/bin:$PATH" #/home/你的用户名/anaconda3/ 为anaconda的安装路径,一般都是这个最后激活配置
$ source ~/.bashrc #激活配置文件4.检查是否安装成功
$ conda --version
conda 24.9.2现在就出现了版本号,说明安装成功!!!!
致谢:Ubuntu纯命令行安装Anaconda_ubuntu命令行安装anaconda-CSDN博客
1.2 Pytorch安装
1.创建pytorch环境
$ conda create -n pytorch python=3.10 #创建一个名为pytorch的环境,python的版本是3.10需要确认两次,每次确认时只需要输入y即可。
2.激活环境
$ source activate pytorch命令行就会从base切换到pytorch(你的环境的名字哈)

3.使用conda命令安装与显卡驱动兼容的pytorch版本
1). 查看显卡驱动
$ nvidia-smi #Nvidia显卡的查看命令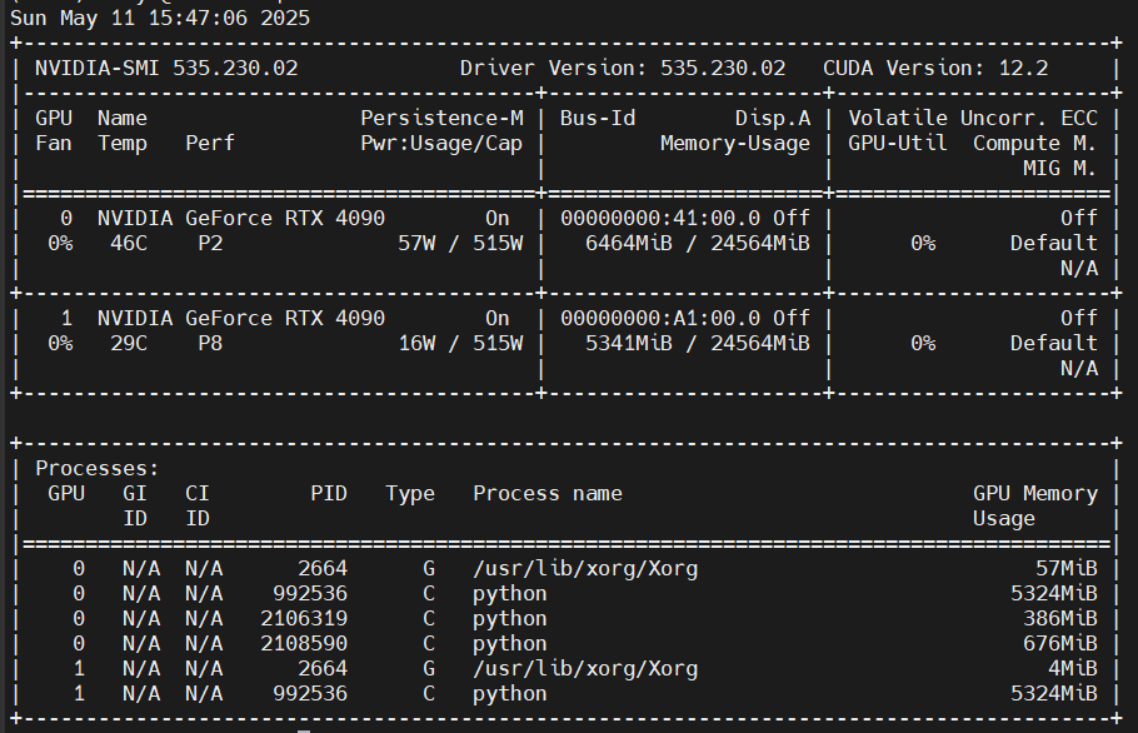
GPU 名称: NVIDIA GeForce RTX 4090
Driver Version(驱动版本): 535.230.02
CUDA Version(CUDA 版本): 12.2
CUDA Toolkit 11.8 需要的最低驱动版本是 520.61,所以在我们的环境中可以安装CUDA Toolkit 11.8(这是一个比较稳定的版本,同时与4090的sm_89是匹配的)。
题外话:我之前安装了一个cuda10.1,在测试cuda时出现了与4090不兼容的情况。
