






-
Mysqladmin常用选项,设置密码的三种方式
1.1 mysqladmin常用选项
语法:mysqladmin [option] command [command option] command ......
常用选项:ping status password refresh刷新授权 shutdown 等
例如:mysqladmin -u root -p'Xxhf@2022' ping mysqladmin -u用户名 -p旧密码 password 新密码
1.2 为用户设置密码三种方式
SET PASSWORD FOR “USER@’HOST’=‘XXXXXX’; %匹配任意长度的任意字符
update mysql.user SET password=PASSWORD(‘password’) WHERE clause; (需要重读授权表)
mysqladmin -u用户名 -p旧密码 password 新密码
-
Mysql的数据类型
字符:变长字符 VARCHAR(#),VARBINARY(#) BINARY是区分大小写的
定长字符型最长长度为255 变长为65535
定长字符 CHAR(#),BINARY(#) ‘zhangsan’ ZHANGSAN
内建类型 ENUM(枚举,多个条件选一个),SET(集合,多个条件选可以选多个) mysql独有的数据类型
对象(也是字符) TEXT(65535), TINYTEXT, MEDIUMTEXT(1600万), LOGTEXT(40亿), (文本大对象类型)
BLOB,TINYBLOB,MEDIUMBLOB,LONGBLOB (二进制大对象类型)<img>
字符型插入或更新数据必须接引号(单引号或双引号都可以)

MySQL :: MySQL 8.0 Reference Manual :: 13.3.2 The CHAR and VARCHAR Types
数值:
精确数值: 1:整形 INT (包含正数和负数)
TINYINT SMALLINT MEDIUMINT INT BIGINT
2^8(1字节) 2^16(2字节) 2^24(3字节) 2^32(4字节) 2^64(8字节)
2:十进制 DECIMAL(mysql独有类型) decimal(8,3) 总长8位,精确小数点后三位 例如20000.535 200000.10
近似数值: 1:单精度:FLOAT 精确到小数点后一位
2:双精度:DOUBLE 精确到小数点后两位
字符类型修饰符:
NOT NULL 非空约束
NULL
DEFAULT ‘’指定默认值 (此两试用任何)
CHARACTER SET ‘’使用的字符集,或者使用CHARSET ‘’
COLLATION:使用的排序规则
查看所有字符集
mysql > SHOW CHARACTER SET; show charset;
查看默认排序规则
mysql > SHOW COLLATION;
整形数据修饰符
NOT NULL 非空约束
NULL
DEFAULT NUMBER 默认数值,定义之后不要写主键唯一键
PRIMARY KEY主键 | UNIQUE KEY唯一键
