






1、需求描述
在如今的技术水平上,大数据处理技术对于日常生活是非常重要的。此次实验目的是为了让我们更加熟悉Spark的RDD基本操作及键值对操作;熟悉使用RDD编程解决实际具体问题的方法。为此设定以下需求:
1.pyspark交互式编程
提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
根据data.txt数据,在pyspark中通过RDD编程来计算以下内容。
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。本文给出门课的成绩(A.txt、B.txt)下面是输入文件和输出文件的一个样例。
输入文件A的样例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
输入文件B的样例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。本文给出门课的成绩(Algorithm.txt、Database.txt、Python.txt),下面是输入文件和输出文件的一个样例。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
2、环境介绍
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
spark用于实现快速通用的集群计算平台,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的MapReduce计算模型。高效的支撑更多计算模式,包括交互式查询和流处理。
Spark的优缺点及与其他技术的对比
(1)运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
(2)易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
(3)通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。
(4)随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于内存。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
应用场景:
目前大数据处理场景有以下几个类型:
1、复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
2、基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
3、基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架,第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理,第二种情况可以Impala进行交互式查询,对于第三中情况可以用Storm分布式处理框架处理实时流式数据。以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。
通过以上分析,总结Spark场景有以下几个:
lSpark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合
数据量不是特别大,但是要求实时统计分析需求
本实验具体运行的Ubuntu16.04环境如下:
Hadoop2.7.1、Spark2.1.0、HBase1.1.5、JDK1.8、Scala2.11.8、MySQL
3、数据来源描述
数据来源分为以下几类:
1、机器数据
机器数据是指服务器、网络设备等硬件或虚拟硬件运行过程中产生的状态数据,往往有对应的协议或规范,例如SNMP、IPMI、WMI等。通过机器数据可以准确的掌握业务承载平台的基本运行状态,例如CPU、内存、磁盘等资源的使用情况和网络流量情况,是运维监控领域常用的数据来源,各类开源或商业监控产品对此类数据的处理也大同小异。
2、日志数据
日志数据是指应用程序、中间件和机器等在运行过程中由事件触发而产生的文本类数据,数据格式灵活多样。
3、网络通信数据
网络通信数据是指通过抓包获取到的设备间网络通信数据,例如两台服务器之间存在网络通信,通过抓包分析可以详细的了解两台服务器之间通信的端口、协议、数据量甚至内容。。
4、拨测数据
对于IT业务系统,拨测采用的探测点可以在公网,也可以在业务系统内网,不同位置的探测点起到的作用是不同的。公网探测点主要关注业务系统的网络出口质量、运营商网络质量和CDN质量,而内网探测点主要关注的是业务或各个业务模块的可用性及性能状态。
5、用户行为数据
用户行为数据是指通过在用户终端进行埋点获取到的用户行为数据,例如在网页中通过JS埋点获取到的页面访问情况和在APP中通过SDK埋点获取到的各交互页面和控件的使用情况。
3.2本实验数据:
1、某大学计算机系的成绩数据集data.txt
2、某大学计算机系课程的学号成绩(A.txt、B.txt)
3、某大学计算机系课程的成绩包含姓名与成绩(Algorithm.txt、Database.txt、Python.txt)
4、数据上传及上传结果查看
利用U盘·将数据传输到ubuntu上,解压查看文件:
图4-1 查看文件夹内文件

1、pyspark交互式编程

图4-1-1 data.txt
2.编写独立应用程序实现数据去重
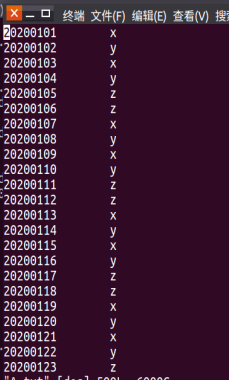
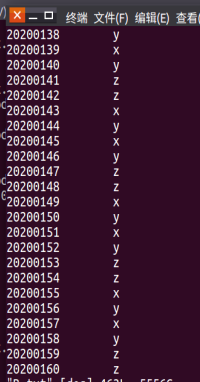
图4-2 A.txt and B.txt
3.编写独立应用程序实现求平均值问题