就需要去官网(Previous PyTorch Versions)找到匹配版本的安装命令。
2). 选择合适的pytorch版本
这个与你的项目有关啦!比如我后续需要用到的是hugging face上的项目,他要求2.1.xx以上版本的pytorch,所以我最开始下载的2.0.0总是出现有些库不全的问题(我这里选择了稳定的2.3.0的,基本与很多项目都兼容,一般来说不要太低也不要最新)。
查看显卡驱动复制到命令行回车运行即可。
$ conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=11.8 -c pytorch -c nvidia3). 激活环境
$ source activate pytorch4). 检查是否安装成功
$ python --version #检查python版本如果你在创建pytorch环境时指定了3.10的话,一般输出就是3.10.x。下面我们在python交互式命令行中运行一些代码来测试一下。
$ python这时候就进入了python命令行中,然后输入下面几行,回车后,输出为True即可正常调用GPU。
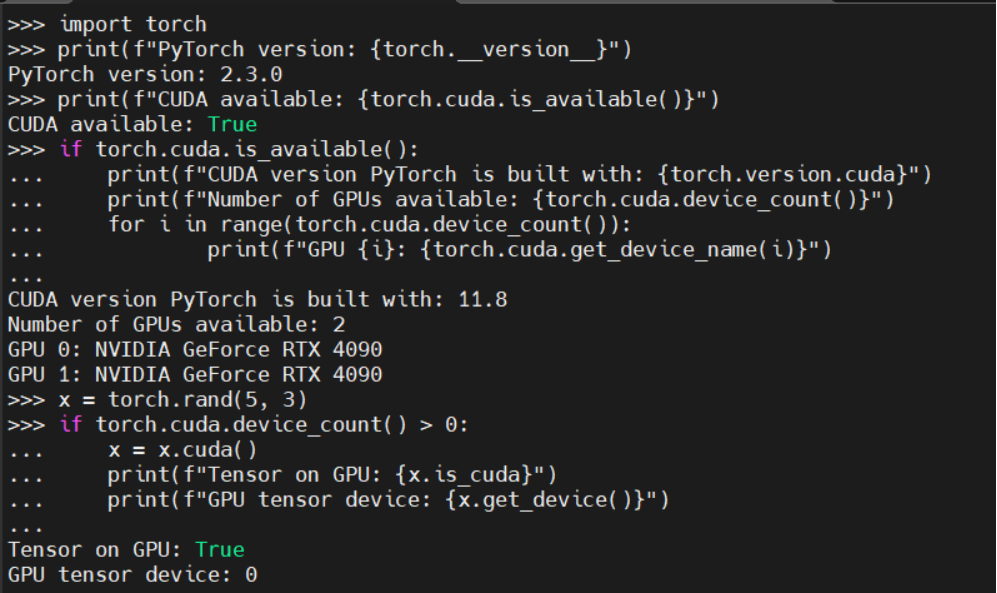
import torch #导入torch包print(f"PyTorch version: {torch.__version__}") #输出pytorch的版本print(f"CUDA available: {torch.cuda.is_available()}") #输出CUDA是否可用
#查看cuda和显卡信息
if torch.cuda.is_available():
