










HBase安装与配置
目录
注意:
1. jdk、hadoop、hbase压缩包自己使用winscp上传,版本不一样的话,在进行配置环境变量以及修改配置文件时,需要改成自己所使用的压缩包版本号
2.格式化文件系统时,如果失败想要重新格式化,需要删除namenode、datanode这两个文件夹里面的所有东西
3.如果实验过程中没出现错误,但在使用jps查看集群是否成功时发现进程没有显示完,可以使用stop-all.sh关闭集群后再次使用start-all.sh开启集群
4.可能在打开hbase shell进行使用的时候,会报错ERROR:Can’t get master address from Zookeeper;znode data == null,虽然启动hadoop和hbase进程成功了,但是实际上,再次输入jps查看进程,就会缺少Hmaster,此时打开终端,输入ifconfig查看你的ip,发现原来的ip地址已经改变或者缺失,此时也需要:stop-all.sh关闭集群后再次使用start-all.sh开启集群
5. 在实验为完成时尽量不要重启虚拟机
6.为了方便,做实验时可以一下把hadoop、jdk、hbase环境变量都配置了
安装JDK 1.8
步骤1. 创建工作路径
首先需要在终端中输入下列命令,在/usr目录下建立cx工作路径:
mkdir /usr/cx步骤2. 解压安装包
在/usr/software/目录下找到jdk-8u60-linux-x64.tar.gz安装包,通过下列命令将其解压到/usr/cx/目录下,执行如下命令:
tar -zxvf /usr/software/jdk-8u60-linux-x64.tar.gz -C /usr/cx命令执行后的输出内容如下所示:

步骤3. 配置环境变量
1. 通过下列命令使用vi编辑器打开 ~/.bashrc文件:
vi ~/.bashrc打开的~/.bashrc文件内容如下所示:

2. 在文件中写入下列内容:
export JAVA_HOME=/usr/cx/jdk1.8.0_60
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/jre/lib/tools.jar
编辑完成后保存文件并退出vi编辑器。

步骤4. 更新环境变量
执行如下命令,更新环境变量:
source ~/.bashrc步骤5. 验证JDK是否配置成功
通过下列命令验证JDK是否安装并配置成功:
java -version如果出现如下JDK版本信息,则说明安装配置成功:

主机名配置
步骤1. 编辑主机名
1. 通过下列命令使用vi编辑器编辑主机名配置文件:
vi /etc/sysconfig/network打开后的文件内容如下所示:
![]()
2. 在文件中进行内容更改,将HOSTNAME字段内容配置成master:
HOSTNAME=master编辑完成后保存文件并退出vi编辑器,更改后的文件内容如下所示:
![]()
3. 更改后的内容会在下次系统重启的时候生效,通过下列命令重新启动系统:
reboot步骤2. IP地址与主机名映射文件配置
1. 通过下列命令使用vi编辑器编辑hosts文件:
vi /etc/hosts打开后的文件内容如下所示:

2. 增加主机名与IP地址的映射关系:
127.0.0.1 master更改后的文件内容如下所示:

编辑完成后保存文件并退出vi编辑器。
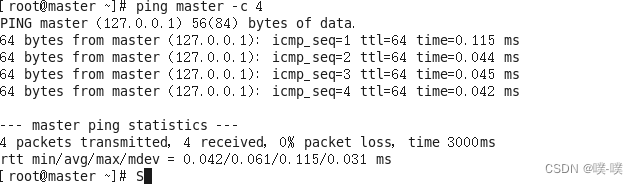
3. 通过下列命令检测主机名与IP映射是否配置成功:
ping master -c 4如果配置成功,则会显示如下结果:
SElinux安全配置
步骤1. 关闭SElinux
1. 通过下列命令使用vi编辑器打开SElinux配置文件:
vi /etc/selinux/config打开后的文件内容如下所示:

2. 在文件中进行内容更改,将SELINUX=permissive改写成SELINUX=disabled:
更改后的文件内容如下所示:

编辑完成后保存文件并退出vi编辑器。
步骤4. SElinux配置强制生效
更改后的内容会在下次系统重启的时候生效,为了操作便捷性,使用下列命令使更改即时生效,而不需要重新启动系统:
setenforce 0配置SSH免密码登录
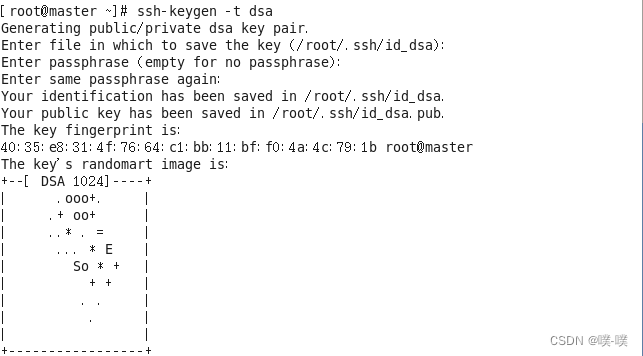
步骤1. 生成秘钥
1. 输入下面的命令,生成本机密钥文件:
ssh-keygen -t dsa按下四次回车,默认会将秘钥文件生成到~/.ssh/目录下:
通过下列命令查看~/.ssh目录下的文件:
ls ~/.ssh可以看到在~/.ssh目录下已经生成了id_dsa.pub(本机的公钥)和id_dsa(本机的私钥)文件:
![]()
步骤2. 秘钥分发
输入命令如下:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys上述命令运行完成后再次查看~/.ssh目录下的文件,可以看到已经创建了authorized_keys文件:
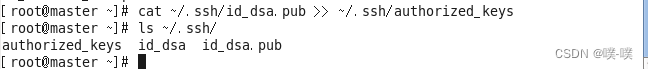
步骤3. 验证免密码登录是否配置成功
使用下列命令通过设置的主机名进行连接,可以验证免密码登录是否配置成功:
ssh master第一次登录的时候,会询问是否继续连接,输入yes即可进入

连接成功后,我们需要通过下列命令退出连接:
exit命令运行后显示的内容如下所示:

安装配置Hadoop
步骤1. 解压安装文件
通过下列命令解压Hadoop安装文件,将文件解压到/usr/cx目录下:
tar -zxvf /usr/software/hadoop-2.7.1.tar.gz -C /usr/cx命令执行后的输出内容如下所示:
步骤2. 配置Hadoop环境变量
1. 通过下列命令使用vi编辑器编辑~/.bashrc文件:
vi ~/.bashrc打开后的文件内容如下所示:

2. 在~/.bashrc文件中增加以下内容:
export HADOOP_HOME=/usr/cx/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$PATH
export PATH=$PATH:$HADOOP_HOME/sbin:$PATH编辑完成后保存文件并退出vi编辑器。
3. 执行如下命令,更新环境变量:
source ~/.bashrc4. 通过下列命令验证Hadoop环境变量是否配置成功:
hadoop如果出现如下提示信息,则说明Hadoop安装配置成功:

步骤3. 编辑Hadoop配置文件
1. 使用vi命令打开hadoop-env.sh配置文件进行编辑:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/hadoop-env.sh打开后的文件内容如下所示:
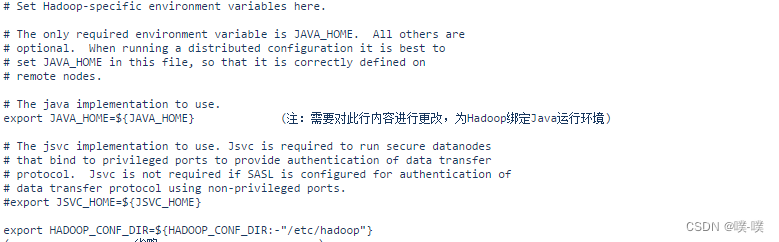
在文件中进行下列内容更改,将JAVA_HOME对应的值改成实际的JDK安装目录:
export JAVA_HOME=/usr/cx/jdk1.8.0_60编辑完成后保存文件并退出vi编辑器。
2. 使用vi命令打开core-site.xml配置文件进行编辑:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/core-site.xml打开后的文件内容如下所示:
在文件中<configuration>和</configuration>之间增加下列内容:
/*设置默认的HDFS访问路径*/
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
/*缓冲区大小:io.file.buffer.size默认是4KB*/
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
/*临时文件夹路径设置*/
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/tmp</value>
</property>
/*设置使用hduser用户可以代理所有主机用户进行任务提交*/
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
/*设置使用hduser用户可以代理所有组用户进行任务提交*/
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>编辑完成后保存文件并退出vi编辑器。
3. 使用vi命令打开yarn-site.xml文件进行配置:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/yarn-site.xml打开后的文件内容如下所示:

在文件中<configuration>和</configuration>之间增加下列内容:
/*设置NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序*/
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
/*设置客户端与ResourceManager的通信地址*/
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
/*设置ApplicationMaster调度器与ResourceManager的通信地址*/
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
/*设置NodeManager与ResourceManager的通信地址*/
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
/*设置管理员与ResourceManager的通信地址*/
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
/* ResourceManager的Web地址,监控资源调度*/
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>编辑完成后保存文件并退出vi编辑器。
4. 使用下列命令复制mapred-site.xml.template文件并重命名为mapred-site.xml:
cp /usr/cx/hadoop-2.7.1/etc/hadoop/mapred-site.xml.template /usr/cx/hadoop-2.7.1/etc/hadoop/mapred-site.xml5. 使用vi命令打开mapred-site.xml文件进行配置:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/mapred-site.xml打开后的文件内容如下所示:
在文件中<configuration>和</configuration>之间增加下列内容:
/*Hadoop对MapReduce运行框架一共提供了3种实现,在mapred-site.xml中通过"mapreduce.framework.name"这个属性来设置为"classic"、"yarn"或者"local"*/
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
/*MapReduce JobHistory Server地址*/
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
/*MapReduce JobHistory Server Web UI访问地址*/
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>编辑完成后保存文件并退出vi编辑器。
6. 执行以下命令创建Hadoop的数据存储目录namenode和datanode:
mkdir -p /hdfs/namenodemkdir -p /hdfs/datanode7. 使用vi命令打开hdfs-site.xml文件进行配置:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/hdfs-site.xml打开后的文件内容如下所示:
在文件中<configuration>和</configuration>之间增加下列内容:
/*配置SecondaryNameNode地址*/
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
/*配置NameNode的数据存储目录,需要与上文创建的目录相对应*/
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hdfs/namenode</value>
</property>
/*配置DataNode的数据存储目录,需要与上文创建的目录相对应*/
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hdfs/datanode</value>
</property>
/*配置数据块副本数*/
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
/*将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LIST FILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode保存的*/
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>编辑完成后保存文件并退出vi编辑器。
8. 使用vi命令打开slaves文件进行配置:
vi /usr/cx/hadoop-2.7.1/etc/hadoop/slaves打开后的文件内容如下所示:
![]()
将文件中的内容更改为下列内容:
![]()
编辑完成后保存文件并退出vi编辑器。
步骤4. 格式化HDFS
通过下列命令格式化HDFS文件系统:
hadoop namenode -format命令运行后的部分显示内容如下所示:
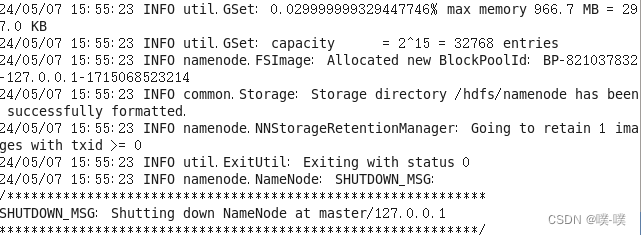
Hadoop运行及测试
步骤1. 启动Hadoop
1. 通过下列命令启动Hadoop:
start-all.sh命令运行后的输出内容如下所示:

2. 通过下列命令,查看相应的JVM进程确定Hadoop是否配置及启动成功:
jps当有以下进程启动时,则说明Hadoop已经成功启动,如果某个进程没有启动,则需要查看日志文件确定错误发生的原因:

步骤2. Web页面测试
1. 当Hadoop成功启动后,我们打开浏览器,输入网址http://master:8088便可以访问任务调度的Web管理页面:
2. 当Hadoop成功启动后,我们打开浏览器,输入网址http://master:50070便可以访问HDFS的Web管理页面:
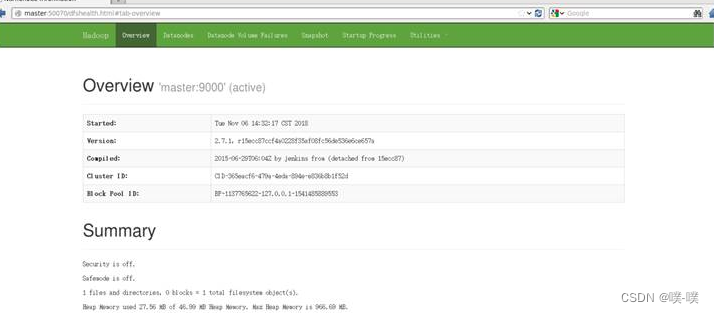
安装配置HBase
可以在Apache镜像网站上下载稳定版本的HBase安装包,下载地址为http://mirror.bit.edu.cn/apache/。
步骤1. HBase环境配置
1. 通过下面的命令解压缩HBase安装包:
tar -zxvf /usr/software/hbase-1.0.1.1-bin.tar.gz -C /usr/cx/命令运行后的返回结果如下所示:
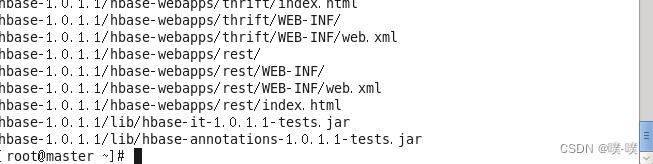
2. 通过下列命令使用vi编辑器编辑~/.bashrc文件:
vi ~/.bashrc打开后的文件内容如下所示:

3. 在~/.bashrc文件中增加HBase配置路径信息:
export HBASE_HOME=/usr/cx/hbase-1.0.1.1
export PATH=$HBASE_HOME/bin:$PATH编辑完成后保存文件并退出vi编辑器。
4. 执行如下命令,更新环境变量:
source ~/.bashrc5. 通过下列命令验证HBase环境变量是否配置成功:
hbase如果出现如下提示信息,则说明HBase环境配置成功:

步骤2. HBase配置及启动
1. 通过下列命令使用vi编辑器编辑HBase配置文件hbase-env.sh:
vi /usr/cx/hbase-1.0.1.1/conf/hbase-env.sh打开后的文件内容如下所示:

修改配置文件hbase-env.sh,在文件中增加下列内容:
export JAVA_HOME=/usr/cx/jdk1.8.0_60
export HBASE_MANAGES_ZK=true注:设置HBASE_MANAGES_ZK=true表示ZooKeeper交给HBase管理,使用HBase自带的ZooKeeper,启动HBase时会自动启动hbase-site.xml里的hbase.zookeeper.quorum属性中的所有zookeeper实例。
2. 通过下列命令使用vi编辑器编辑HBase配置文件hbase-site.xml:
vi /usr/cx/hbase-1.0.1.1/conf/hbase-site.xml打开后的文件内容如下所示:
在配置文件hbase-site.xml的<configuration></configution>之间添加如下所示的配置信息:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/cx/hbase-1.0.1.1/zookeeper</value>
</property>通过hbase.rootdir配置RegionServer的共享目录,用来持久化HBase。/hbase表示HBase在HDFS中占用的实际存储目录,HDFS的NameNode运行在主机名为master的9000端口,因此需要设置为hdfs://master:9000/
通过hbase.cluster.distributed指定HBase的运行模式。为false表示单机模式运行(此时HBase和ZooKeeper会运行在同一个JVM中),为true表示以分布式模式运行,默认值是false。
通过hbase.zookeeper.property.dataDir这个参数可以设置ZooKeeper快照的存储位置。默认值是/tmp,在操作重启的时候该目录会被清空,应该设置默认值到其它目录,我们这里设置值为/usr/cx/hbase-1.0.1.1/zookeeper (这个路径需要运行HBase的用户拥有读写操作权限)。
3. 配置文件修改完毕后,我们便可以运行如下脚本启动HBase:
start-hbase.sh命令运行后的返回结果如下所示:

4. 通过下面的命令查看HBase是否配置以及启动成功:
jps如果HBase配置以及启动成功,则会出现下面3个与HBase相关的进程:

5. HBase启动成功后,通过在浏览器中访问HMater的16010端口便可以查看HBase的Web UI界面,访问网址为http://master:16010,图 6.7 HBase Web UI中的属性部分列出了集群的一些关键信息,这些信息包括HBase的版本、ZooKeeper集群的主机列表、HBase根目录等。
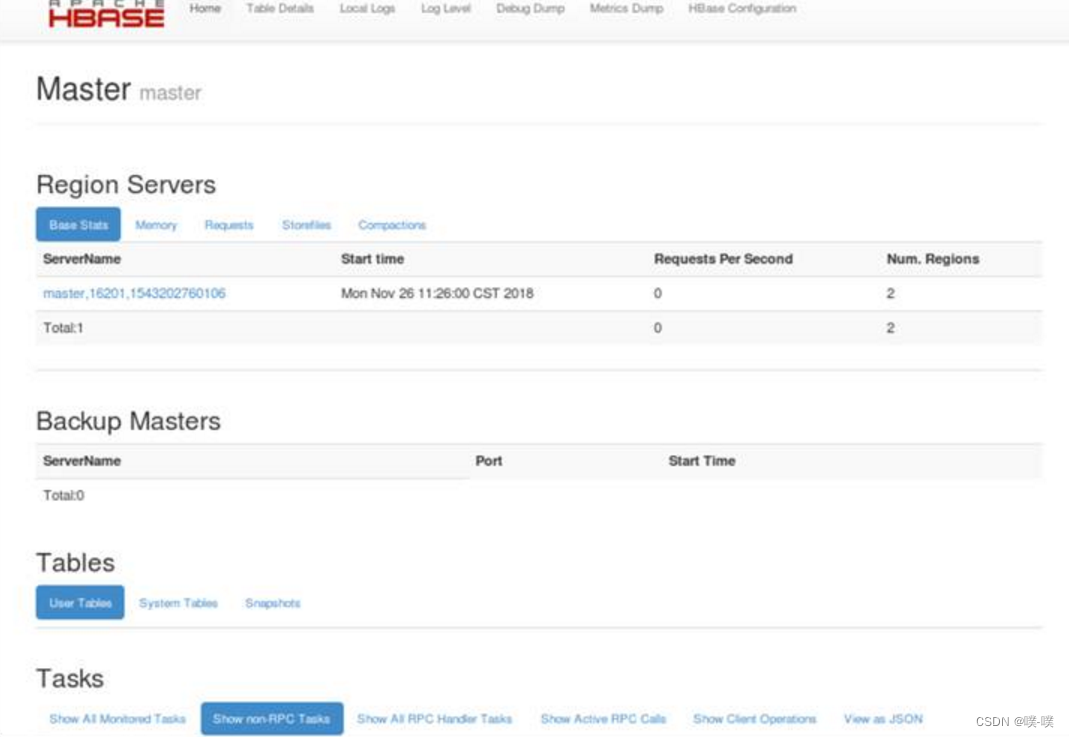
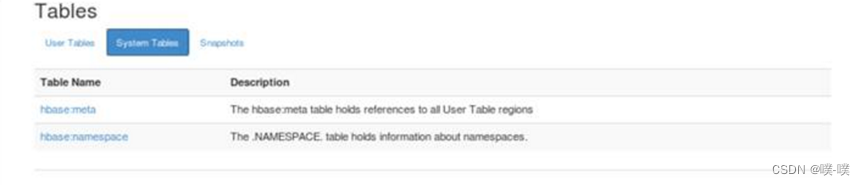
在Tables标签下列举出了目前HBase上有哪些表及表的一些基本信息,其中hbase:meta和hbase:namespace表是永远存在且成功加载的,如果这两张表加载不成功,那么集群虽然已经启动,但是却无法正常读写数据。
Hbase基本操作
1. HBase启动后,可以通过命令行工具连接HBase,从而对HBase中的表进行基本操作,在终端模拟器下通过下面的命令进入HBase命令行操作界面:
hbase shell 命令运行后的返回结果如下所示:
2. 通过下面的命令可以创建一个名称为test的数据表,其中数据表下有一个cf列族:
create 'test','cf'命令运行后的返回结果如下所示:

3. 通过下面的命令可以向test数据表中新增一个列字段a,并插入数据,其中插入的行号为row1,插入的数据值为value1:
put 'test', 'row1', 'cf:a', 'value1'命令运行后的返回结果如下所示:

4. 通过下面的命令可以查看表数据(HBase中的列是由列族前缀和列的名字组成的,以冒号分隔):
scan 'test'命令运行后的返回结果如下所示:

5. 通过下面的命令可以获取表中指定行的数据:
get 'test','row1'命令运行后的返回结果如下所示:

6. 通过下面的命令可以下线表(此时表将无法被使用):
disable 'test'命令运行后的返回结果如下所示:
![]()
7. 通过下面的命令可以删除表(如果希望删除表,必须先将表下线):
drop 'test'命令运行后的返回结果如下所示:

8. 通过下面的命令可以退出HBase Shell命令行界面:
exit命令运行后的返回结果如下所示:
![]()
9. 通过下面的命令可以停止HBase集群:
stop-hbase.sh命令运行后的返回结果如下所示:

至此,hbase安装成功!!
















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