UNSIGNED(无符号修饰,仅正数) (mysql中数值不能加引号,字符型要加引号,支持三种引号,’’,””,``.支持AUTO_INCREMENT(自动增长)
此两修饰数值属于mysql独有数据类型
内建类型(枚举和集合)修饰符
NULL
NOT NULL
DEFAULT gender enum(‘M’,’F’) default ‘M’
日期时间型:(也需要加上引号)
日期:DATE 年-月-日
时间:TIME 时-分-秒
日期和时间:DATETIME
时间戳:TIMESTAMP
年份:YEAR(2),YEAR(4) 18 2018
-
跳过密码破解密码进行免密登录
跳过密码实现破解密码免密登录 /etc/my.cnf
//只能在本机操作,进行密码破解 ,ss -tnl端口隐藏了,直接登录就ok
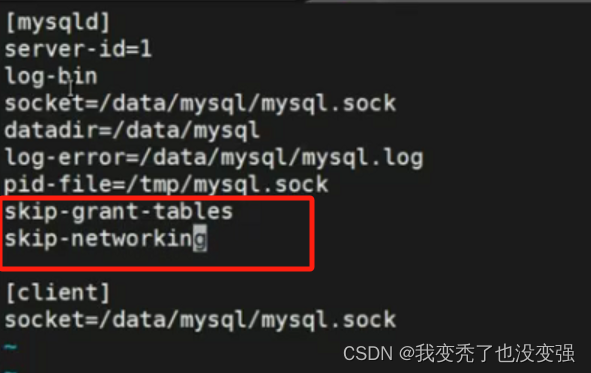
![]()
//查看账户

//改密码
先mysql进入数据库,将密码置为空,正在将上述添加的两行注释,正常进入数据库 改密码
-
mysql数据库的文件类型
数据文件(包括索引)日志文件(二进制日志、错误日志、查询日志、慢查询日志、中继日志)

-
Mysql索引的作用和类型
索引管理
索引:
按照特定数据结构存储的数据
应创建在经常用作查询条件的字段上
实现的功能
没有索引:表扫描(消耗大量资源)
有了索引:将单个字段抽取出来,进行排序,将索引装载进入内存。
索引的作用
1:将经常用于查询的某些字段定义索引后,数据库利用索引定位技术,能够大大加快查询速率。
特别是在当表特别大的时候,或者涉及到多表查询的时候,利用索引可以使查询加快成千倍。
2:极大的降低I/O成本(将随机IO转为顺序IO),降低数据库的排序成本。
3:使用分组、排序时,能大大减少分组和排序时间
索引的缺点:占用额外空间,影响插入速度
索引类型:
myisam .myi存储索引 .myd存储文件 数据和索引不同文件
inodb .idb 数据和索引同一文件
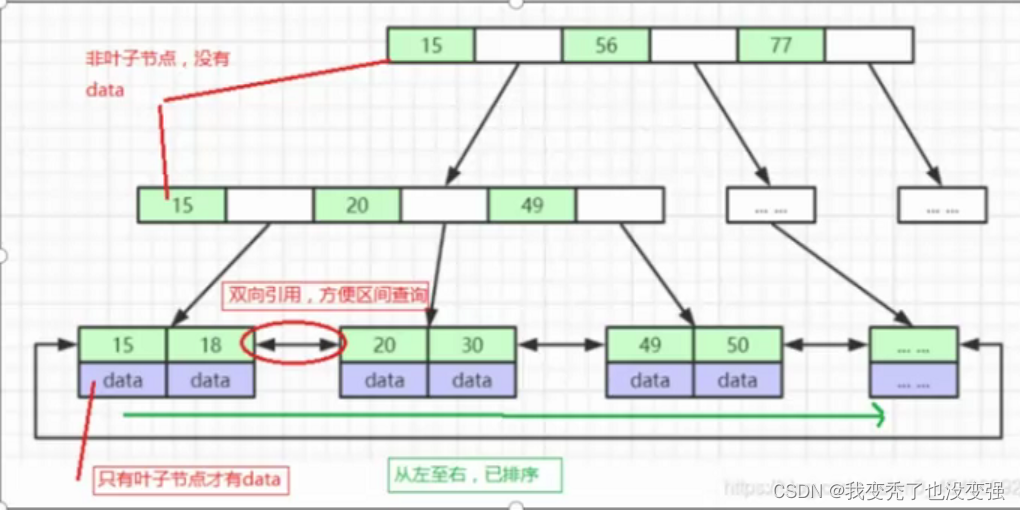
聚集索引:数据和索引存储在一起 innodb——用于主键
非聚集索引:指针导向 myisam 二叉树红黑树
主键索引、辅助索引82
稠密索引(主键)、稀疏索引
B+ TREE索引 HASH索引 R TREE索引
参考链接:
二叉树:https://www.cs.usfca.edu/~galles/visualization/BST.html
红黑树:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
B树:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+树:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
B树和B+树的区别
B树每次发起io基于根节点,基于叶子节点的
都是通过索引检测数据的一种方式,
B树的节点上都存储了索引和数据,B+树都存在叶子节点,非叶子节点村索引
简单索引和组合索引
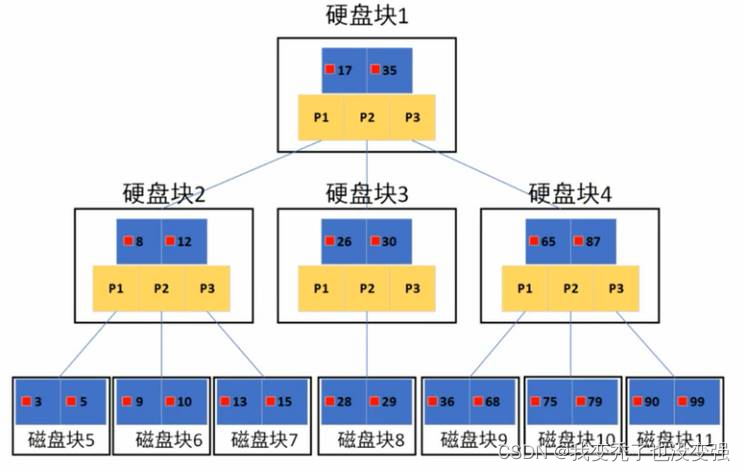