... print(f"CUDA version PyTorch is built with: {torch.version.cuda}") #输出CUDA版本
... print(f"Number of GPUs available: {torch.cuda.device_count()}") #可用的显卡数目
... for i in range(torch.cuda.device_count()):
... print(f"GPU {i}: {torch.cuda.get_device_name(i)}") #依次输出显卡的名称
#简单测试GPU计算
x = torch.rand(5, 3)
if torch.cuda.device_count() > 0:
... x = x.cuda()
... print(f"Tensor on GPU: {x.is_cuda}")
... print(f"GPU tensor device: {x.get_device()}")注意:if下面那个语句在输入时,一定要先输入tab键(表示在if里面,这不像C语言里面右花括号可以识别,所以保持良好的代码风格也很重要哦),不然会报错。(你可以测试一下,会爆什么错误。)
二. Tansformer实现
我这里是直接克隆的hugging face的项目。哦对了,网上还有很多是使用pip install transformers这样的命令直接调取的,因为我后续想要debug代码,所以不想采取这种方式。
1.克隆代码仓库
$ git clone https://github.com/huggingface/transformers.git #克隆项目在使用这个命令你可能会出现卡在把某一个连接中,而导致连接超时。你可以选择设置git clone的镜像获取,也可以采取下面的方式:(注意:我不建议在Windows下下载然后将压缩包移动到虚拟机中,因为我之前就是但是后续还是会出现连接超时的问题,感觉治标不治本,而且可能在不同环境中下载里面的文件也会有所不同,直接复制可能会出现与Linux系统不同的情况。最好避免)
我选择了使用码云 (Gitee) 作为中转,具体步骤如下:
- 访问 Gitee 官网并登录/注册: Gitee - 基于 Git 的代码托管和研发协作平台 注意一下:注册的用户名不要用中文,因为这个会成为你之后的路径的一部分(你懂的)。如果之前已经注册过了并使用的中文,可以在个人资料中修改。
- 创建新仓库并选择“导入仓库”: 在 Gitee 页面点击"+" 新建
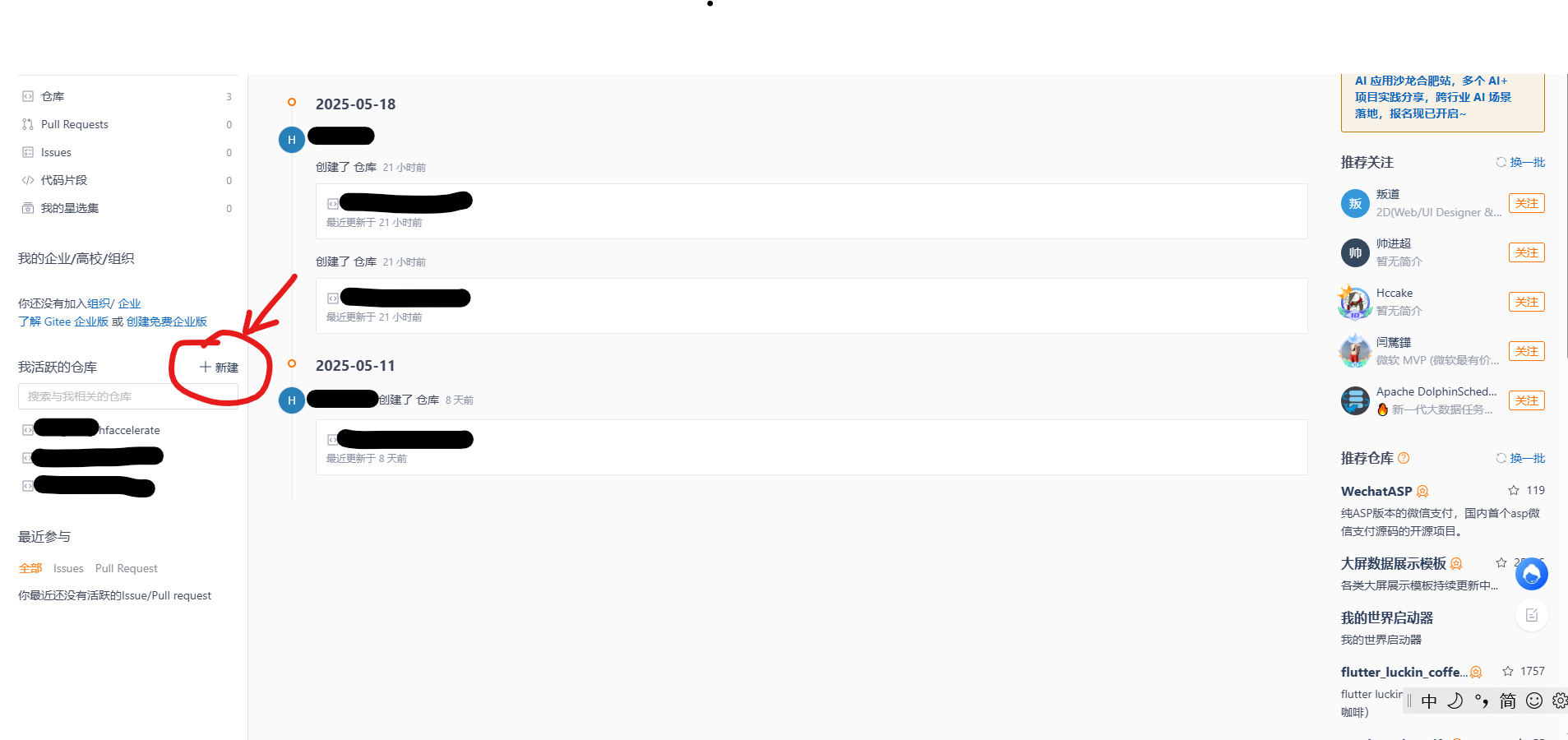
- 进入之后,点击导入
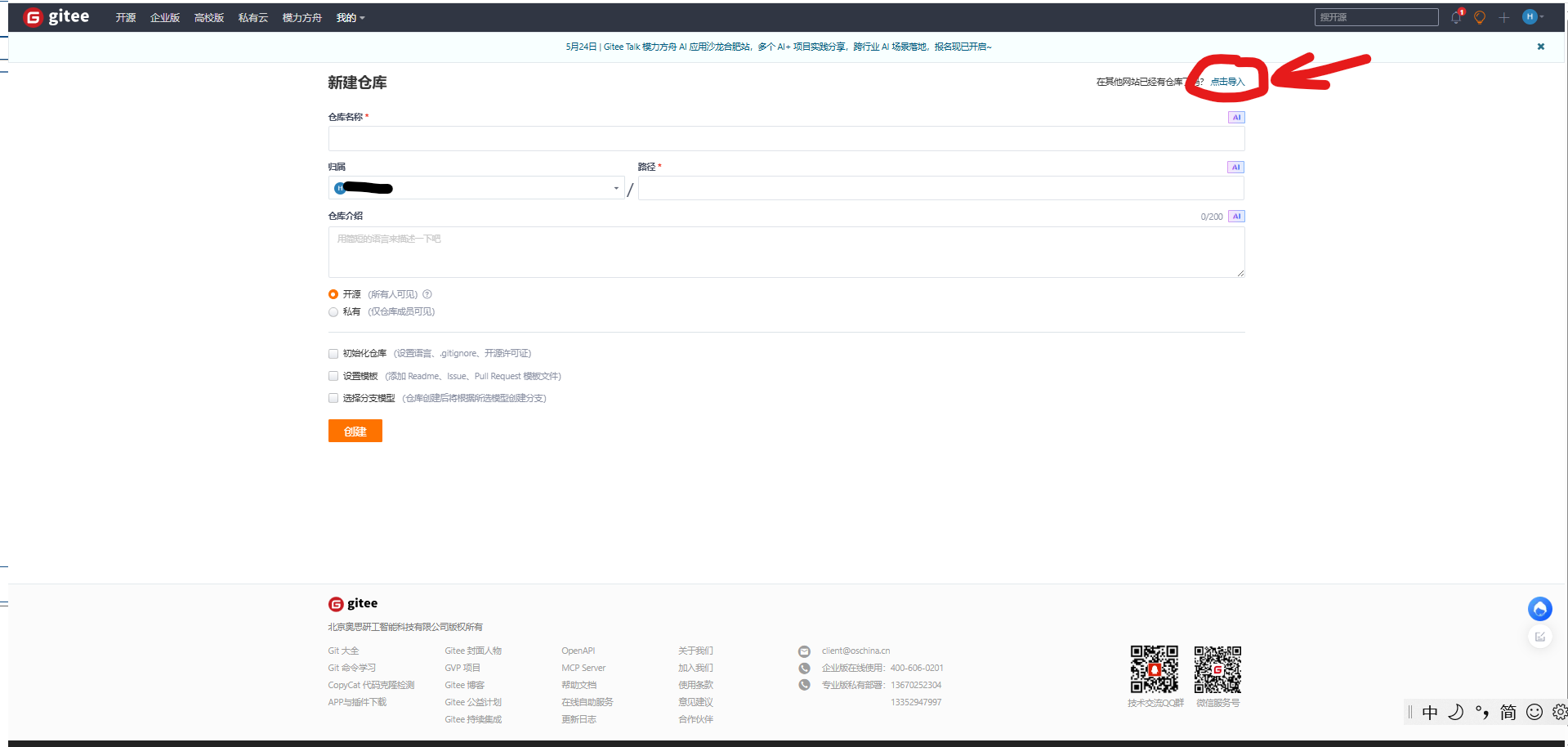
- 粘贴 GitHub 仓库的 URL: 将你想克隆的 GitHub 仓库地址(例如https://github.com/huggingface/transformers.git)粘贴到第一个输入框中
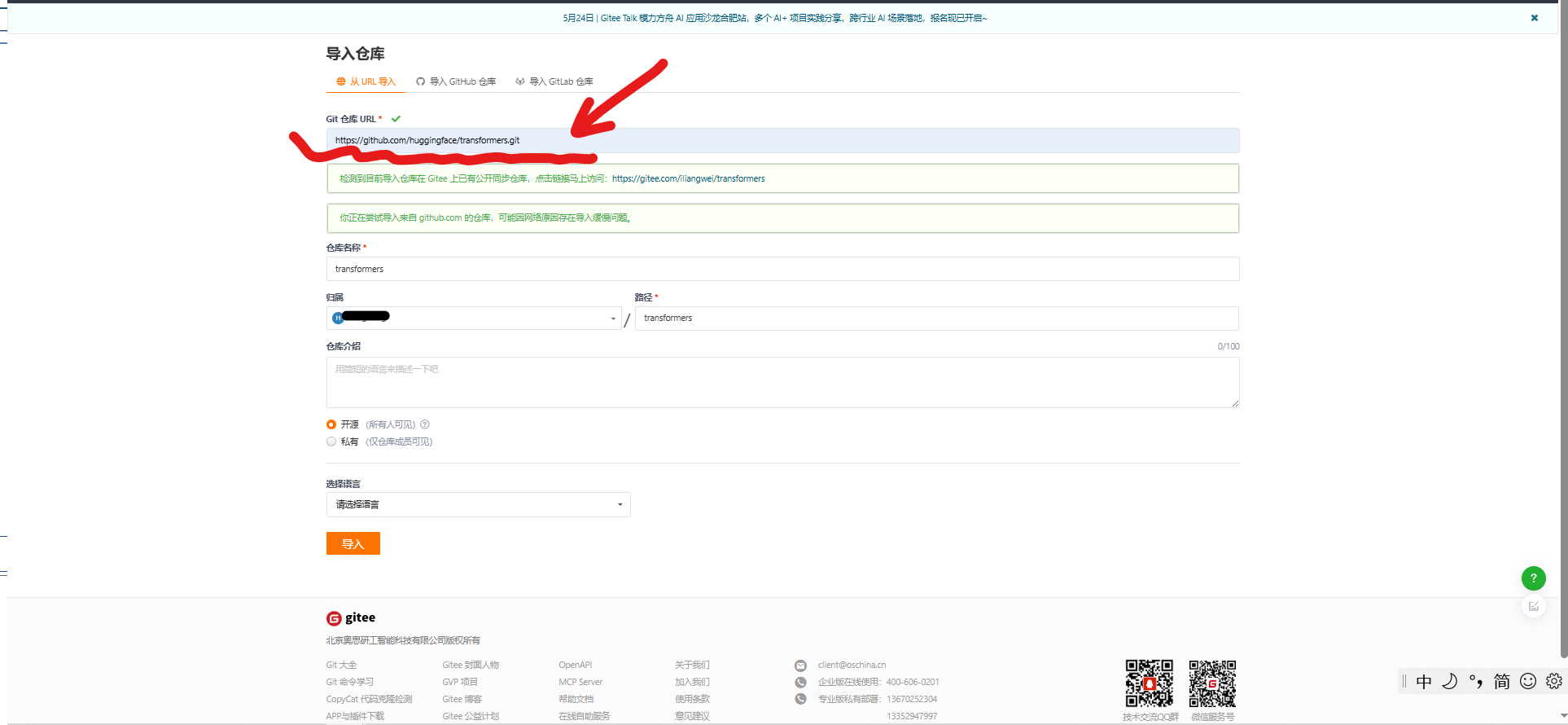
- 等待导入完成: Gitee 会开始从 GitHub 拉取仓库的所有内容。这个过程在 Gitee 服务器之间进行,通常比你直接从本地克隆快。导入进度可以在页面上看到。
