









 本文详细介绍了后缀树的概念、构造方法以及在模式匹配、字符串查询等领域的应用。通过实例展示了如何利用后缀树解决字符串匹配问题,并探讨了其在实际场景中的高效性。
本文详细介绍了后缀树的概念、构造方法以及在模式匹配、字符串查询等领域的应用。通过实例展示了如何利用后缀树解决字符串匹配问题,并探讨了其在实际场景中的高效性。
之前有篇文章([算法系列之二十]字典树(Trie))我们详细的介绍了字典树。有了这些基础我们就能更好的理解后缀树了。
一 引言 模式匹配问题
给定一个文本text[0…n-1], 和一个模式串 pattern[0…m-1],写一个函数 search(char pattern[], char text[]), 打印出pattern在text中出现的所有位置(n > m)。
这个问题已经有两个经典的算法:KMP算法 ,有限自动机,前者是对模式串pattern做预处理,后者是对待查证文本text做预处理。在进行完预处理后,可以到达O(n)的时间复杂度,n是text的长度。
后缀树可以用对text进行预处理,构造一个text的后缀树,就可以在 O(m) 的时间内搜索任意一个pattern,m是模式串pattern的长度。
二 简介
后缀树提出的目的是用来支持有效的字符串匹配和查询,例如上面的问题。后缀树(Suffix tree)是一种数据结构,能快速解决很多关于字符串的问题。后缀树的概念最早由Weiner 于1973年提出,既而由McCreight 在1976年和Ukkonen在1992年和1995年加以改进完善。
总结一句:一个给定的文本text的后缀树就是一个压缩的后缀字典树。
前面一篇文章我们已经讨论了 字典树(Trie),下面先让我们来了解一下压缩字典树( Compressed Trie)。
三 压缩字典树( Compressed Trie)
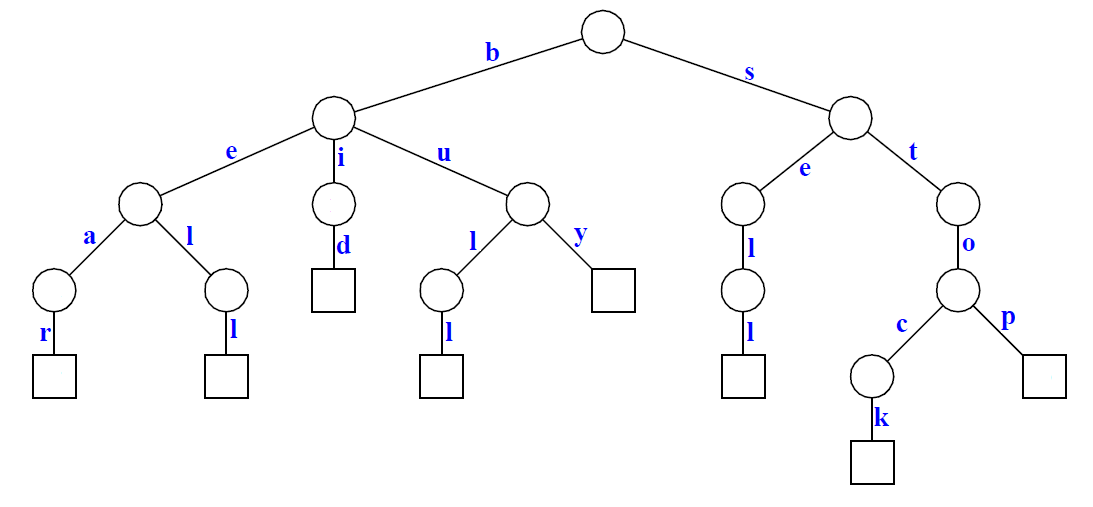
我们以一下一组单词来介绍一下什么是压缩字典树:
{bear, bell, bid, bull, buy, sell, stock, stop}
我们以上面一组单词构建一个字典树如下:
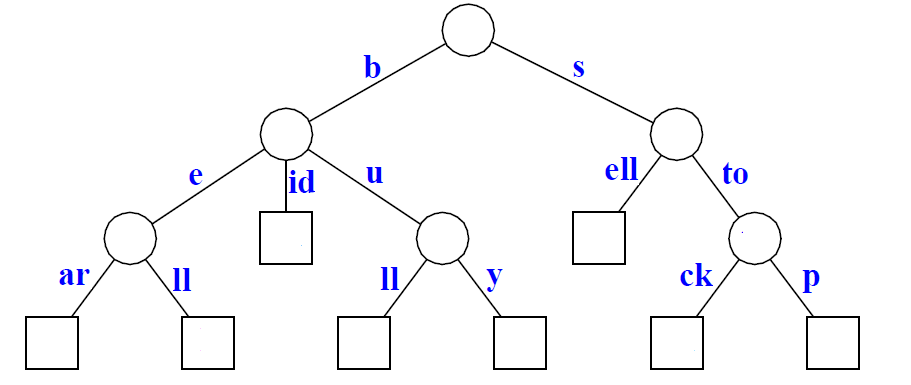
下面就是压缩字典树。压缩字典树是从字典树转换而来,把字典树中的单节点链条进行压缩。即一个没有分叉的单边,进行压缩。
四 后缀压缩字典树
