






爬虫入门(自用)
第一篇 Python 爬虫入门之 电影top250爬取
前言
为了记录一下爬虫学习过程 爬取db电影top250榜单
一、前置知识
requests库
requests是一个python的HTTP客户端库
支持HTTP特性
保持活动和连接池
国际域名和URL
Cookie持久性保持
浏览器式SSL验证
不严谨地说,就是能让你的代码能连接到网页。
正则表达式(re库)
正则表达式(或 RE)指定了一组与之匹配的字符串;模块内的函数可以检查某个字符串是否与给定的正则表达式匹配(或者正则表达式是否匹配到字符串,这两种说法含义相同)。
简单来说,因为开发人员在写这个网页源代码的时候,写的代码会比较工整,这样我们容易按某种规律找到想要的信息。举个例子在豆瓣电影top250这里我们想要爬到每部电影的标题,鼠标右键单击网页,打开网页源代码,找到电影标题这里
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1291546/" class="">
<span class="title">霸王别姬</span>
<span class="other"> / 再见,我的妾 / Farewell My Concubine</span>
</a>
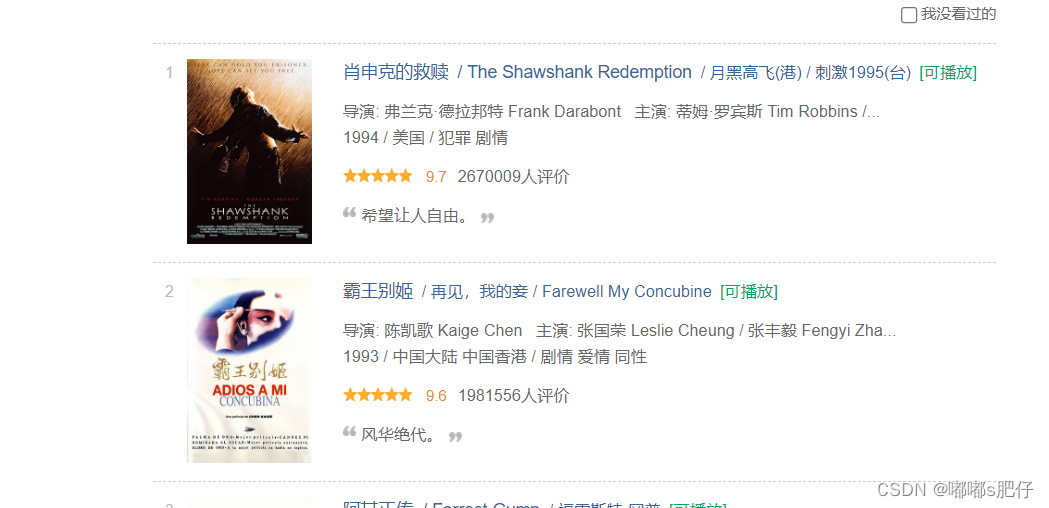
发现,电影的标题都放在以下这样的结构中
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">
换言之,只要自己制定一个规则(正则表达式找到以上这种有共性的结构),然后在网页源代码里面找到符合制定规则的就能够定位到想要的信息(电影名字)
以下是一些模式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
注意 .匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。”其中re.DOTALL标记就是指re.S标记。
举个例子,对
湖南省长沙市雨花区非诚县人大代表湖南省长沙市苏因镇第九届人大代表
湖南省.*?人大代表 就会返回湖南省长沙市雨花区非诚县人大代表。
二、使用步骤
1.引入库
代码如下:
import requests
import re
2.小试牛刀
代码如下(示例):
url = "https://movie.douban.com/top250"
resp = requests.get(url)
page_content = resp.text
print(page_content)
此时,并没有返回网页内容。这是因为网站识别出来这是一个爬虫,导致返回数据为空。这个时候就需要让爬虫伪装成人类用户/浏览器,解决办法参考以下链接使用请求头
此时返回结果