- 从 Gitee 克隆仓库: 导入完成后,进入你在 Gitee 上创建的这个仓库页面。复制这个 Gitee 仓库的克隆地址(可以查看项目直接复制的)(通常是 https://gitee.com/<你的Gitee用户名>/<仓库名>.git)。
-
在你的终端中使用新的地址进行克隆:
$ git clone https://gitee.com/xx(用户名)/transformers.git2.切换到你的transformers的文件目录下,并安装transformer库和项目的相关依赖等
$ cd transformer #切换到transformer中
$ pip install -e . #安装命令我需要解释一下这个命令:
- 1. pip install: 使用 pip 包管理器进行安装。
- 2. -e .: 这是关键。-e 表示“editable”(可编辑)模式,. 表示当前目录。这条命令会读取当前目录(即 transformers 仓库目录)下的 setup.py 或 pyproject.toml 文件,并根据文件内容将 Transformers 库以及它所依赖的其他 Python 包(如 tokenizers, safetensors, tqdm, numpy, scipy 等)安装到你的 当前 Conda 环境 中。 使用 -e 模式安装的好处是,Python 环境会直接链接到你克隆下来的源代码目录。当你修改了 transformers 仓库目录中的源代码文件后,这些修改会立即在你使用这个库的代码中生效,无需重新安装。这对于后续你想调试或修改库的源码非常方便。
-
3. 验证安装(同样需要先输入 python ,进入到python的交互式命令中)
-
