






1,概念
1)静态查找和动态查找
①静态查找
查找某个特定元素是否在查找表中;
查找找个元素的对应属性。
包括有序表、分块有序表、线性有序表。
性能分析:平均查找长度:ASL=1/(n+1)
存储在顺序介质如磁带上,无法随机读写自然无法二分与分块。
②动态查找表
表结构在查找过程中动态生成,对于给定的key,若表中存在某关键字与key相等则返回查找成功,若不存在则插入。
包括:二叉排序树、平衡二叉树、B树、B+树、键树。
2)平均查找长度(Average Search Length,ASL)
2,顺序查找(线性查找、无序查找)
适合于存储结构为顺序存储或链接存储的线性表。
复杂度:O(n)
3,二分查找(折半查找)
1)概念
有序表顺序存储查找。
2)场景
要求在排序的数组中查找一个数字或者统计某个数字出现的次数。
对于需要频繁删除或插入的数据集来说,维护有序排列工作量很大,不建议使用。
3)复杂度分析
最坏情况下,关键词比较次数为log2(n+1),且期望时间复杂度为O(log2n);
ASL = log(n+1) - 1
4)应用
①旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
解题思路:用二分查找法寻找这个最小元素。
举例:3 4 5 1 2 ,low = 0, high = 4,mid = 2; a[mid]>a[low],所以最小数在mid后面。
low = 3, high = 4, mid = 3, a[low] < a[high],两个位于第二个数组中,最小元素为 a[3] = 1.
5)代码
private static int binarySearch(int[] a, int length, int x) {
int left=0;
int right=length-1;
int mid;
while(left<=right){
mid=(left+right)/2;
if(a[mid]==x){
return mid;
}else if(a[mid]>x){
right=mid-1;
}else{
left=mid+1;
}
}
return -1;//未找到返回-1
}6)扩展
①插值查找
基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
复杂度分析:查找成功或者失败的时间复杂度均为O(log2(log2n))。
②斐波那契查找
也是二分查找的一种提升算法,通过运用黄金比例(1:0.618)的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
复杂度分析:最坏情况下,时间复杂度为O(log2n),且其期望复杂度也为O(log2n)。
3,二叉排序树(二叉查找树,BinarySearch Tree,二叉搜索树)
1)概念
BST或者是一棵空树,或者是具有下列性质的二叉树:
1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2)若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3)任意节点的左、右子树也分别为二叉查找树。
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
2)复杂度分析
插入和查找的时间复杂度均为O(logn),
但是在最坏的情况下仍然会有O(n)的时间复杂度。
3)其它树的查找详见树的部分。
4,分块查找(索引顺序查找)
是顺序查找的一种改进。
1)算法思想
将n个数据元素”按块有序”划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须”按块有序”;即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
由于一般块内可以无序,因此块内可以方便地减少增加。
2)算法流程:
step1 先选取各块中的最大关键字构成一个索引表;
step2 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。

