







文章目录
1、分析网页
当我们去爬取网页时,首先要做的就是先分析网页结构,然后就会发现相应的规律,如下所示:
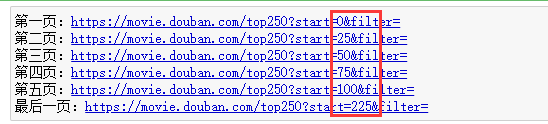
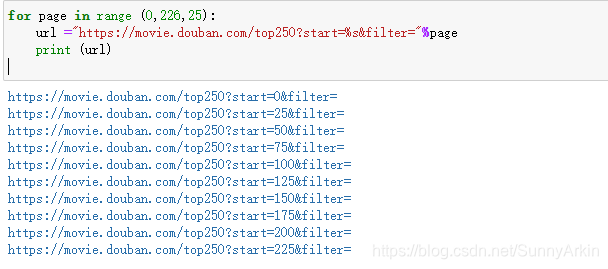
生成链接:从网页链接的规律中可得写一个for循环即可生成它的链接,其中它的间隔为25,程序如下:
for page in range (0,226,25):
url ="https://movie.douban.com/top250?start=%s&filter="%page
print (url)
得到的结果如下:
2、请求服务器
在爬取网页之前,我们要向服务器发出请求
2.1导入包
没有安装requests包的要先进行安装,步骤为:1.win+R运行——2.cmd回车——3.输入命令pip install requests
2.2设置浏览器代理
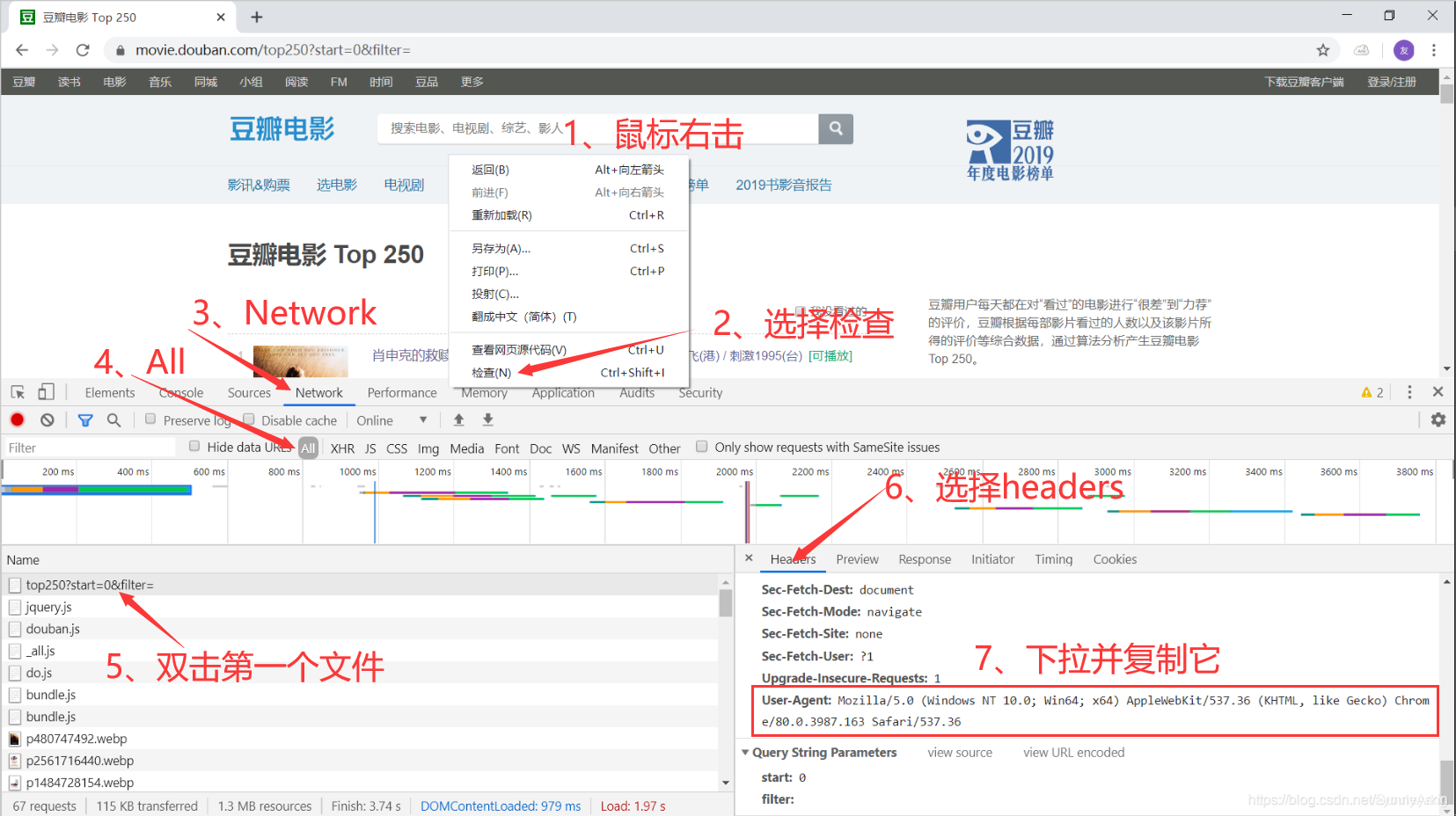
设置浏览器代理的代码如下:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
2.3请求服务器格式
请求源代码,向服务器发出请求,如果在后面加上.text表示输出文本内容,代码如下图所示:
requests.get(url = test_url, headers = headers)