>>> import transformers >>> print(f"Transformers version: {transformers.__version__}") >>> try: ... from transformers import pipeline ... pipe = pipeline("sentiment-analysis") ... print("Successfully imported transformers and pipeline.") ... except Exception as e: ... print(f"Failed to import transformers components: {e}")输出结果显示:
-
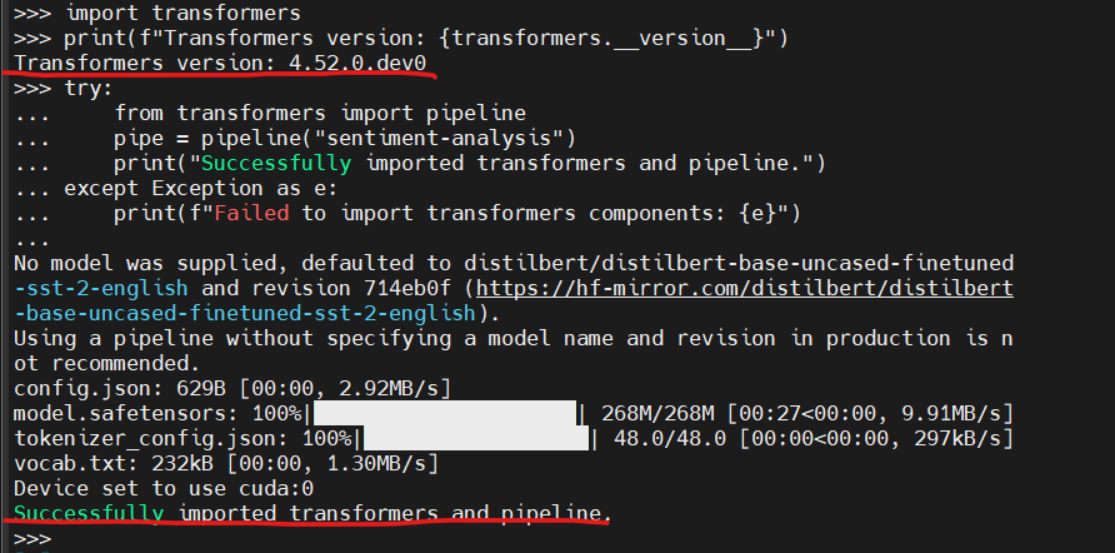
-
4. 运行项目
-
在hugging face中有很多自带的模型,如下图所示:
-

-
在这里我们选择text-classification为例进行演示,现在我们切换到该路径下(你现在应该是在transformers目录下),输入下面命令即可切换。
$ cd examples/pytorch/text-classification在这个目录下,你将会看到一个README文件,里面将给出运行的命令。这里我们就直接给出命令,不查看了。如果你要运行其他的,查看这个文件即可。(下面两条命令一行一行的输入哈!)
$ export TASK_NAME=mrpc #插入环境变量
$ python run_glue.py --model_name_or_path google-bert/bert-base-cased --task_name $TAS K_NAME --do_eval --output_dir ~/transformers_outputs/mrpc_eval/ --per_device_eva l_batch_size 32 #脚本运行命令下面,我将说一下这里会遇到的一些问题:
- 不要分行输入(也就是直接复制README中的代码),他很有可能会检测不到一些命令而报错。(具体的报错内容你可以测试一下,一般来说和图x类似)。解决方法:放在一行,向我上面那样。
- 遇到类似ModuleNotFoundError: No module named 'datasets'问题,这个最简单,没有就下载,类似的应该还有evaluate。用下面这个命令安装就好。
$ pip install datasets evaluate3. 如果遇到这个问题,不要慌。把anaconda删干净了重新来就行。
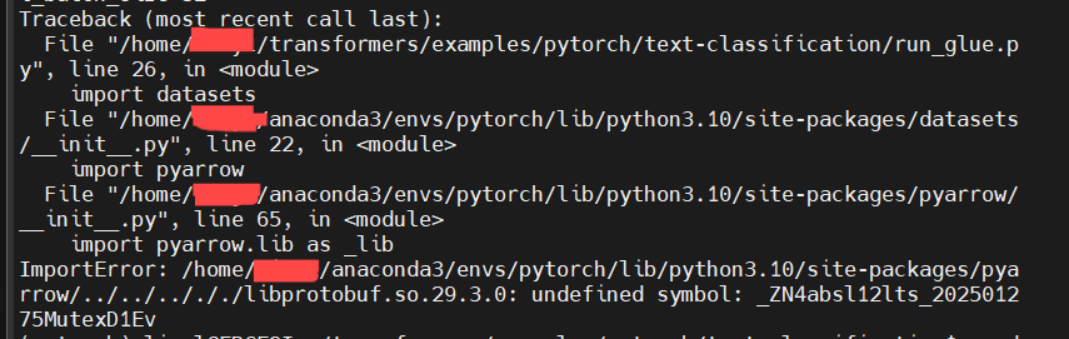
继续运行!!!!! (一行一行输入)
$ export HF_ENDPOINT=https://hf-mirror.com #添加数据源的镜像,以防止网络连接找不到
$ export TASK_NAME=mrpc #添加环境变量
$ python run_glue.py --model_name_or_path google-bert/bert-base-cased --task_name $TAS K_NAME --do_eval --output_dir ~/transformers_outputs/mrpc_eval/ --per_device_eva l_batch_size 32 #脚本执行命令5. 还有一些可能出现的其他错误