3)性能分析
ASL = 分块查找的平均长度+块内顺序查找的平均长度
5,哈希查找
1)构造哈希函数方法
哈希函数跟查找速度密切相关。对于要查找的字段A,哈希函数的选择跟A以及A的类型关系密切。
常见方法:直接定址法、数字分析法、平方取中法、折叠发、保留余数法、随机数法
是一种用空间换的方法。
2)处理冲突的方法
线性探测法。
①开放定址法
H0 = H(key)
Hi =( H (key) + di ) MOD m其中 m 为表的长度
除留余法:m选择小于长度的最大质数比较好。
对增量di有三种取法:
i>线性探测再散列
di = 1 , 2 , 3 , … , m-1,即冲突后,依次放后续空位。
举例:55 1 23 14 68 11 82 36 19
H(key) = key MOD 11。
| 数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | 55 | 1 | 23 | 14 | 68 | 11 | 82 | 36 | 19 | ||
| 查询次数 | 1 | 1 | 2 | 1 | 3 | 6 | 2 | 5 | 1 |
装填因子:n/m (其中n 为关键字个数,m为表长)
例如:35,10,21,40,45,36,30,27 填装因子为0.8,用线性探测再哈希法解决冲突,平均查找长度是?
填装因子0.8,8个元素,说明表长为10。则平均查找长度为2.
ii>平方探测再散列(二次探测再散列)
冲突后:加1的平方;减1的平方,加2的平方,减2的平方,加3的平方,减3的平方……
举例:55 1 23 14 68 11 82 36 19
H(key) = key MOD 11。
| 数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | 55 | 1 | 23 | 14 | 36 | 82 | 68 | 19 | 11 | ||
| 查询次数 | 1 | 1 | 2 | 1 | 2 | 1 | 4 | 1 | 3 |
23:1冲突;1+1^2 = 2
68:2冲突;2+1^2 = 3冲突; 2-1^2 = 1冲突; 2+2^2 = 6.
11:0冲突;0+1^2 = 1冲突;0-1^2 = -1 即10.
36:3冲突;3+1^2 = 4
iii>随机探测再散列
di 是一组伪随机数列
②再哈希法
再来另一个哈希函数计算。
③链地址法(拉链法)
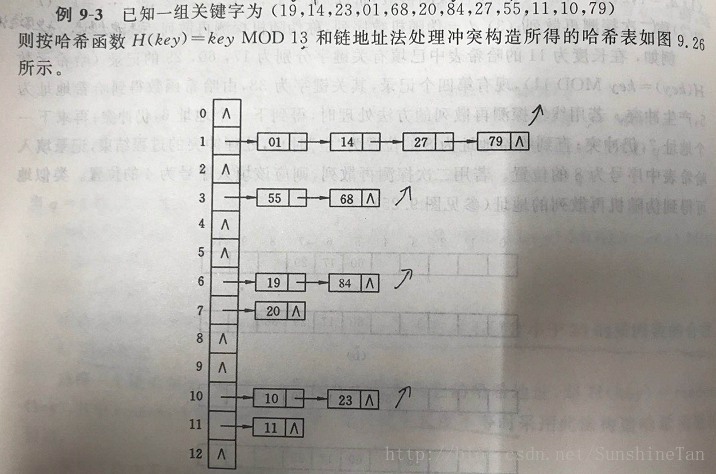
平均查找长度ASL = (1 * 6 + 2 * 4 + 3+4)/12
④建立一个公共溢出区
只要发生冲突,都填入溢出表。
3)大量记录的哈希表
对于很多的记录,组成的哈希表长度不可能很长,因此要解决散列冲突,不能在常数时间内找到记录。
可以吧哈希表映射到文件中,分级查找。
4)复杂度
拉链式哈希表最坏情况是所有记录的散列值都冲突,这样就退化为线性查找,时间复杂度为O(n)。
对于无冲突的哈希表,时间复杂度为O(1)。
6,Bloom Filter
1)概念
是一种空间效率和时间效率都很高的随机数据结构,用来检测一个元素是否属于一个集合。
2)场景
适合应用在对于低错误率可以容忍的场合、用来检测一个元素是否属于一个集合。
3)优缺点
优点:插入和查询时间都是常数,另外它查询元素却不保存元素本身,具有良好的安全性。
缺点:
①牺牲了正确性。它判定结果有2种:不属于这个集合(绝对正确)、属于这个集合(不一定正确)。
②只能添加,不能删除(会影响其他元素的检测)
③当插入的元素越多,发生哈希碰撞概率越大,错判概率越大。
4)原理
一个简单例子:

基本原理是:位数组合Hash函数的联合使用。
①初始化:m位位数组,数组每一位都初始化为0。k个不同的Hash函数。
②插入元素:对元素做k个Hash函数得到位数组的k个位,这些位置为1.
③查询元素:对元素做k个Hash函数得到位数组的k个位,这些位如果存在不为1,则元素一定不存在。如果为1,那么可能存在(发生哈希碰撞:插入别的元素时,这些位置为1)
举例:
3个元素的集合{5, 8, 10},哈希函数的个数为3:x%2; x%5; x%3。
需要查找的数字为a。
①初始化:5位位数组,数组每一位都初始化为0。.
②插入元素:对集合中每一个元素进行三个哈希函数的计算,分别给对应的数组为置1
a[5] = {1,1,1,1,0}
③查询元素:对要查找的元素a 做3个Hash函数得到位数组的3个位,这些位如果存在不为1,则元素一定不存在。如果为1,那么可能存在(发生哈希碰撞:插入别的元素时,这些位置为1)
如a=4,a[5] = {1,1,0,0,1} ,a[4]不为1,则元素一定不存在。
3)正确率
最优哈希函数个数:k=(ln2)*(m/n),此时错误率最小。
在错误率不大于E时,m>=n*lg(1/E)*lge才能表示任意n个元素的集合。
4)举例
给定a、b两个文件,各存放50亿个url,每个url各占64B,内存限制是4GB,请找出文件a与文件b中共同的url。
(类似问题:判断一个元素是否在一个集合中、检查一个英语单词是否拼写正确、在网络爬虫中,一个网址是否被访问过。)
难点:内存只有4GB,无法一次读取所有url来比较。
①Hash法
通过对url求Hash值,把Hash值相同的url放到一个单独的文件里,把50亿个url分解成数量较小的url,然后依次读入内存进行处理。
①遍历文件a,对每个url求Hash值并散列到1000个文件中:h=hash(url)%1000。
②根据Hash结果吧这些url存放到文件fa中,通过散列,所以的url将会分布在这1000个文件(fa0,…,fa999)中。每个文件大约为300MB.同理安置文件b.显然,fa0中相同的url只可能存在于fb0中。
注意:如果经过Hash法处理后,还有小文件占的内存大小超过4GB,则采用相同的方法把文件分割为更小的文件进行处理。
②Bloom filter法
4GB表示340亿bit,把文件a中的url用Bloom filter法映射到340亿bit上,然后遍历文件b,判断是否存在。(有错误率)
7,KMP
子串查找。















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









