






已有環境
服務器安裝信息:
1、Hbase:hbase-1.4.9
2、hodoop:hadoop-3.0.1
本地client信息:
1、eclipse
2、有一個空的springboot項目
首先在pom.xml引入Hbase-client相關信息
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0</version>
</dependency>
在引用後啟動項目會出現問題,提示 jdk.tools-1.6找不到,此時我們需要在Maven中運行
mvn install:install-file -DgroupId=jdk.tools -DartifactId=jdk.tools -Dpackaging=jar -Dversion=1.6 -Dfile=tools.jar -DgeneratePom=true
示例:
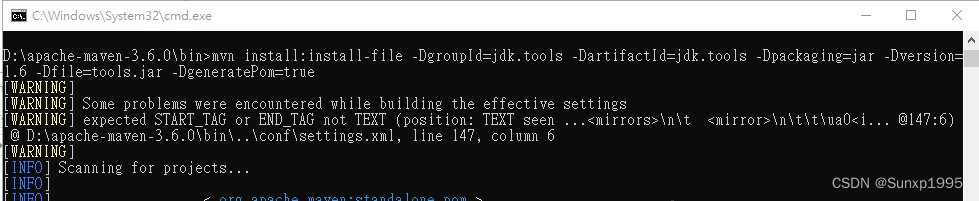
運行完畢後,在pom文件加下面的配置。
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
</dependency>
此時發現項目已能正常進行maven install。
接著我們開始在本地進行Hbase的連接
public static void main(String[] args) {
Configuration config = null;
Connection conn = null;
Table table = null;
// 创建配置
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "10.210.57.67");
config.set("hbase.zookeeper.property.clientPort", "2181");
// 16010
try {
// 创建连接
conn = ConnectionFactory.createConnection(config);
// 获取表
table = conn.getTable(TableName.valueOf("default:stu"));
// 查询指定rowkey的数据
HbaseUtils.queryRowKey(table);
// 略。。。
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (table != null) {
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
} /**
* 查询指定rowkey的数据
*/
public static void queryRowKey(Table table) {
try {
// get对象指定行键
Get get = new Get("10".getBytes(StandardCharsets.UTF_8));
Result result = table.get(get);
// System.out.printf("|%10s|%10s|%10s|%10s|\n", "row key", "family", "qualifier", "value");
// System.out.println("asdasd"+result);
output(result);
} catch (IOException e) {
e.printStackTrace();
}
}
private static void output(Result result) throws IOException {
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell cell = cellScanner.current();
byte[] rowArray = cell.getRowArray(); //本kv所属的行键的字节数组
byte[] familyArray = cell.getFamilyArray(); //列族名的字节数组
byte[] qualifierArray = cell.getQualifierArray(); //列名的字节数据
byte[] valueArray = cell.getValueArray(); // value的字节数组
System.out.printf("|%10s|%10s|%10s|%10s|\n",
new String(rowArray, cell.getRowOffset(), cell.getRowLength()),
new String(familyArray, cell.getFamilyOffset(), cell.getFamilyLength()),
new String(qualifierArray, cell.getQualifierOffset(), cell.getQualifierLength()),
new String(valueArray, cell.getValueOffset(), cell.getValueLength()));
}
}運行代碼發現
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
查找原因發現,是需要在本地有Hadoop的環境,去網上下載Hadoop
代碼中增加紅色代碼部分
public static void main(String[] args) {
Configuration config = null;
Connection conn = null;
Table table = null;
// 创建配置
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "10.210.57.67");
config.set("hbase.zookeeper.property.clientPort", "2181");
System.setProperty("hadoop.home.dir", "D:\\hadoop-3.0.1");
// 16010
try {
// 创建连接
conn = ConnectionFactory.createConnection(config);
// 获取表
table = conn.getTable(TableName.valueOf("default:stu"));
HbaseUtils.queryRowKey(table);} catch (IOException e) {
略。。。
完美,報錯解決。
再次啟動,發現程序運行至下面紅色部分時,一直在輸出DEBUG,卡住不再向下執行。
// get对象指定行键
Get get = new Get("10".getBytes(StandardCharsets.UTF_8));Result result = table.get(get);
此時發現我們在向RegionServer發起訪問時,我們一直使用的是hostname(zl-os-logstash02.novalocal)發起的訪問。
那麼為什麼我們會使用hostname發起訪問而不是使用IP呢?