经过以上讨论,我们知道后缀树是文本text所有后缀的压缩字典树。一个后缀树的生成经过一下几步:
(1)生成给定文本text的所有后缀。
(2)视所有后缀为有效单词,生成一个压缩字典树。
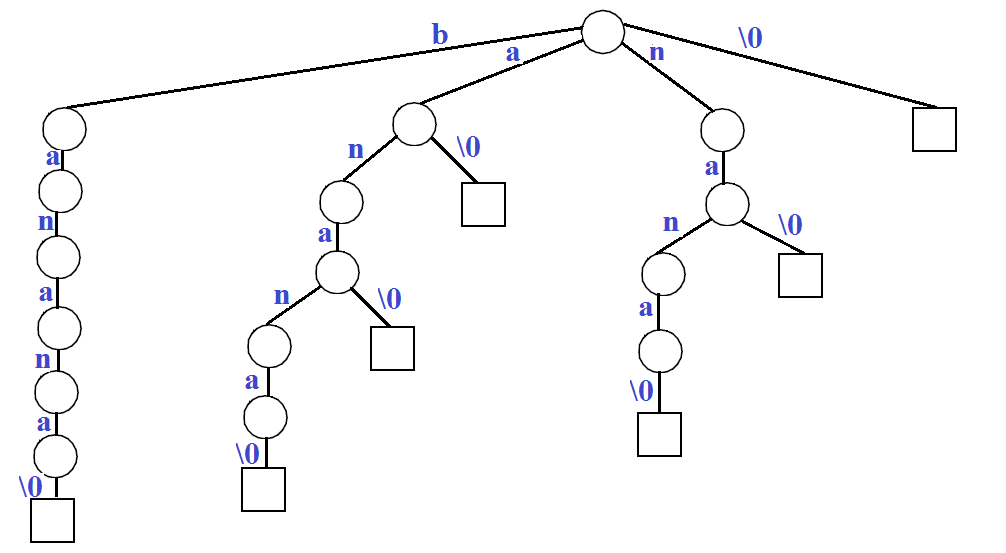
我们以”banana\0”(’\0’是结束字符)为例,字符串的所有后缀为:
banana\0
anana\0
nana\0
ana\0
na\0
a\0
\0
假设我们考虑以上字符串的所有后缀均为有效单词,构造一个字典树如下:
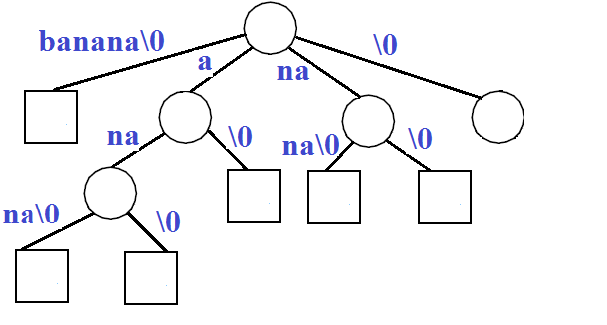
如果我们合并单节点链条,我们得到如下压缩字典树,即给定文本”banana\0”的后缀树。
至此,我们已经了解了什么是后缀树了。
五 后缀树应用
(1)从目标串S中判断是否包含模式串T(Pattern Searching)
方案:用S构造后缀树,按在Trie中搜索子串的方法搜索T即可。
原理:若T在S中,则T必然是S的某个后缀的前缀。
例如:S = "leconte" T = "con",查找T是否在S中,则T(con)必然是S(leconte)的后缀之一"conte"的前缀。
(2)从目标串S中查找串T重复次数
方案:用S+'$'构造后缀树,搜索T节点下的叶节点数目即为重复次数
原理:如果T在S中重复了两次,则S应有两个后缀以T为前缀,重复次数就自然统计出来了。
(3)从目标串S中查找最长的重复子串(Finding the longest repeated substring)
方案:原理同2,具体做法就是找到最深的非叶节点。
这个深是指从root所经历过的字符个数,最深非叶节点所经历的字符串起来就是最长重复子串。
为什么要非叶节点呢?因为既然是要重复,当然叶节点个数要>=2。
(4)从目标串T和S中查找最长公共子串(Finding the longest common substr ing)
方案:将S1#S2$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。
(5)从目标串T中查找最长的回文子串(Finding the longest palindrome in a string)
引用:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