到这里为止,我们已经成功爬取了豆瓣top250榜单。
接下来为了取我们想要的信息:名称,年份,评论人数,就要使用正则表达式了。应该怎样写一个正则表达式以便我们能够爬取这些信息?
首先,使用re.compile(pattern [, flags])方法来制定规则,参数指定为re.S,这是什么意思?
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)#
该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的
匹配,在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为pattern.search(string)的调用方式。参考https://www.cnblogs.com/nomorewzx/p/4203829.html
(?P<name>)观察源代码可以发现,正则表达式在这个地方会匹配到电影名字,而这个地方使用这个函数是为了做出标记,以便后续进行print。不懂的话参考https://blog.csdn.net/qq_35696312/article/details/95051232
此时正则表达式已经编写好了,后续循环地对他们进行输出
result = obj.finditer(page_content)
for it in result:
print(it.group("name"))
finditer方法参考https://zhuanlan.zhihu.com/p/43074437
此时返回结果为
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
这个杀手不太冷
美丽人生
千与千寻
辛德勒的名单
盗梦空间
星际穿越
忠犬八公的故事
楚门的世界
海上钢琴师
三傻大闹宝莱坞
机器人总动员
放牛班的春天
无间道
疯狂动物城
大话西游之大圣娶亲
熔炉
控方证人
教父
当幸福来敲门
触不可及
怦然心动
只有25条结果,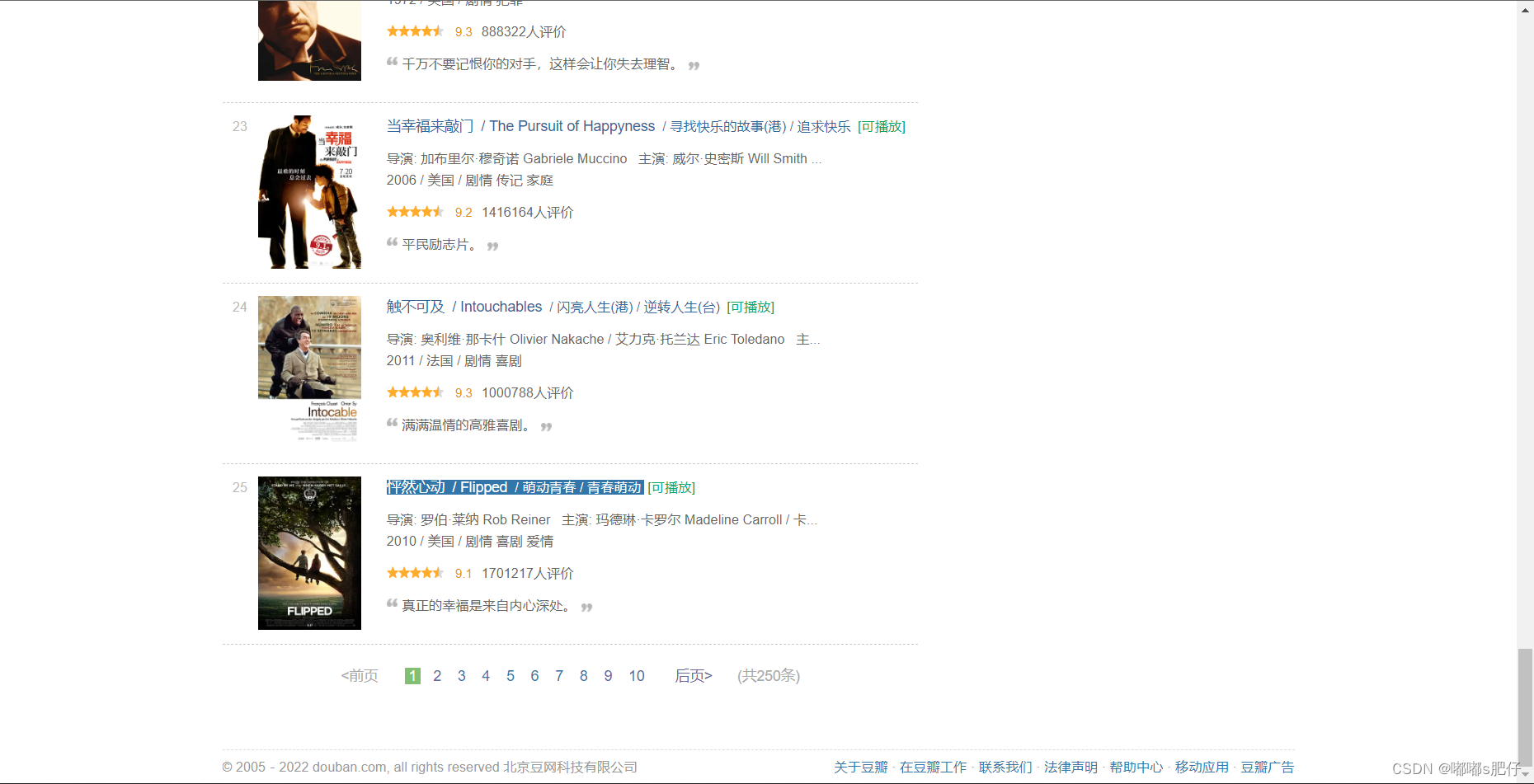
回到网页可以发现,一页只有25条结果,想要得到top250的所有电影,应该得实现翻页功能,观察网址可以发现
当start = 0时,为第一页,25时为第二页,以此类推…
那么我们可以写一个循环来实现翻页的功能。
总结
综上,所有代码如下
import requests
import re
headers = {
"user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"
}
for i in range(0,250,25):
url = "https://movie.douban.com/top250?start="+str(i)+"&filter="
resp = requests.get(url,headers = headers)
page_content = resp.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)#
result = obj.finditer(page_content)
for it in result:
print(it.group("name"))
print("over")















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