索引组织方式
左前缀索引:例如like ‘abc%’
模糊匹配
Select * from testlog where name like 'wang65%';
MySQL在索引时,采用左前缀索引。例如字符型255长度,会抽取最左侧的一部分字符来作为索引。
-
Mysql的12大组件
-
Select语句执行流程和优先级
SELECT
查询
SELECT语句的执行过程
过程详解:
from clause ---> where clause ---> group by ---> having clause --->order by ---> select --->limit
操作方法
select col1,col2... from clause--->where clause--->group by--->having--->order by--->limit
SELECT语句默认查询后会被缓存,方便下次查询
SQL_CACHE:显示指定存储查询结果于缓存之中。
查询sql缓存大小 show global variables like ‘query%’;
查询sql缓存开没开 show global variables like ‘cache%’;
-
Mysql体系结构图
-
mysql体系结构图
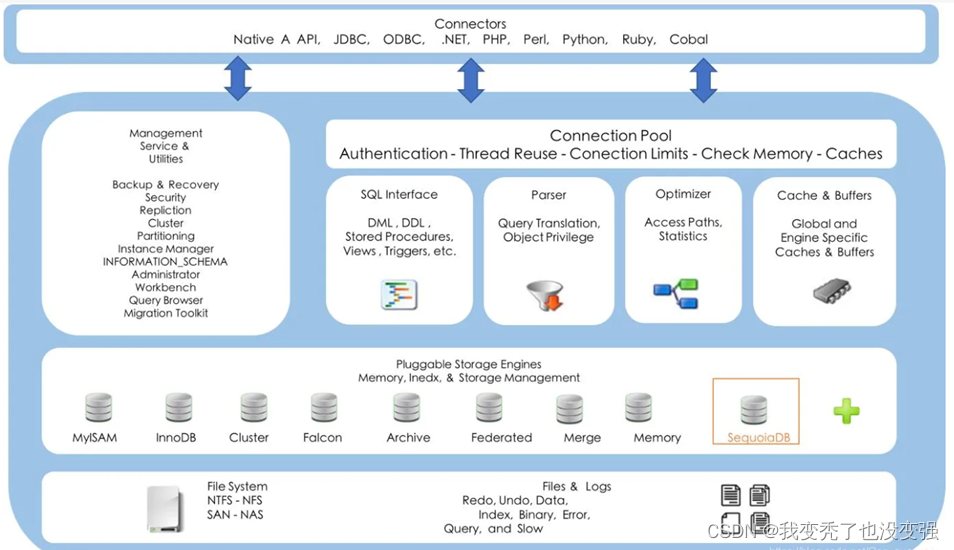
默认单个最大实例并发151,可以调大到1024,支持复用io结构
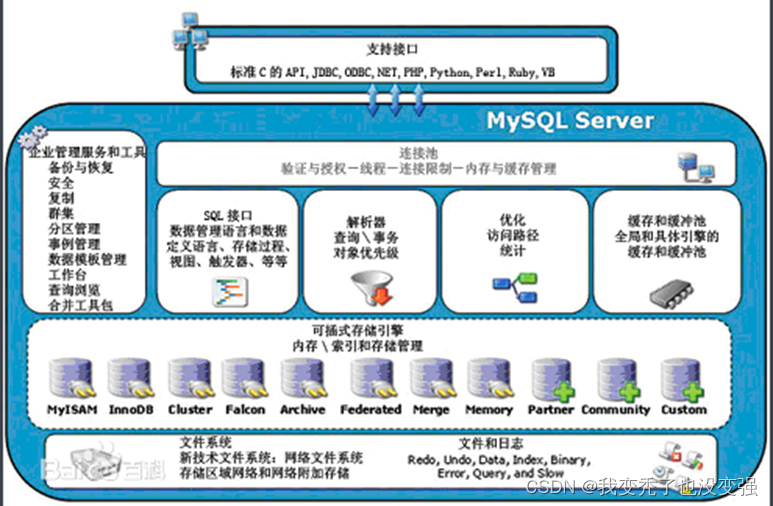
-
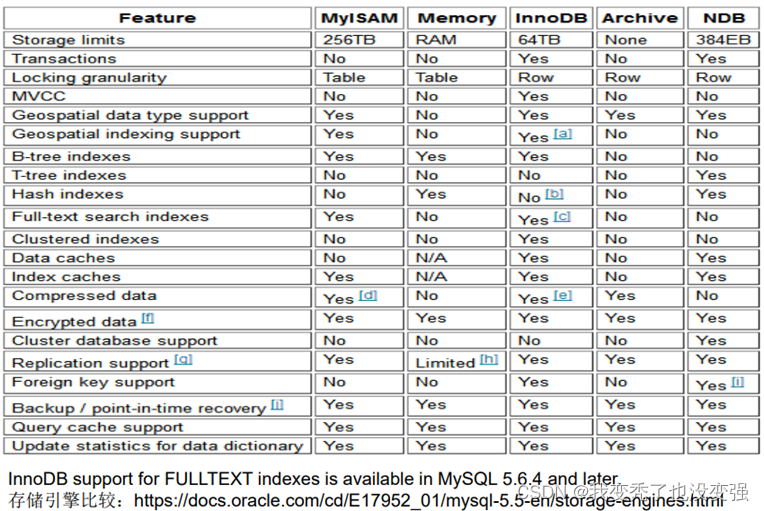
Mysql存储引擎,myisam和innodb的区别
不同的存储技术将数据存储在磁盘上,每一种引擎采用不同的技术、存储机制、索引技巧、锁定水平,最终提供不同的功能和能力。
概念:5.1之前默认存储引擎是MyISAM,5.1之后默认是INNODB(支持事务处理)
查看当前默认存储引擎:show engines;
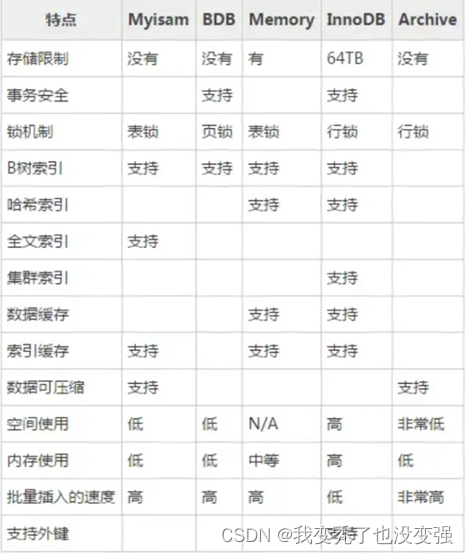
-
MyISAM存储引擎的特点:
①:不支持事务
②:表级别锁
③:读写相互阻塞,写入不能读,读时不能写
④:只缓存索引
⑤:不支持外键约束
⑥:读取速度较快,占用资源较少
⑦:不支持MVCC和高并发
⑧:崩溃恢复性较差
⑨:MySQL5.5之前的版本默认的存储引擎。
MyISAM存储引擎适用的场景:只读、表较小
MyISAM存储引擎文件:.frm--->表格式定义 .MYD--->数据库文件 .MYI--->索引文件
-
InnoDB引擎特点
行级锁
支持事务,适合处理大量短期事务
读写阻塞与事务隔离级别相关
可缓存数据和索引
支持聚簇索引
崩溃恢复性更好
支持MVCC高并发
从MySQL5.5后支持全文索引
从MySQL5.5.5开始为默认的数据库引擎
-
Mysql的事务,隔离级别,属性
-
事务
-
概念
事务Transactions:一组原子性的SQL语句,或一个独立工作单元
