






redis是什么:
redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库。
redis优点
a.单线程,利用redis队列技术并将访问变为串行访问,消除了传统数据库串行控制的开销
b.redis具有快速和持久化的特征,速度快,因为数据存在内存中。
c.分布式 读写分离模式
d.支持丰富数据类型
e.支持事务,操作都是原子性,所谓原子性就是对数据的更改要么全部执行,要不全部不执行。
f.可用于缓存,消息,按key设置过期时间,过期后自动删除
redis的数据结构

每种数据结构至少有两个内部编码,根据不同的情况选择不同的内部编码,如ziplist很省空间,但是列表元素很多时效率就会降低效率
除此之外还有三种数据结构:
bitmap:BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现,能求并集交集,统计签到情况等
GEO:Redis 的 GEO 特性在 Redis 3.2 版本中推出, 这个功能可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作
Hyperloglog:Redis 的基数统计,这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV)、在线用户数等。但是它也有局限性,就是只能统计数量,而没办法去知道具体的内容是什么。
常用数据结构的方法:
STRING结构:

LIST结构:

SET结构:

HASH结构:

ZSET结构:

其中:
SET和ZSET中没有重复元素;
相比SET,ZSET具有排序功能;
ZSET和HASH的value也是键值对形式:ZSET(score,member)、HASH(field,value);
STRING类型中不仅仅是存储字符,也可以存储数值(整数、浮点数);
5种数据结构最终存储的数据类型实际只有两种:字符和数值,Redis能够区分存储的值是字符还是数字;
Redis中常用命令
在redis-cli中对于输入的命令会有智能提示

| 命令 | 作用 |
|---|---|
| HELP | 获取命令的帮助信息,学会help命令很重要 |
| DEL | 删除key及对应的值 |
| EXPIRE | 设置键的过期时间,过期的键连同与该键相关的数据都将被删除 |
help命令:

-
STRING
Redis对字符串提供了丰富的操作,在Redis中STRING结构用于存储两种类型的数据:- 数值(整数、浮点数)
- 字符串(byte string)
| 命令 | 作用 |
|---|---|
| SET | 向指定的key中写入值 |
| GET | 从指定的key中获取值 |
| INCR | 将指定key的值加1 |
| DECR | 将指定key的值减1 |
| INCRBY | 将指定key的值加上指定的数值 |
| DECRBY | 将指定key的值减去指定的数值 |
| APPEND | 向value中追加内容 |
| GETRANGE | GETRANGE key-name start end获取指定索引范围(字符串可看作是字符组成的数组)的字符,当start=0且end=-1时获取整个字符串 |
| SETRANGE | `设置指定偏移量的字符的值 |
| GETBIT | GETBIT key-name offset 将字符串看做是二进制形式(bit string),并返回指定偏移量位置处的二进制位的值 |
| SETBIT | 设置指定偏移量位置处的二进制位的值 |
| BITCOUNT | 返回字符串中二进制位值为1的二进制位数 |
| BITOP | 对字符串执行位运算,并将计算结果存储到指定的key中 |
对于BITCOUNT命令,专门写了一段程序进行验证,效果图如下:
c#代码:

redis-cli中执行bitcount命令的结果:

-
LIST
| 命令 | 作用 |
|---|---|
| LPUSH | 将一个或多个值推入列表左端 |
| RPUSH | 将一个或多个值推入列表右端 |
| LPOP | 移除并返回列表最左端的值 |
| RPOP | 移除并返回列表最右端的值 |
| LINDEX | 根据索引获取LIST中的值 |
| LRANGE | 获取LIST中索引在指定范围内的值 |
| LTRIM | 从LIST中删除索引不在指定范围内的值,这里的索引范围是闭区间 |
-
HASH

