







本文转自:http://blog.csdn.net/ayst123/article/details/43924151
Caffe Convolutional Layer 记录
先丛底层函数写起,依次讲解 Convolutional Layer 的 Forward 和 Backward 的函数
Forward_Cpu
cblas_dgemm
(/src/caffe/util/math_function.cpp)
cblas_dgemm 是 blas的一个函数,d 代表 double-precision (single-precision is s). ge代表相乘,mm代表矩阵和矩阵相乘(mv则是矩阵和向量相乘)。 下面给出具体使用方法,方便以后查询。
Declaration
SWIFT
func cblas_dgemm(_ Order: CBLAS_ORDER,
_ TransA: CBLAS_TRANSPOSE,
_ TransB: CBLAS_TRANSPOSE,
_ M: Int32,
_ N: Int32,
_ K: Int32,
_ alpha: Double,
_ A: UnsafePointer<Double>,
_ lda: Int32,
_ B: UnsafePointer<Double>,
_ ldb: Int32,
_ beta: Double,
_ C: UnsafeMutablePointer<Double>,
_ ldc: Int32)
OBJECTIVE-C
void cblas_dgemm ( const enum CBLAS_ORDER __ Order , const enum CBLAS_TRANSPOSE __ TransA , const enum CBLAS_TRANSPOSE __ TransB , const int __ M ,
const int __ N , const int __ K , const double __ alpha , const double *__ A , const int __ lda , const double *__ B ,
const int __ ldb , const double __ beta , double *__ C , const int __ ldc );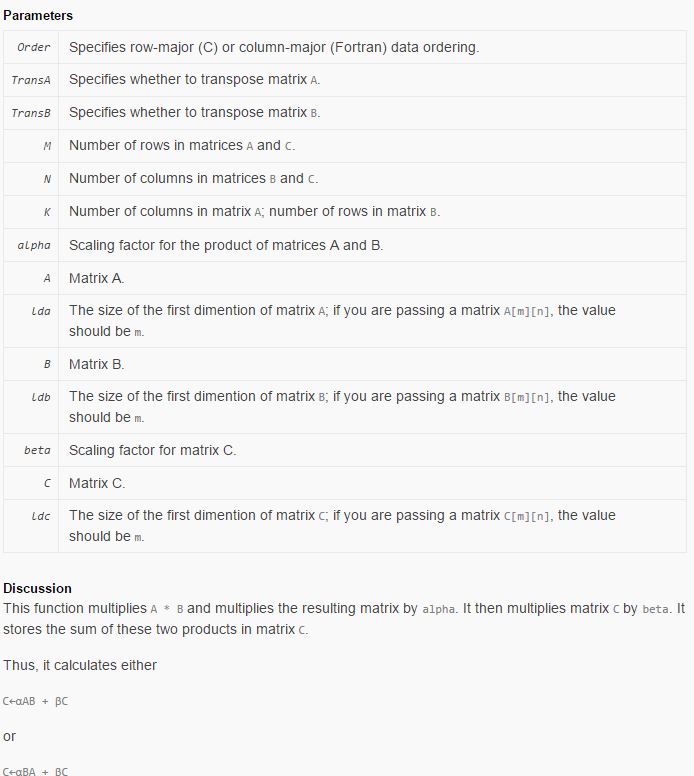
Explanation
实现
C←αAB+βC其中 A 是 M by K, B 是 K by N, C 是 M by N.
Caffe_cpu_gemm
(/src/caffe/util/math_function.cpp) 这个是caffe中上一个函数的接口,参数变少了,方便使用. 以后都使用这个函数代替 cblas_dgemm
template<>
void caffe_cpu_gemm<double>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const double alpha, const double* A, const double* B, const double beta,
double* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_dgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}Function: the same as the cblas_dgemm
forward_cpu_gemm
计算forward_pass
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_ / group_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}Explanation
1.第一部分先将 input 变成一维具有(channel, height, weight)形式的array。在conv_im2col_cpu里实现,