事务是一种机制,一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起将系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行。
事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元。默认情况下一条sql语句就是一个事务
事务适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等等。通过事务的完整性以保证数据的一致性、完整性。
事务日志:记录事务信息,实现undo,redo等故障恢复功能,
myisam不支持,只有innodb支持
只针对DML语句
Insert xxxxxx
Update xxxxxx
Delete xxxxxx
-
事务的四个属性(ACID)
原子性 atomicity 整个事务中的所有操作要么全部成功执行,要么全部失败后回滚
一致性 consistency 数据库总是从一个一致性状态转换为另一个一致性状态
隔离性 isolation 一个事务所做出的操作在提交之前,是不能为其它事务所见;隔离有多种隔离级别,实现并发
持久性 durability 一旦事务提交,其所做的修改会永久保存于数据库中
默认单条SQL语句即为一个单独的事务,会实现自动提交事务,若实现非自动提交,输入set autocommit=0;即可
-
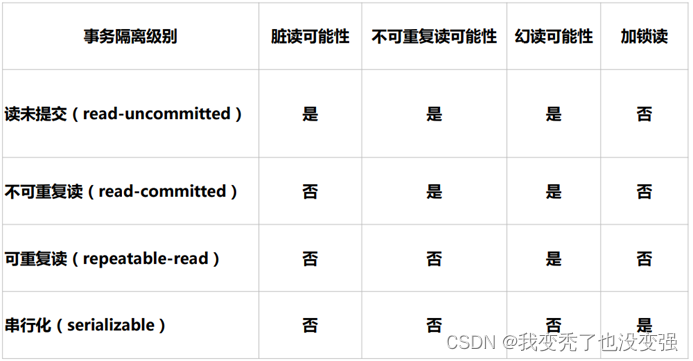
事务隔离级别:
从上至下更加严格
READ UNCOMMITTED 可读取到未提交数据,产生脏读
READ COMMITTED 不可重复读,可读取到提交数据,但未提交数据不可读,产生不可重复读,即可读取到多个提交数据,导致每次读取数据不一致 是orsql的默认级别
REPEATABLE READ 可重复读,多次读取数据都一致,产生幻读,即读取过程中,即使有其它提交的事务修改数据,仍只能读取到未修改前的旧数据。此为MySQL默认设置 是mysql的默认级别
SERIALIZABLE 可串行化,未提交的读事务阻塞修改事务,或者未提交的修改事务阻塞读事务。导致并发性能差
MVCC: 多版本并发控制,和事务级别相关
-
常见服务器的相关变量 5-6
查看mysql数据库内置的相关变量和参数
分为全局的参数配置和当前会话生效的参数
mysql> SHOW GLOBAL VARIABLES; (有些参数支持立即修改,立即生效;有些参数需要修改主配置文件,重启服务生效。)
mysql> SHOW [SESSION] VARIABLES;
mysql> SELECT @@VARIABLES; //查看
2:修改服务器变量的值:
mysql> help SET //查看
修改全局变量:
仅对修改后新创建的会话有效;对已经建立的会话无效
mysql> SET GLOBAL system_var_name=value;
mysql> SET @@global.system_var_name=value;
修改会话变量:
mysql> SET [SESSION] system_var_name=value;