执行了上述代码,你可能会运行成功也可能不会。如果你遇到下面问题可以这样解决。
错误一:

解决方法:没有就设置一下,所以:一行一行的输入下面的命令
$ export NCCL_P2P_DISABLE="1"
$ export NCCL_IB_DISABLE="1"错误二:会遇到一些库没有安装。类似上面datasets的错误。安装就好啦!!实在不会写命令可以求助gpt相关。
6. 查看结果
一直到现在我都没有和你说过结果存在哪里的。我们仔细看一下执行脚本的这条命令,现在我们拆开来看。
$ python run_glue.py
--model_name_or_path google-bert/bert-base-cased
--task_name $TAS K_NAME --do_eval
--output_dir ~/transformers_outputs/mrpc_eval/
--per_device_eva l_batch_size 32 注意看第四行,--output_dir这里就设置了输出路径的。可以看一下我这里设置的是:~/transformers_outputs/mrpc_eval/ =/home/用户名/transformers_outputs/mrpc_eval/下面。你也可以根据自己的情况设置。哦对不用提前新建目录,他会自动生成的。想查看结果点进目录查看即可。
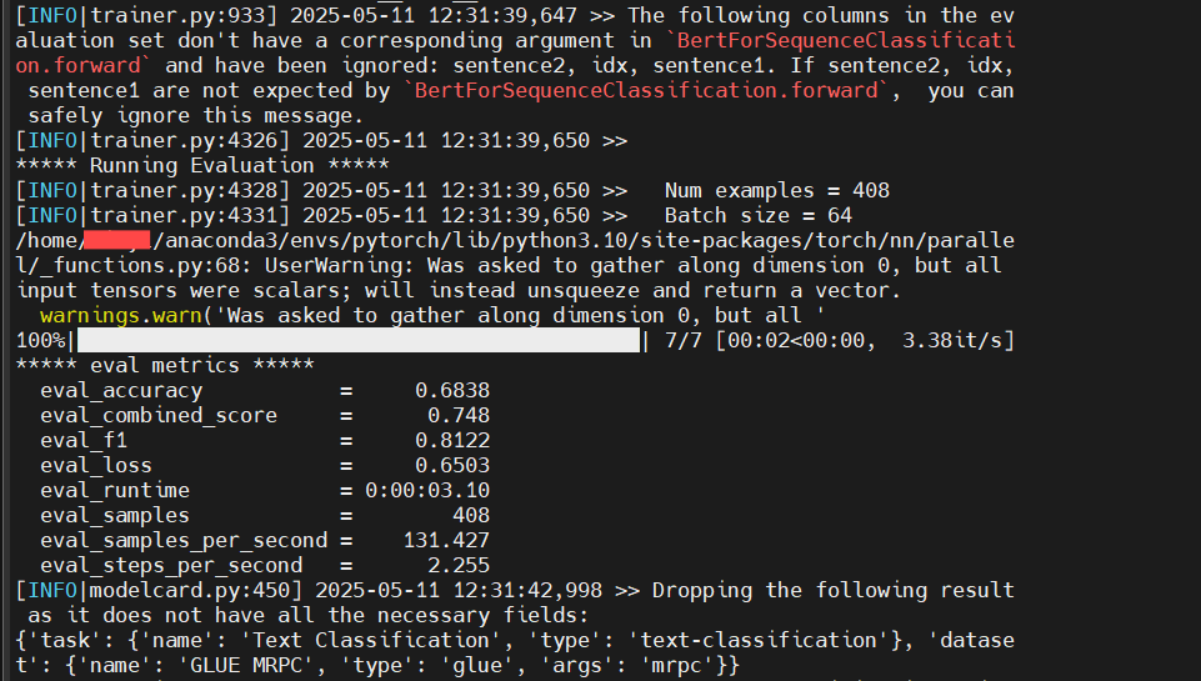
三. 未来展望
接下来我将更新,transformer代码的详解,可以期待一下o!!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