當客戶端向Zookeeper發起訪問時,Zookeeper最終返回給我們meta 所在的Region Server的地址,此時客戶端項存儲meta元數據的Region Server 發起請求,獲取我們操作的Region Server(只是hostname),客戶端接收到之後會向Region Server請求數據,客戶端接收到的是Region Server的hostname,無法向Region Server 發起訪問。故我們需要在客戶端進行hosts配置,當我們訪問hostname時,客戶端可將hostname轉換為IP地址(此處也可使用DNS)。
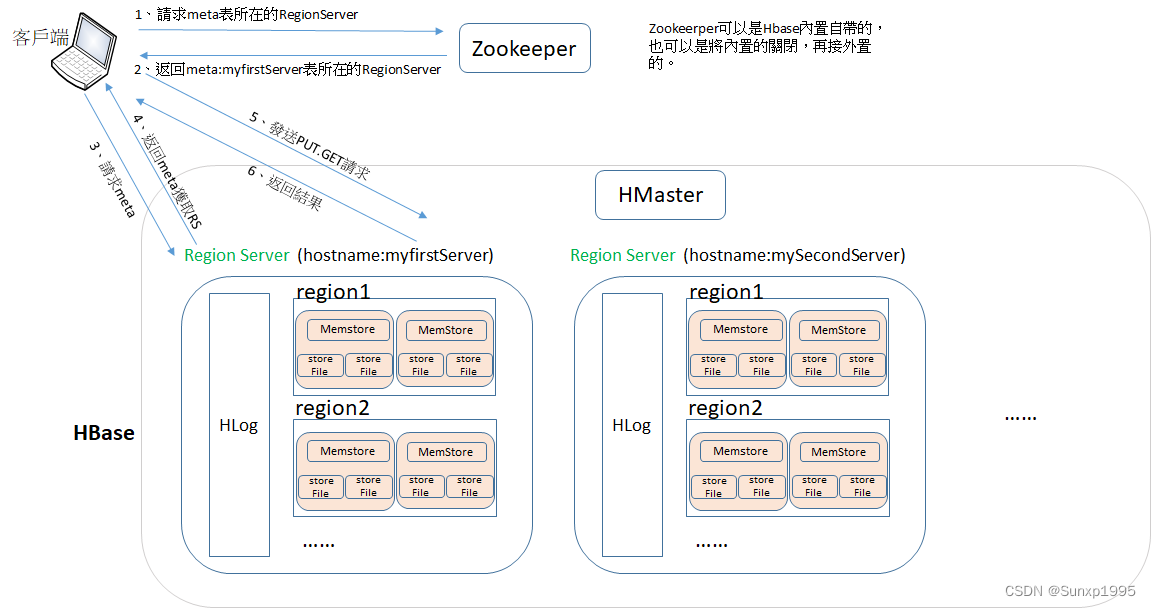
寫數據流程:
1、Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2、访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey, 查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3、与目标 Region Server 进行通讯;
4、将数据顺序写入(追加)到 WAL(Hlog);
5、将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6、向客户端发送 ack;
等达到 MemStore 的刷写时机后,将数据刷写到 HFile(fileStore)。
原文链接:https://blog.csdn.net/qq_33355858/article/details/124089200
獲取數據流程:
1、Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2、访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3、与目标 Region Server 进行通讯;
4、分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5、将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
6、将合并后的最终结果返回给客户端。
原文链接:https://blog.csdn.net/qq_33355858/article/details/124089200















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