mysql> SET @@[session.]system_var_name=value
-
Mysql的日志分类和用途
事务日志 transaction log
错误日志 error log
通用日志 general log 默认关闭
慢查询日志 slow query log
二进制日志 binary log 增删改操作,备份时适用,有重放功能
中继日志 reley log 配合二进制做一个主从复制
-
事务日志的优化 0 1 2代表的意义和优缺点
-
事务日志:transaction log
事务型存储引擎自行管理和使用,建议和数据文件分开存放
redo log 重做日志
undo log 回滚
1.1 Innodb事务日志相关配置:
show variables like '%innodb_log%';
innodb_log_file_size 5242880 每个日志文件大小
innodb_log_files_in_group 2 日志组成员个数
innodb_log_group_home_dir ./ 事务文件路径
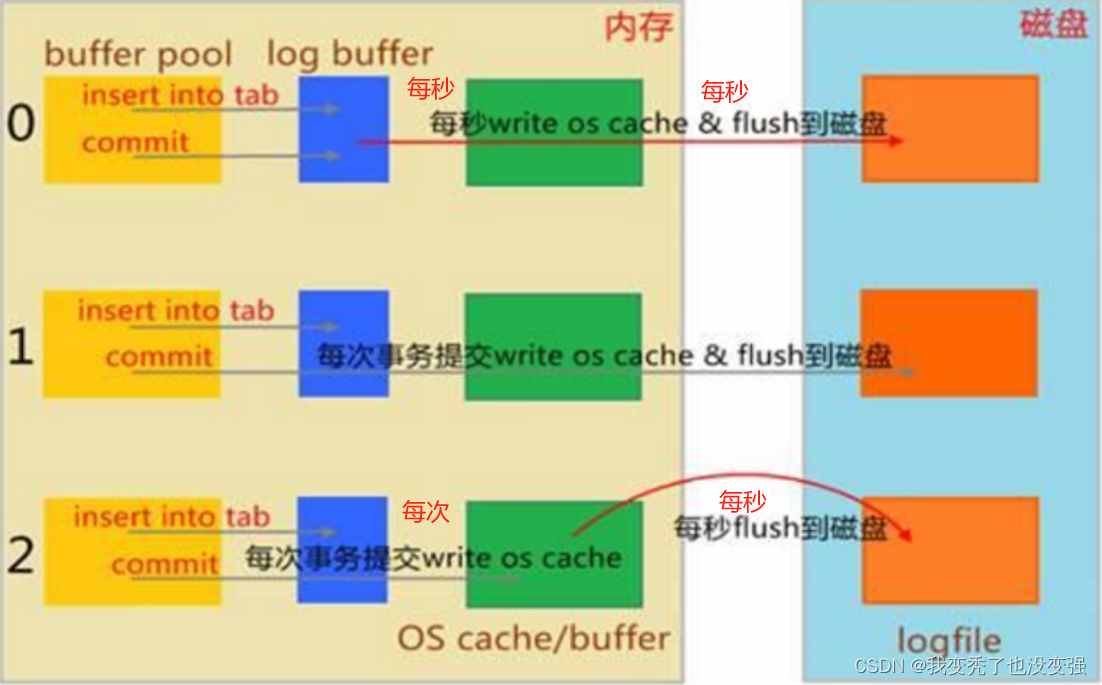
innodb_flush_log_at_trx_commit 默认为1
innodb_flush_log_at_trx_commit 见下图
说明:设置为1,同时sync_binlog = 1表示最高级别的容错
innodb_use_global_flush_log_at_trx_commit的值确定是否可以使用SET语句重置此变量
1默认情况下,日志缓冲区将写入日志文件,并在每次事务后执行刷新到磁盘。这是完全遵守ACID特性 mysql默认采用的策略——最安全
0提交时没有任何操作; 而是每秒(由innodb_flush_log_at_timeout控制,默认为1秒)执行一次日志缓冲区写入和刷新。 这样可以提供更好的性能,但服务器崩溃可以清除最后一秒的事务——最快
2每次提交后都会写入日志缓冲区,但每秒都会进行一次刷新。 性能比0略好一些,但操作系统或停电可能导致最后一秒的交易丢失
3模拟MariaDB 5.5组提交(每组提交3个同步),此项MariaDB 10.0支持
事务日志的优化
-
二进制日志的功能 ,行 语句
二进制日志:
记录导致数据改变或潜在导致数据改变的SQL语句记录已提交的日志,不依赖于存储引擎类型
功能:通过“重放”日志文件中的事件来生成数据副本
注意:建议二进制日志和数据文件分开存放
中继日志:relay log
主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取的事件
5.2 二进制日志记录格式(三种格式)
5.2.1 基于“语句”记录:statement,记录语句,mariadb默认模式
5.2.2 基于“行”记录:row,记录数据,日志量较大,恢复时控制精准 mysql8.0
5.2.3 混合模式:mixed, 让系统自行判定该基于哪种方式进行 mysql5.7
格式配置 show variables like 'binlog_format';
-
备份和恢复,那一大块全背 备份工具有哪些(不用具体说)
-
为什么要备份?
