







Redis 性能影响 - 异步机制和响应延迟
一. 异步机制
首先,我们来看下Redis实例在运行的时候,可能发生交互的几个角色,以及他们主要做了哪些事情:
- 客户端:网络
IO、键值对的增删改查API调用、数据库操作。 - 磁盘:生成
RDB快照、AOF日志记录、AOF日志重写。 - 主从节点:主库生成和传输
RDB文件、从库接收RDB文件、从库数据库清空、从库RDB加载。 - 切片集群实例:向其他实例传输哈希槽信息、数据迁移。
1.1 Redis 阻塞点
首先是第一点,和客户端进行交互:
- 我们知道
Redis中使用了IO多路复用机制,避免了主线程一直处于等待网络连接的状态,因此网络IO并不是导致Redis阻塞的主要因素。 - 主要在于
Redis底层数据操作时的时间复杂度。例如一个简单的Hash键值对查找,只用O(1)的时间复杂度。但是一旦涉及到范围查找,全量查找,集合差并集等操作,那么操作的时间复杂度就是O(N)了。 - 此外
bigkey的删除和内存的申请分配,这个过程也是非常耗时的。那么自然而然的,对于Redis实例中所有键值对的清除操作,即flushdb操作,也是导致Redis阻塞的一个点。
备注:内存释放流程。
释放内存的时候,操作系统先将释放掉的内存块插入一个空闲内存块链表,以便后续进行内存的管理和再分配。这个果子会阻塞当前释放内存的应用程序。
bigkey删除的测试以及对应消耗的时间(来源 Redis 核心技术与实战)
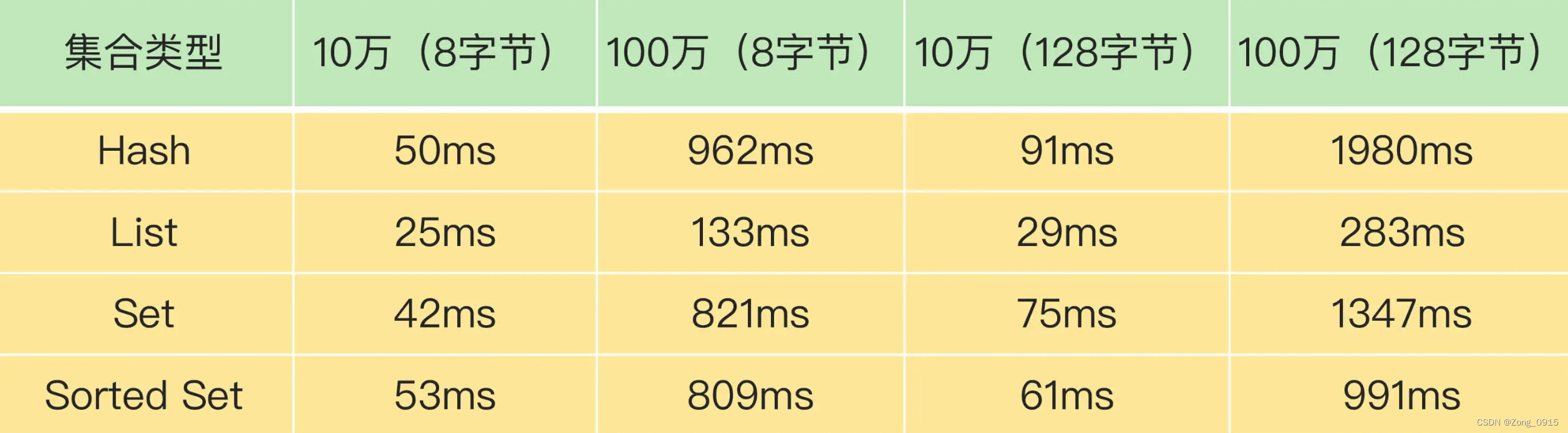
第二点:和磁盘交互:
- 这一块主要是和
AOF的日志操作有关。AOF同步在always策略下写回磁盘的这个过程会阻塞主线程。而生成RBD快照以及AOF的重写操作都是交给子进程来完成的,不影响主进程。具体可以在复习下AOF 写回策略。
第三点:和主从节点交互:
- 主从集群中,主库主要是生成
RDB文件,并传输给从库。虽然创建和传输RDB文件都是由子进程来完成的。但是fork子进程的这个过程会阻塞。阻塞的时间取决于拷贝的内存大小,实例越大,内存页表越大,fork时间也就越久。同样可以复习下AOF 写回策略。 - 从库在接收完
RDB文件后,首先会清除自身的数据,即flushdb操作,这个过程会阻塞,上文有提及。而加载RDB的过程中,从库也会阻塞。
第四点:和切片集群实例交互:
- 首先,
Redis集群中,哈希槽的信息会在实例之间相互传递,而数据迁移是渐进式执行,因此对于Redis的阻塞影响不大。 - 倘若迁移了
bigkey,此时就会造成主进程的阻塞。
阻塞点总结下就是:
- 集合范围查找或者聚合操作。对于客户端而言,需要得到其结果。
bigkey的删除、创建。迁移bigkey。对于客户端而言,无需返回结果。- 清空数据库操作。对于客户端而言,无需返回结果。
AOF日志同步写回磁盘操作。对于客户端而言,无需返回结果。- 从库加载
RDB文件。对于客户端而言,需要其加载完毕才能使用。
1.2 Redis 异步子线程优化机制
针对上述总结,Redis主要针对三个点去做了异步优化:
Redis主线程启动的时候,就会调用操作系统提供的pthread_create函数去创建3个子进程,分别负责bigkey删除、数据库清除、AOF日志同步写。- 主线程通过一个任务队列和子进程进行交互。以删除操作为例,会将对应的操作封装成一个任务,放到队列里面,然后给客户端返回信息表明删除完成。(这里实际上数据并未被删除,需要等待子进程去执行真正的内存释放操作)即惰性删除
lazy free。
除此之外,Redis4.0之后还提供另外的两个功能,用于异步的键值对删除和数据库清除工作:
- 键值对删除:对于集合类型的
bigkey,建议使用unlink命令。 - 数据库清空:可以再
flushdb命令后面跟着async选项,既可以让子线程在后台异步清空数据库。即flushdb async。 - 倘若是4.0版本前的,可以通过
scan命令先读取数据,在进行删除。这一部分建议使用pipeline,因为没有批量删除的相关API,只能一条一条删除。
Redis中Pipeline是什么东西?
首先,常规的来说,我们客户端和Redis实例进行交互的时候,模式就是这样的:响应-->请求,响应-->请求,响应-->请求。3次来回。
而管道Pipeline的作用就是将上述的模式改为:响应,响应,响应-->请求,请求,请求。1次来回。
这里以Jedis的使用为例(也有Spring整合Redis,使用redisTemplate的情况)
@Test
public void testPipelined() {
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 10; i++) {
pipelined.hset("testPipelined", "testId_" + i, String.valueOf(i));
}
List<Object> objects = pipelined.syncAndReturnAll();
System.out.println(objects);
}
结果如下:

1.3 惰性删除 lazy-free
惰性删除 lazy-free是Redis4.0新增的功能,默认关闭,需要手动开启。有这么几个相关的配置项:
lazyfree-lazy-expire:key在过期删除时尝试异步释放内存。lazyfree-lazy-eviction:内存达到maxmemory并设置了淘汰策略时尝试异步释放内存。lazyfree-lazy-server-del:执行rename、move等命令或需要覆盖一个key时,删除旧key尝试异步释放内存。replica-lazy-flush:主从全量同步,从库清空数据库时异步释放内存。
注意:在开启了lazy-free的情况下,需要使用unlink命令才有可能异步删除key,使用del依旧是同步删除。
上面4个相关配置中,除了最后一点,其他的异步策略都是可能发生的。这和key的类型、编码方式以及元素数量有关。只有在以下几种情况下,Redis才会开启异步内存释放:
Hash/Set类型的Key:底层采用哈希表存储并且元素数量超过64个的时候,Redis - 数据结构和持久化机制。ZSet类型的Key:底层采用跳表存储,并且元素数量超过64个的时候。List类型的Key:链表节点数量超过64个。(此处并非元素数量,每个节点可能有多个元素)
集合类型比较特殊,但是相对而言比较常见的就是String类型的,可见,String类型的键值对,不管其占用内存有多大,都是在主线程上完成内存释放操作的,所以,如果bigkey越大,那么主线程阻塞的时间也就越久。
最后再说下scan跟keys相比有什么优劣势:
- 首先
scan和keys命令都是通配查找,时间复杂度都是O(N)。 - 但是
scan命令可以不用阻塞主线程,keys命令是阻塞的。 scan命令需要进行迭代多次返回,根据游标来。同时返回的数据可能有重复。
scan命令的Java使用案例:
@Test
public void testScan() {
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 10; i++) {
pipelined.set("key:" + i, "value_" + i);
}
pipelined.sync();
// 游标初始值为0
String cursor = ScanParams.SCAN_POINTER_START;
ScanParams scanParams = new ScanParams();
// 模糊匹配
scanParams.match("key:*");
scanParams.count(3);
while (true) {
ScanResult<String> scanResult = jedis.scan(cursor, scanParams);
List<String> result = scanResult.getResult();
cursor = scanResult.getCursor();
System.out.println("当前获取结果:" + result + " 拿到的游标值:" + cursor);
if ("0".equals(cursor)) {
break;
}
}
}
结果如下:

二. 如何应对 Redis 变慢的情况
我们看下下面的架构图,红色的三个部分是影响Redis性能的三大因素:
Redis自身的操作特性。- 文件系统。
- 操作系统。
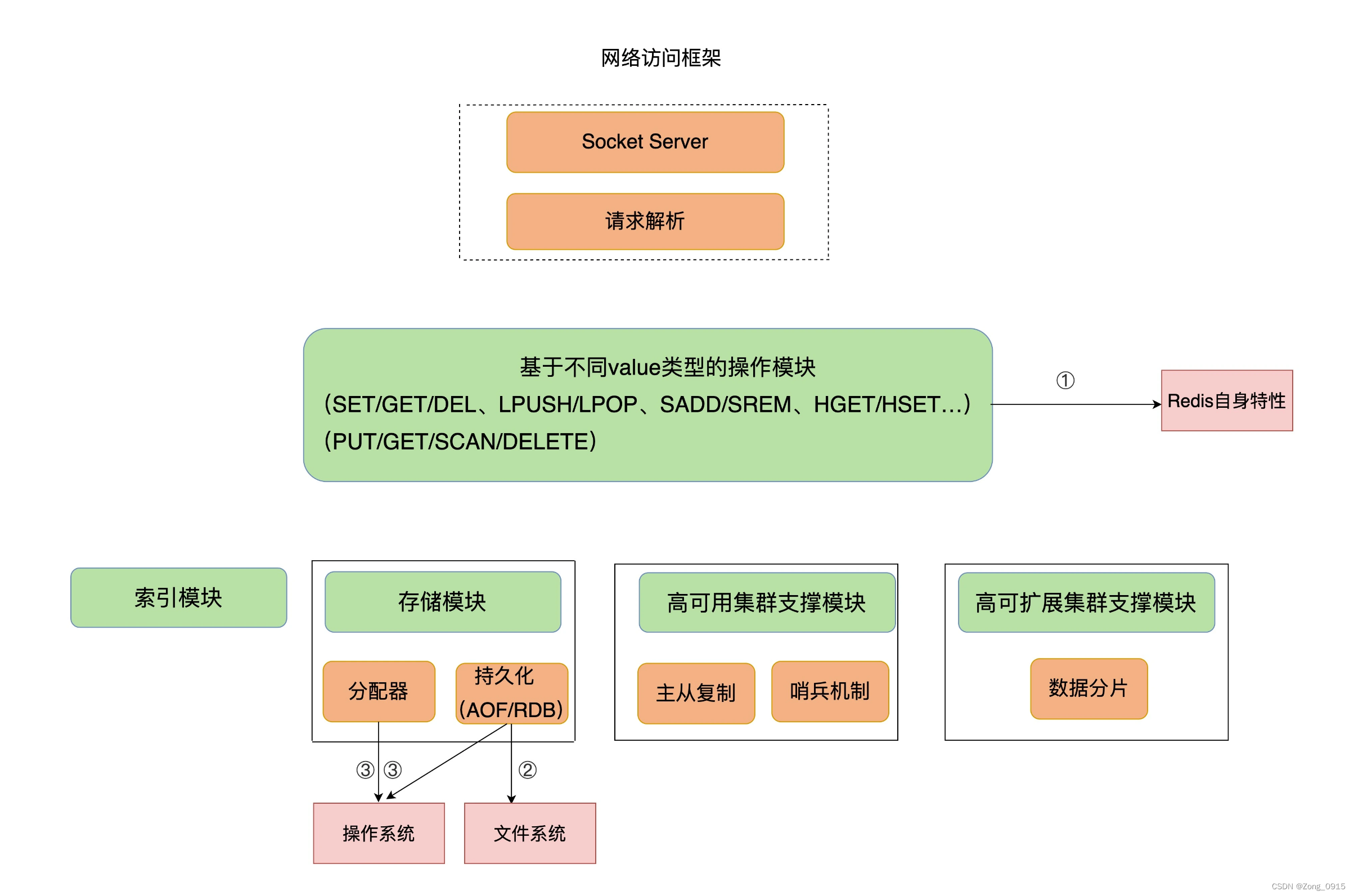
2.1 确定慢的原因是否在于Redis自身
首先,我们应该去确认变慢的原因是否在于Redis本身。即查看Redis的响应延迟有多少。
通过以下命令即可:
./redis-cli --latency -h host -p port
结果如下:

或者是基于当前的Redis实例环境做基线性能判断:系统在低压力、无干扰下的基本性能。
# 打印120秒内检测到的最大延迟。
./redis-cli --intrinsic-latency 120
结果如下:会阶段性的打印 截止当前时刻最久的响应时长。