2.第二部分做卷积,实际上是将3D的卷积变成2D的矩阵相乘。下面这个例子详细说明这个过程
其中kernel_dim=channel_in∗kernel_width∗kernel_heightout_spatial=height_out∗width_out这样做的出发点就是把3D运算变成2D运算, 对于weight, 把每一个小的卷积块平展成一个array, 所有的小卷积块变成矩阵。对应的,input image也要变成一个2维矩阵。实际上,就是对每一个output上的一点, 拿到在原图中得到这点的对应kernel的那些点,并flat它们。
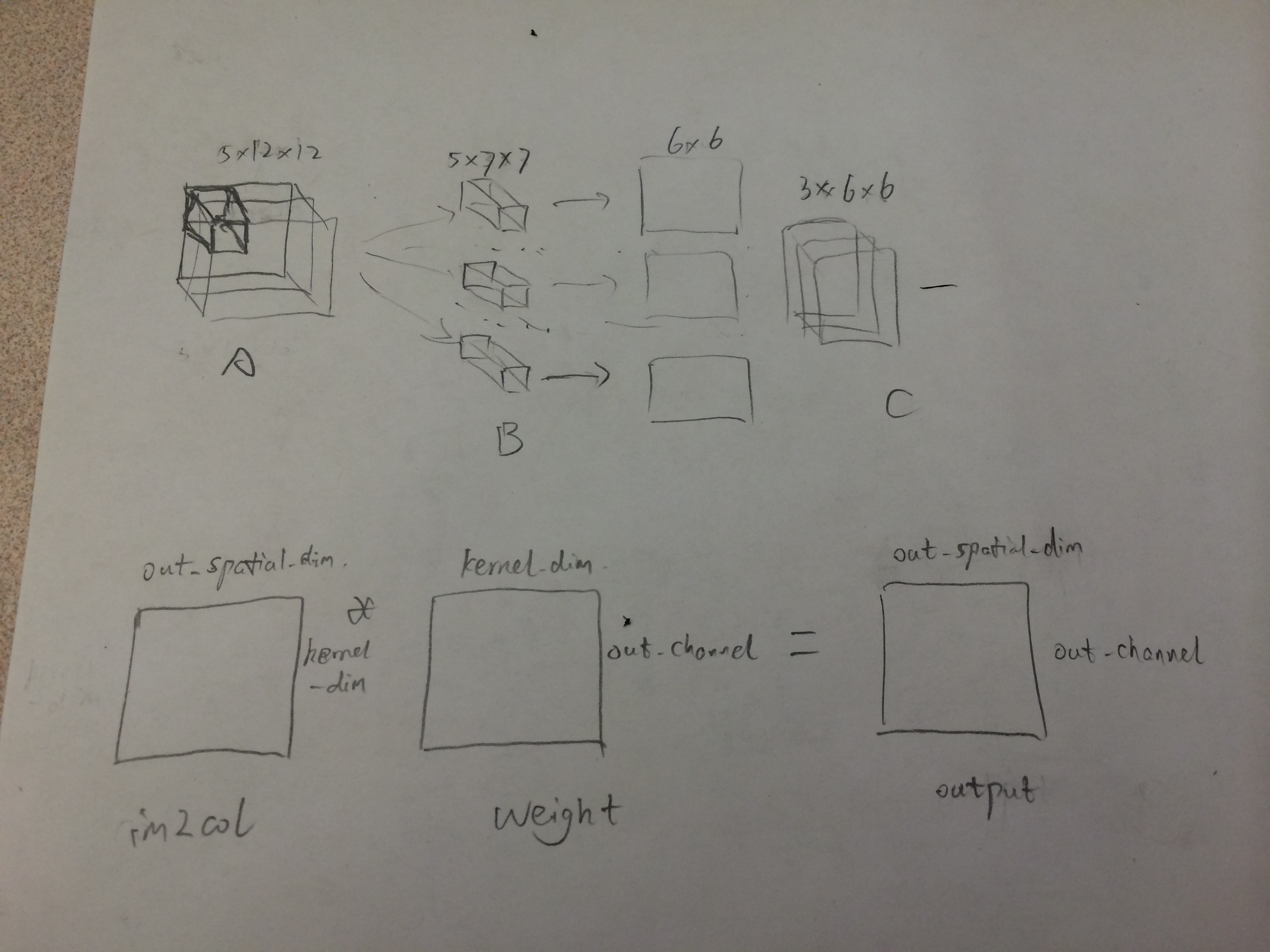
所以im2col_cpu的代码相对就很容易看懂了
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
Dtype* data_col) {
int height_col = (height + 2 * pad_h - kernel_h) / stride_h + 1;
int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
int channels_col = channels * kernel_h * kernel_w;
for (int c = 0; c < channels_col; ++c) {
int w_offset = c % kernel_w;
int h_offset = (c / kernel_w) % kernel_h;
int c_im = c / kernel_h / kernel_w;
for (int h = 0; h < height_col; ++h) {
for (int w = 0; w < width_col; ++w) {
int h_pad = h * stride_h - pad_h + h_offset;
int w_pad = w * stride_w - pad_w + w_offset;
if (h_pad >= 0 && h_pad < height && w_pad >= 0 && w_pad < width)
data_col[(c * height_col + h) * width_col + w] =
data_im[(c_im * height + h_pad) * width + w_pad];
else
data_col[(c * height_col + h) * width_col + w] = 0;
}
}
}
}forward_cpu_bias
这个函数就相对简单一些,把计算卷积中的bias加上。
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
height_out_ * width_out_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
}Forward_cpu
Forward_cpu所依赖的函数都看完了,Forward_cpu 函数也变得明了了。 对每一张图进行卷积计算,然后存储。 先计算weight, 再计算bias
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + bottom[i]->offset(n), weight,
top_data + top[i]->offset(n));
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + top[i]->offset(n), bias);
}
}
}
}Backward_Cpu
未完待续
** 转载或引用请注明出处, ayst123的专栏(http://blog.csdn.net/ayst123/article/details/43924151), 谢谢 !















 25
25

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