灾难恢复:硬件故障、软件故障、自然灾害、黑客攻击、误操作测试等数据丢失场景
备份注意要点
能容忍最多丢失多少数据
恢复数据需要在多长时间内完成
需要恢复哪些数据
还原要点
做还原测试,用于测试备份的可用性
还原演练
-
备份类型:
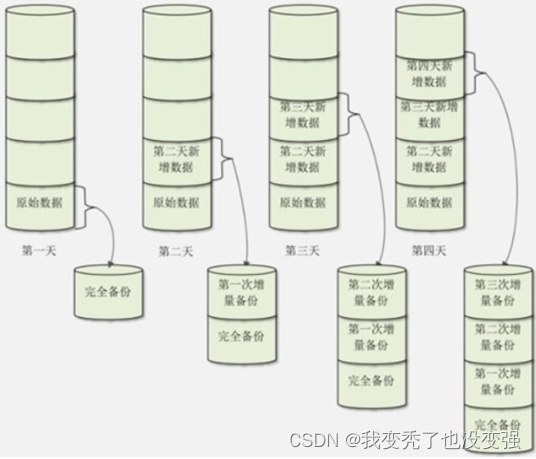
完全备份:整个数据集
部分备份:只备份数据子集,如部分库或表
完全备份、增量备份(见下左图)、差异备份(见下右图)
增量备份:仅备份最近一次完全备份或增量备份(如果存在增量)以来变化的数据,备份较快,还原复杂
差异备份:仅备份最近一次完全备份以来变化的数据,备份较慢,还原简单
注意:二进制日志文件不应该与数据文件放在同一磁盘
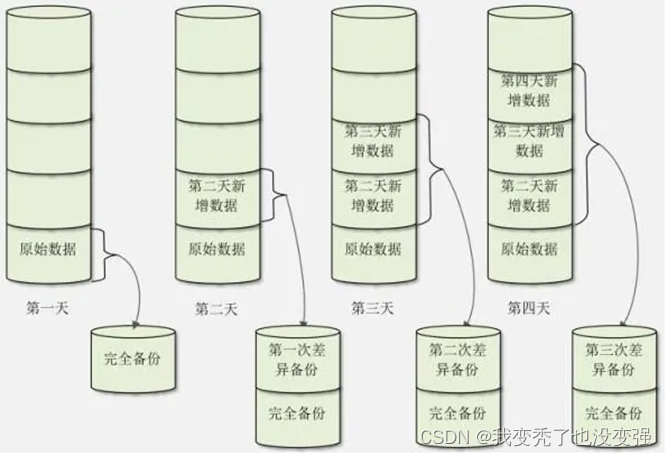
-
冷、温、热备份
冷备:读写操作均不可进行 //类似复制粘贴
温备:读操作可执行;但写操作不可执行 //锁表操作,不能往里写东西
热备:读写操作均可执行
MyISAM:温备,不支持热备
InnoDB:都支持
-
备份时需要考虑的因素
温备的持锁多久
备份产生的负载
备份过程的时长
恢复过程的时长
-
备份什么
6.1 数据
6.2 二进制日志、InnoDB的事务日志
6.3 程序代码(存储过程、函数、触发器、事件调度器)
6.4 服务器的配置文件
-
备份工具
7.1 cp, tar等复制归档工具:
物理备份工具,适用所有存储引擎;只支持冷备;完全和部分备份
7.2 LVM的快照:
先加锁,做快照后解锁,几乎热备;借助文件系统工具进行备份
7.3 mysqldump:
逻辑备份工具,适用所有存储引擎,温备;支持完全或部分备份;对InnoDB存储引擎支持热备,结合binlog的增量备份
-
尽量还原数据库的操作思路
实战案例:实现尽量还原数据库操作
思路:1:进行完全备份 例如:mysqldump -u root -p -A -F --single-transaction --master-data=2 > /opt/all.sql
2:进行完全备份之后时间点的模拟数据更新,模拟误删除,定位锚点
3:停服维护,使用mysqlbinlog新时间节点的二进制日志进行导出为SQL脚本
mysqlbinlog /data/logbin/mysql-bin.000003 > /opt/bin_log.sql
Vim bin_log.sql
解压,恢复
4:查看导出的二进制文件SQL脚本(注意:如果文件太大不要轻易打开或编辑),将删除SQL指令进行删除
5:启动服务,临时关闭二进制日志。恢复数据完成再打开
-
Mysql主从复制的基本原理
主从复制基本原理
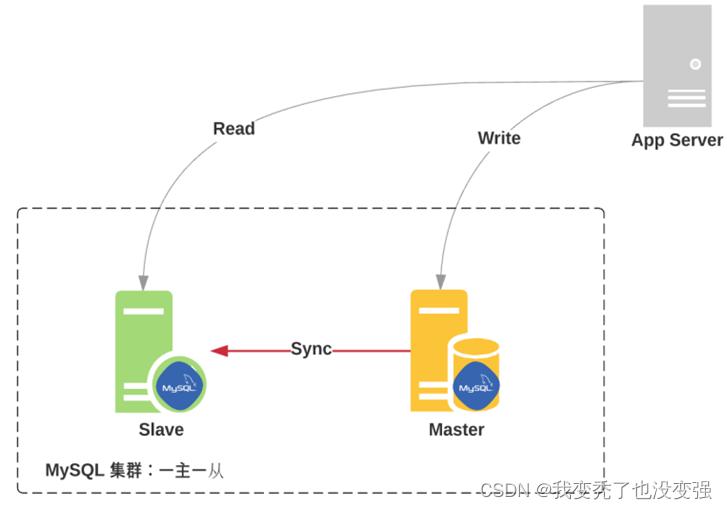
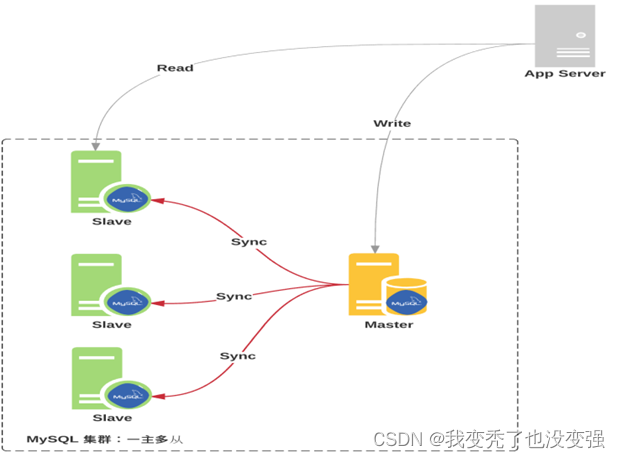
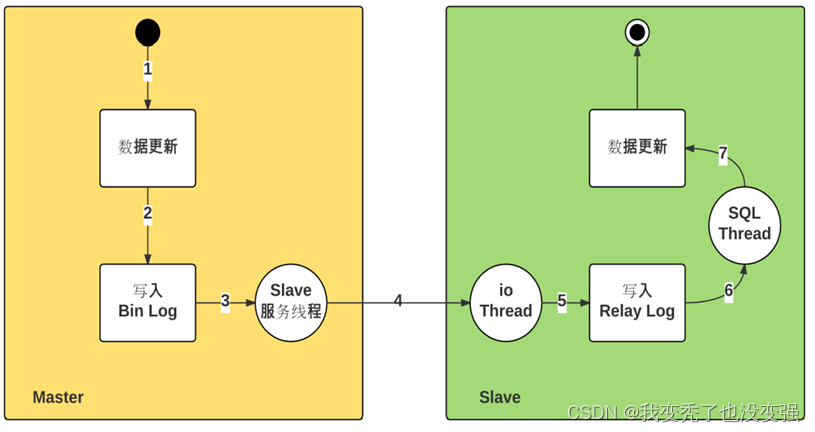
1.1.1 原理:
主节点负责数据的写操作,此时要求主节点启用二进制日志(bin-log)做数据更新,此时数据库的更改写入到二进制日志中。
在MySQL主服务器上会生成开启dump Thread 将新生成的二进制日志读出来,同时通过网络发送给从节点。
从节点开启I/O线程,开启中继日志,(I/O Thread,用于接收dump Thread传送过来的二进制日志),使用relay-log存放二进制日志。然后从服务器开启一个单独的线程(SQL Thread,用于读取relay-log进行重放 然后执行修改数据库中的数据)
-
Mysql主从复制的特点,故障排查的思路
主从复制特点:
异步复制
主从数据不一致比较常见