以上两种情况给出的数据都是仅供参考,因为Redis如果变慢了,真正的原因是需要具体分析的。
2.2 Redis自身操作特性的影响
这一块主要涉及到两点:
- 慢查询命令。
- 过期
key操作。
2.2.1 是否由大量慢查询命令导致的慢
首先需要确定这一点,是否存在大量的慢查询命令,再去解决。主要通过慢查询日志来查看。首先慢查询日志有几个相关的配置项:
-
slowlog-log-slower-than:慢查询日志的时间阈值,单位微妙,默认10000微妙。
值为0:所有命令都记录到慢日志中。
值为负数:禁止使用慢查询日志。 -
slowlog-max-len:慢查询日志长度,默认128。当日志满了的时候,最老的一条记录将会被删除。
可以通过以下命令临时配置(redis.conf文件上编辑才是永久生效):
config set slowlog-log-slower-than 0
config set slowlog-max-len 10
使用命令查看慢查询日志,内容如下:

倘若通过慢查询日志发现,确实存在大量的慢查询日志,那么可以开始做对应的处理了:
- 第一种情形:用其他高效命令代替。例如使用
sscan命令替代smembers命令(获取某个集合中的所有数据),避免一次性返回大量数据,造成线程阻塞。 - 第二种情形:倘若业务上涉及到了集合的交并集操作(数据量庞大的情况下),可以让其在客户端完成,不在
Redis上操作。
2.2.2 检查 Redis 对过期 key 的操作策略
Redis中对过期key有着专门的自动删除机制,默认情况下具体流程如下:
- Redis中有个配置项
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP,默认值为20。这里简称为M。首先Redis每100毫秒就会采样M个key,并将其中过期的key全部删除。 - 倘若剩余的
key中,有超过25%的key依旧是过期的,那么重复删除的过程,直到过期key的比例降低至25%以下。 - 也因此,一般情况下,每秒钟会删除200个
key。
问题在于:Redis删除过期key,释放其内存空间的这一个动作是阻塞的。倘若在同一时间内,有大量的key同时过期,就会造成Redis不断的去执行删除操作,从而导致主线程的阻塞。
当然,Redis4.0之后是可以对这个问题进行优化的。可以复习下1.2小节的内容。解决方案如下:
- 首先同一时间内大量
key过期(有点缓存雪崩的味儿了昂),我们只需要在业务代码中,往Redis中插入数据的时候,尽量给key通过EXPIREAT命令设置不同的过期秒数。 - 倘若某一部分数据,对这部分数据的过期时间要求比较高,可以加上一个一定大小范围内的随机数。这样,既保证了
key在一个邻近时间范围内被删除,又避免了同时过期造成的压力。
2.2.3 scan命令相关问题
上文提到过,使用scan命令返回的数据可能有重复。除此之外,对scan命令问的最多的就是是否会漏掉key。那么这里做个解释。
首先请读者了解Redis的rehash机制(还没听过的点这里Redis - 数据结构和持久化机制).