图4-3 Algorithm.txt、Database.txt、Python.txt
5、数据处理过程描述
5.1 pyspark交互式编程
启动pyspark

图5-1-1
(1)该系总共有多少学生;
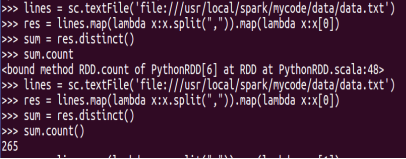
图5-1-2
(2)该系共开设了多少门课程;

图5-1-3
(3)Tom同学的总成绩平均分是多少;

图5-1-4
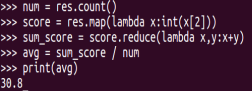
图5-1-5
(4)求每名同学的选修的课程门数;

图5-1-6
(5)该系DataBase课程共有多少人选修;

图5-1-7
(6)各门课程的平均分是多少;

图5-1-8
(7)使用累加器计算共有多少人选了DataBase这门课。
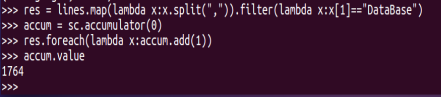
图5-1-9
5.2编写独立应用程序实现数据去重
编写代码:

图5-2-1
运行文件并查看结果:
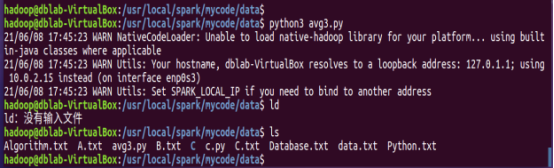
图5-2-2
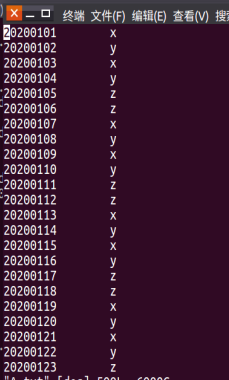
图5-2-3
5.3 编写独立应用程序实现求平均值问题
编写代码:

图5-3-1
运行文件并查看结果
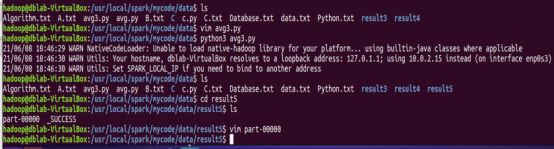
图5-3-2
查看合成的文件
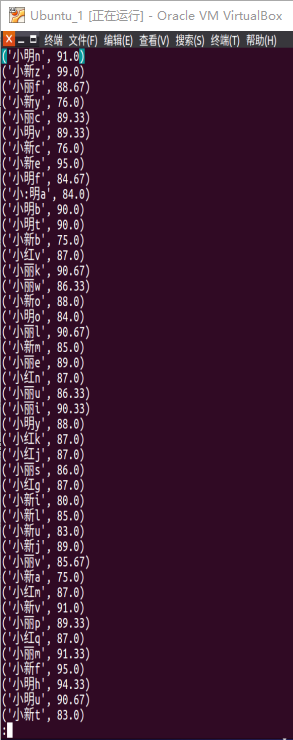 图5-3-3
图5-3-3
6、经验总结
通过这次大作业实践操作让我更加熟悉了RDD的基本操作,学会了如何加载数据创建RDD以及其转换操作,对spark的RDD操作有了一些的浅部认识。熟悉了Spark的RDD基本操作及键值对操作、使用RDD编程解决实际具体问题的方法。在实验的过程中我也学习到RDD叫做弹性分布式数据集,是Spark中最基本的数据抽象,同时也对linux系统的操作越发熟练,在实验中发现自己的不足,并且积极完善。在书写代码中,包含文件路径的、还有一些括号不能多写也不能少些,否则就会影响这个程序的运行。大数据处理对我们的生活工作是非常便利且重要的,能够应对生活中各种场景,我要熟悉的掌握这种处理数据的技术,提高自己的专业能力。必须有耐心,必须有耐心,必须有耐心。有耐心才能在一次次的失败中找到成功的路。还有搭环境时得细心,中英文符号得看清。















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