复制架构:
Master/Slave, Master/Master, 环状复制
一主多从
从服务器还可以再有从服务器
一从多主:适用于多个不同数据库
复制需要考虑二进制日志事件记录格式
STATEMENT(5.0之前)
ROW(5.1之后,推荐)
MIXED
主从配置故障诊断:
如果主节点已经运行了一段时间,且有大量数据时,如何配置并启动slave节点
通过备份恢复数据至从服务器
复制起始位置为备份时,二进制日志文件及其POS
步骤总结:①:修改master主节点配置 server-id log-bin
②:重启服务
③:备份master数据库,并添加--master-data=1
④:将备份的SQL脚本scp到新的从节点
⑤:从节点配置主配置文件的server-id read-only等
⑥:编辑拷贝的SQL脚本,加入change master to
⑦:进入SQL接口临时关闭二进制日志,导入主节点所有数据,开启slave线程,再开启二进制日志。
-
分库分表的基本原理
写的数据在某一个数据库,读的在一个数据库
只有主从复制,才能读写分离
读写分离应用:
mysql-proxy:Oracle,https://downloads.mysql.com/archives/proxy/
Atlas:奇虎360Qihoo,https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
dbproxy:美团,https://github.com/Meituan-Dianping/DBProxy
Cetus:网易乐得,https://github.com/Lede-Inc/cetus
Amoeba:https://sourceforge.net/projects/amoeba/
Cobar:阿里巴巴,Amoeba的升级版
Mycat:基于Cobar, http://www.mycat.io/
ProxySQL:https://proxysql.com/
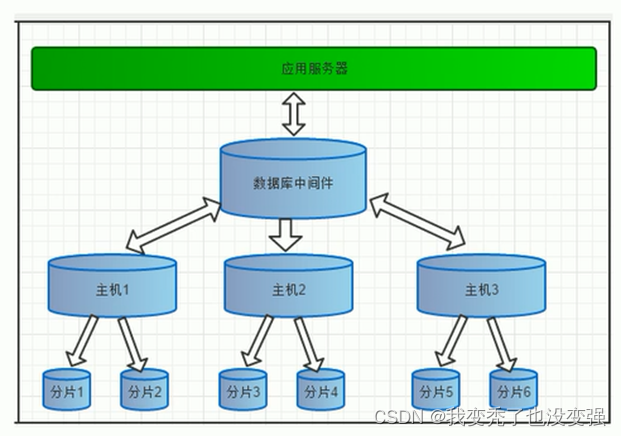
2.1 mycat介绍:
在整个IT系统架构中,数据库是非常重要的,通常又是访问压力比较大的一个服务,除了在程序开发的本身上做优化,代码优化,数据库的处理本身优化也是非常重要的。主从、热备、分表分库等都是系统发展迟早遇到的技术。
mycat是一个广受好评的数据库中间件,已经在很多产品上进行使用。
mycat是一个开源的分布式数据库系统(代理分布),实现MYSQL协议,前端用户可以把它看作一个数据库代理。
核心功能是分库分表,将一个大表水平分隔为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCat 是一个彻底开源的,面向企业应用数据库中间件 , 支持事务, 可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群, 在MyCat 中融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server ,并结合传统数据库和新型分布式数据仓库的新一代企业级数据库中间件产品。
-
mha高可用集群工作原理
MHA工作原理——背
1 MHA利用SELECT 1 As Value指令判断master服务器的健康性,一旦master宕机,MHA从宕机崩溃的master保存二进制日志事件(binlog events)
2 识别含有最新更新的slave
3 应用差异的中继日志(relay log)到其他的slave
4 应用从master保存的二进制日志事件(binlog events)