| 命令 | 作用 |
|---|---|
| HSET | 向HASH表中添加元素,由上图可以看出HASH结构中存储的值也是一个键值对(field value) |
| HMSET | 一次向HASH表中写入多个键值对 |
| HGET | 获取HASH中存储的值 |
| HMGET | 一次从HASH中获取多个值 |
| HLEN | 获取HASH表中存储的元素个数 |
| HDEL | 删除HASH表中的键值对 |
| HEXISTS | 判断HASH中是否包含指定field的键值对 |
| HKEYS | 获取HASH中的所有键(field) |
| HVALS | 获取HASH中的所有值 |
| HGETALL | 获取HASH中的所有键值对 |
| HINCRBY | 将HASH中的指定value增加指定的数值 |
-
SET
SET中没有重复元素,向SET中添加重复的数据只会存储一份。
| 命令 | 作用 |
|---|---|
| SADD | 向SET中添加元素 |
| SREM | 移除SET中的元素 |
| SISMEMBER | 判断某元素是否存在于SET中 |
| SCARD | 返回SET中的元素个数 |
| SMEMBERS | 返回SET中的所有元素 |
| SSCAN | 通过迭代的方式返回SET中的所有元素 |
| SMOVE | 将元素从某一集(如果该元素存在当前集合中)合移动到另一集合并返回当前元素 |
集合间运算
| 命令 | 作用 |
|---|---|
| SDIFF | 对SET集合进行补集运算(存在于第一个集合且不存在于第二个集合中的元素)并返回运算结果 |
| SDIFFSTORE | 对SET集合进行补集运算并将运算结果存储到一个新的SET集合中 |
| SINTER | 对SET集合进行交集运算并返回运算结果 |
| SINTERSTORE | 对SET集合进行交集运算并将运算结果存储到一个新的SET集合中 |
| SUNION | 对SET集合进行并集运算并返回运算结果 |
| SUNIONSTORE | 对SET集合进行并集运算并将运算结果存储到一个新的SET集合中 |
-
ZSET
ZSET和SET一样,没有重复元素,但和SET相比它有排序功能。
| 命令 | 作用 |
|---|---|
| ZADD | 向ZSET中添加元素 |
| ZREM | 移除ZSET中的元素 |
| ZCARD | 获取ZSET中元素的个数 |
| ZSCORE | 获取ZSET中元素的score值 |
| ZRANK | 获取ZSET中元素的索引 |
| ZREMRANGEBYRANK | 从ZSET中移除指定索引范围内的元素 |
| ZREMRANGEBYSCORE | 从ZSET中移除指定score范围内的元素 |
| ZCOUNT | 获取ZSET中score值在指定范围内元素的个数 |
| ZRANGE | 获取ZSET中索引在指定范围内的元素,ZRANGE key start stop,参数start=0且stop=-1时返回所有元素 |
集合间运算
| 命令 | 作用 |
|---|---|
| ZINTERSTORE | 对ZSET集合进行交集运算并将运算结果存储到一个新的ZSET集合中 |
| ZUNIONSTORE | 对ZSET集合进行并集运算并将运算结果存储到一个新的ZSET集合中 |
慢查询:
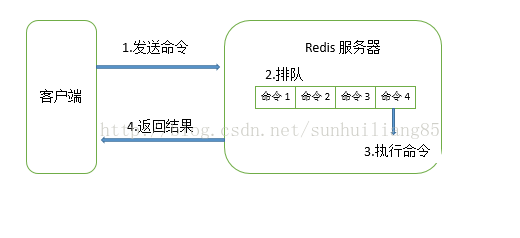
慢查询只执行在执行命令处。
系统在命令执行前后计算每条命令的执行时间,当超过预定阀值时,记录命令的发生时间,耗时,命令的详细信息等。
慢查询的两个配置参数:
- slowlog-log-slower-than: 单位微秒(1秒=1000毫秒=1000,000微妙),指定redis执行命令的最大时间,超过将记录到慢查询日志中, 不接受负值,如果设置为0,每条命令都要记录到慢查询日志中.
- slowlog-max-len: 设置慢查询日志长度,如果慢查询日志已经到最大值,如果有新命令需要记录,就将最老那条记录删除.
获取慢查询的配置信息
192.168.10.151:7777> config get slowlog-log-slower-than
1) "slowlog-log-slower-than"
2) "10000"
192.168.10.151:7777> config get slowlog*
1) "slowlog-log-slower-than"
2) "10000"
3) "slowlog-max-len"
4) "128"设置慢查询参数
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1024
config rewrite192.168.10.151:7777> slowlog get 1
1) 1) (integer) 464
2) (integer) 1521098693
3) (integer) 19342
4) 1) "INFO"每个命令都有4个属性组成,分别是慢查询日志的标识ID,发生时间戳、命令耗时、执行命令和参数
获取当前慢查询日志列表的长度
192.168.10.151:7777> slowlog len
(integer) 128慢查询日志重置, 其实是清除了慢查询日志
slowlog reset
pipeline:
通过减少客户端与redis的通信次数来实现降低往返延时时间,而且Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性
但是redis命令行无法实现pipline我们可以通过jedis实现
public static void setup(){
//链接jedis服务器
Jedis jedis=new Jedis("localhost",6379);
//jedis.sadd("1","uf");
//System.out.println(jedis.smembers("1"));
Pipeline pipeline=jedis.pipelined();
pipeline.smembers("1");
pipeline.get("db");
List<Object> piplineRes=pipeline.syncAndReturnAll();
System.out.println(piplineRes);
}这样通道里存储了我们写入的多个执行方法,最后输出
pipeline通过减少客户端与redis的通信次数来实现降低往返延时时间,而且Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性
需要注意到是用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。















 1628
1628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