scan命令不会漏key的原因:
Redis在Scan遍历全局哈希表的时候,是采用高位进位法的方式遍历的。- 哈希表扩容的时候,会将旧哈希表中的数据映射到新哈希表。同时保留原来的先后顺序。
- 这样就保证遍历的时候不会遗漏也不会重复。
scan命令得到重复key的原因:(在哈希表缩容情况下)
- 遍历过的哈希桶在缩容的时候,会映射到新哈希表中没有遍历到的位置。
- 因此继续遍历新哈希表的时候,会对同一个
key返回多次。
值得注意的一点是,在上文中有涉及到scan命令的使用,其中还有个count的设置,其意思就是每次查询返回的key数量不会超过count的值。但是实际使用的时候却可能存在偏差。理由如下:
- 当使用
Hash/Set/Sorted Set这几种集合去存储数据并且元素数量比较少时,底层会采用intset/ziplist方式存储(数组和压缩列表),如果以这种方式存储,在执行HSCAN/SSCAN/ZSCAN命令时,会无视count参数,直接把所有元素一次性返回。 意思就是此时得到的元素数量 >count值。 - 底层转化为哈希表或者跳表存储的时候,才会真正地使用
count参数。作为返回个数的上限。
2.3 文件系统的影响
Redis的性能也受其文件系统影响。最主要的就是AOF日志。我们知道,AOF日志有三种写回策略:no、everysec。always。而它们依赖于文件系统的两个操作调用来完成:
write:只需要将日志记录到内核缓冲区中,就可以返回。fsync:主要负责将日志写回到磁盘中,完成之后才可以返回。
然后我们再回顾一下以下几个知识点:
everysec模式下:Redis会使用后台子进程异步完成fsync操作。每秒调用一次。always模式下:每执行一个操作,就调用一次fsync操作。no模式下:先调用write写日志文件,再由操作系统周期性地将日志写回磁盘。
针对上述情况,有这么几个阻塞点:
AOF日志很大的时候,会进行AOF重写,虽然这个步骤是由子进程来完成的。但是AOF重写会对磁盘进行大量IO操作,同时,fsync又需要等到数据写到磁盘后才能返回,所以,当AOF重写的压力比较大时,就会导致fsync被阻塞。- 在执行
fsync的时候,倘若发现上一次fsync操作还没有执行完毕,就会阻塞。因此对于always模式,倘若后台子进程执行fsync操作比较频繁,主线程也会随之受到影响。
总的来说就是:AOF日志文件太大 以及 fsync 操作比较频繁。会影响主线程的性能。
那么接下来就是如何去改善这个情况。
-
首先,根据你自身的业务来判断,
Redis中的数据可靠性级别应该是哪种?如果Redis仅仅是当做一个缓存的作用,那么是不是可以排查下写回策略是否配置了always? -
如果对延迟十分敏感,可以尝试配置
no-appendfsync-on-rewrite = yes;该选项会在AOF重写期间避免调用fsync,而是将数据暂存在内存中就返回。
2.4 操作系统的影响
操作系统这里有一个潜在的瓶颈:操作系统内存的swap部分。
- 正常情况下,
Redis的操作是在内存上进行的。 - 倘若机器内存不够,一旦
swap被触发了,Redis的请求操作需要等到磁盘数据读写完成才行,swap触发后影响的是Redis主线程,这会极大地增加Redis的响应时间。
由于触发swap机制的主要原因是机器的物理内存不足,因此可以参考以下几种方案去解决:
- 增加
Redis实例所在的机器内存。 - 使用
Redis集群,把压力分摊开来。
另外的一个细节点就是:Linux系统的内存大页机制(THP)
总的来说就是该机制支持2MB大小的内存页的分配。而常规来说的内存页分配维度是4KB。
我们知道,Redis利用了写时复制技术(可以点击这里复习),在执行快照的同时,正常处理写操作。总的来说就是将数据拷贝一份。 那么在这个背景下,倘若开启了内存大页机制,会有什么影响?