2.4请求服务器代码汇总
import requests
#pip安转 pip install requests————>win+r,运行————>cmd,回车,————>pip
test_url = 'https://movie.douban.com/top250?start=0&filter=' #''格式化,为字符串
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
#请求源代码,向服务器发出请求,200代表成功
reponse = requests.get(url = test_url, headers = headers).text
# 快捷键运行,Ctrl+Enter
3.xpath提取信息
3.1获取xpath节点的方法
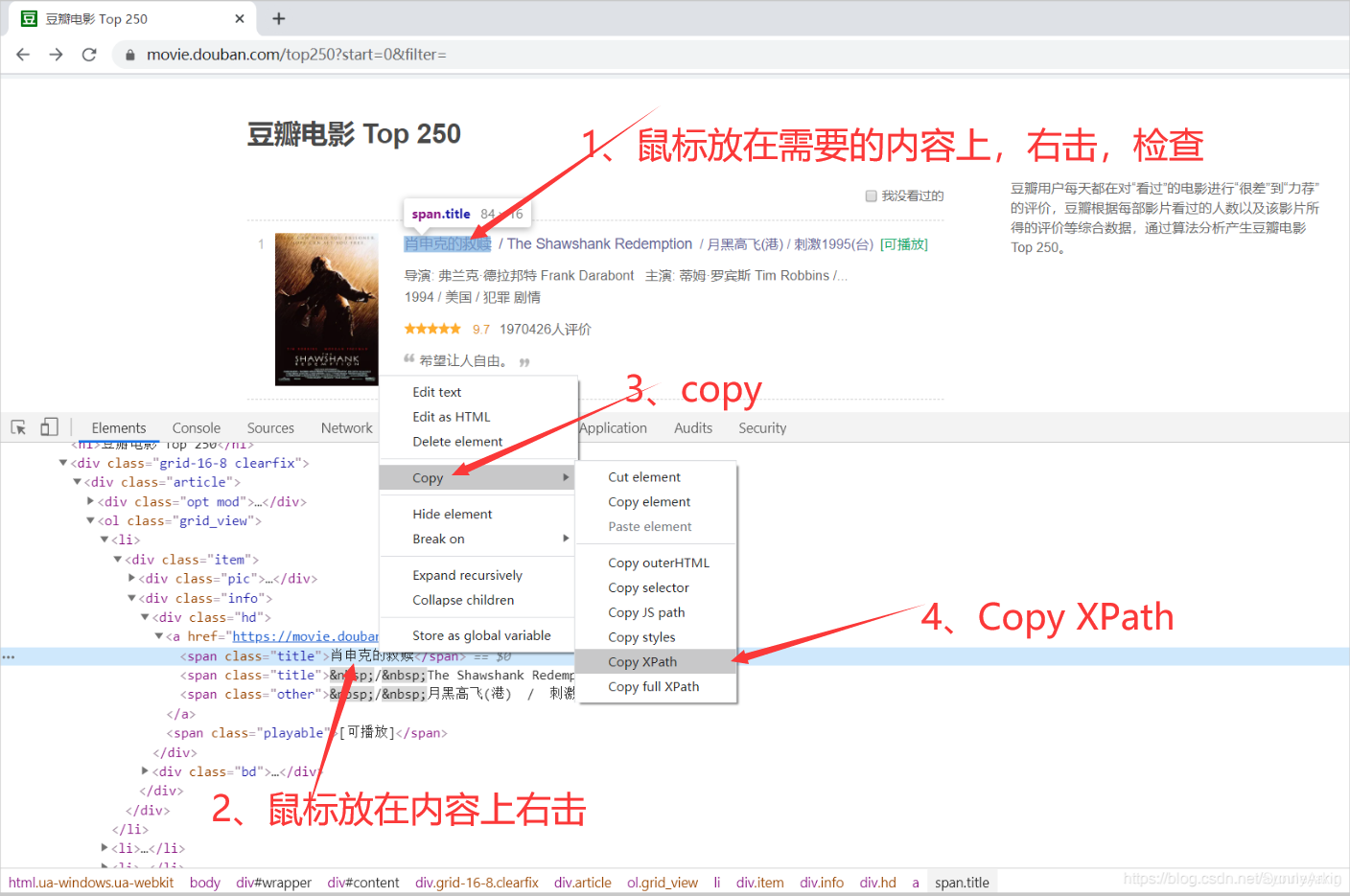
3.2xpath提取内容
from lxml import etree #导入解析库
html_etree = etree.HTML(reponse) # 看成一个筛子,树状
3.2.1提取文本
当我们在提取标签内的文本时,要在复制的xpath后面加上/text()
如《霸王别姬》:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