- 如果采用了内存大页,那么,即使客户端请求只修改
1KB的数据,Redis也需要拷贝2MB的大页. - 如果是常规内存页机制,只用拷贝
4KB。 - 当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响
Redis正常的访存操作,最终导致性能变慢。
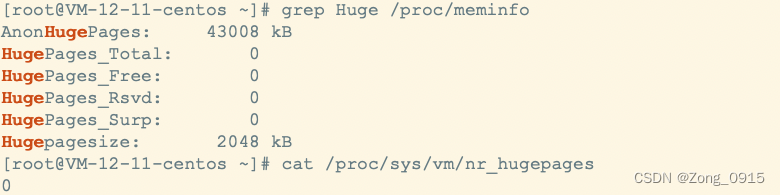
内存大页机制查看是否开启:
cat /sys/kernel/mm/transparent_hugepage/enabled
结果如下:

关闭:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.d/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
grep Huge /proc/meminfo
cat /proc/sys/vm/nr_hugepages
结果如下:
2.5 总结 ☆
上文说了不少,那么在发现Redis变慢的时候,可以按照以下几个步骤来排查问题。
1.使用slowlog查看是否存在一些复杂度比较高或全量查询的命令(sort,suion等)。
解决:
- 用分批查询替代全量查询。
- 复杂命令可以放到客户端做。
2.排查bigkey。
./redis-cli --bigkeys -a 你的Redis密码
结果如下:
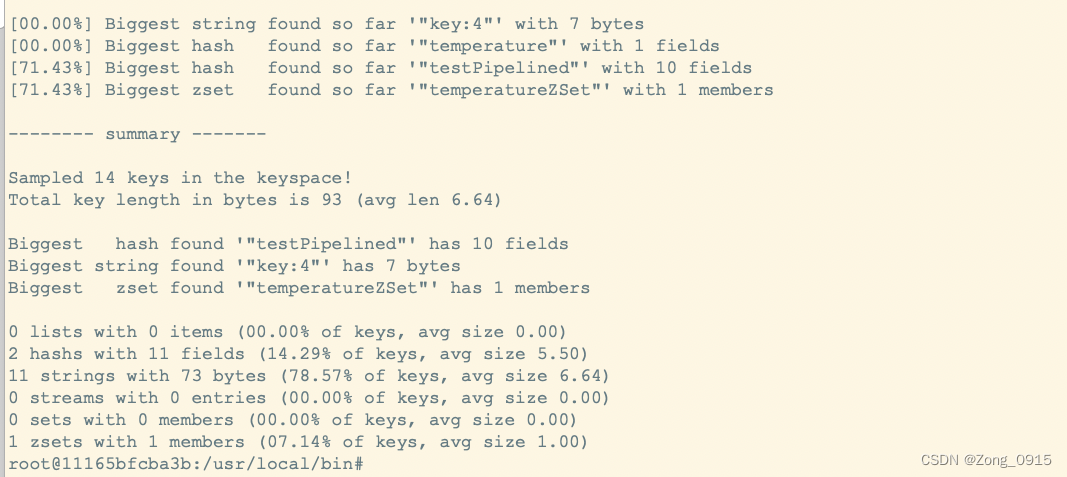
这时候就可以优化业务了,避免存储bigkey。倘若Redis版本在4.0以后,可以开启lazy-free机制。
3.给key增加一个随机的过期时间。避免大量key集中过期。
4.倘若业务上不需要数据的高可靠,那么可以视情况而定修改回写策略。always模式下,对Redis的性能影响比较大。比如可以改成everysec模式,并且对于数据丢失不敏感的业务可以关闭AOF。
5.避免操作系统开启swap,可以适当调大Redis实例内存。或者部署Redis集群。
6.关闭透明大页机制。
















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