5 提升一个slave为新的master
6 使其他的slave连接新的master进行复制
-
NOSQL的分类
-
NoSQL分类
KV型(key-value):性能好(O1),如redis memcached
memcached 适用于做缓存
文档数据库(Document):mogodb、CouchDB
一般用于微博、微信、公众号、小程序、知乎等
Column Store列存数据库:HBase、Cassandra、大数据领域应用广泛
一般用于股票、基金
Graph DB数据库:Neo4j
Time Series(时序数据库):InfluxDB Prometheus
一般用于股票、基金
-
Memcached和redis的比较
-
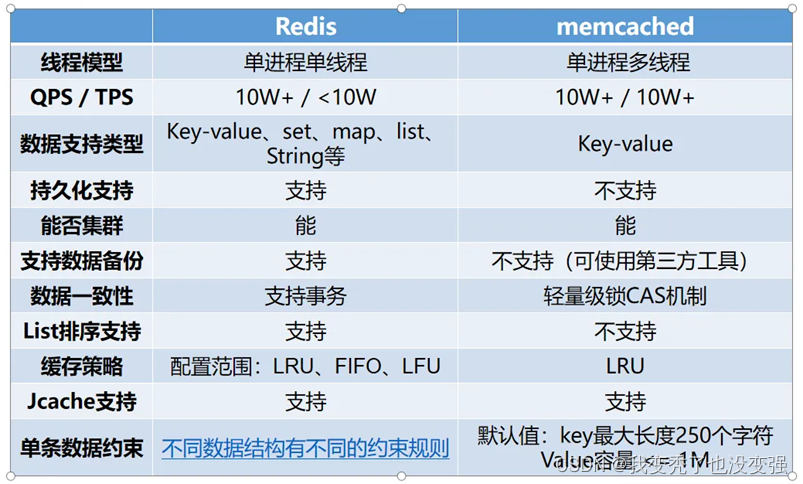
相同键值对数据库Redis和Memcached的比较
数据结构
Redis:哈希、列表、集合、有序集合 还能实现消息队列
memcached:纯key-value
是否支持持久化(最大区别)
Redis:支持
memcached:不支持
是否支持高可用:
Redis:支持,也支持读写分离、主从复制,官方还有集群管理功能,能实现主从监控、故障转移,无需人工干预。
memcached:不支持,但可以二次开发。
存储容量
Redis:最大512M
memcached:最大1M
内存分配
Redis:临时申请,可能导致碎片
memcached:预分配内存池,节省内存分配时间
单机QPS
Redis:10w
memcached:60w
redis新版本也支持多线程了
LRU:懒过期策略
-
Cache和buffer
缓存Cache和buffer缓冲
Cache涉及到读操作、buffer涉及到写操作
Buffer:缓冲,也叫写缓冲,一般用于写操作,可以将数据先写入内存再写入磁盘,buffer一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到自己最近的地方,以提高写入速度,CPU会把数据写到内存的磁盘缓冲区,然后应用就认为数据已经写入完成,然后由内核再后续的时间再写入磁盘,所以服务器突然断电会丢失内存中的部分数据。
从缓存区-磁盘速度快一点
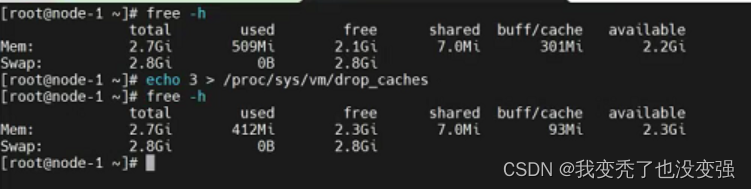
Cache:缓存,一般用于读操作,CPU读文件从内存读,如果内存没有就先从硬盘读到内存再读到CPU,将需要频繁读取的数据放在自己最近的缓存区域,下次读取的时候即可快速读取。清理缓存--->/proc/sys/vm/drop_caches
echo 1 > /proc/sys/vm/drop_caches 清理页缓存
echo 2 > /proc/sys/vm/drop_caches 清理元数据缓存
echo 3 > /proc/sys/vm/drop_caches 清理所有缓存
-
缓存保存位置和分层结构
-
缓存保存位置以及分层结构
互联网应用领域,cache is king
用户层:浏览器DNS缓存,DNS应用程序缓存,操作系统DNS缓存
代理层:CDN(阿里、通讯、华为、网宿),反向代理缓存
WEB层(页面缓存):解释器Opcache(动态资源缓存php),Web服务器缓存
应用缓存:页面静态化 现在做做动静分离基本上基于mvc框架
伪静态
数据层:分布式缓存,数据库
物理层:磁盘cache,Raid Cache
cache的特性:
自动过期:给缓存的数据上加上有效时间,超过时间后自动过期删除
强制过期:源网站更新图片后CDN是不会更新的,需要强制是图片缓存过期,通过CDN管理后台实现
命中率:
-
CDN的结构原理
CDN缓存
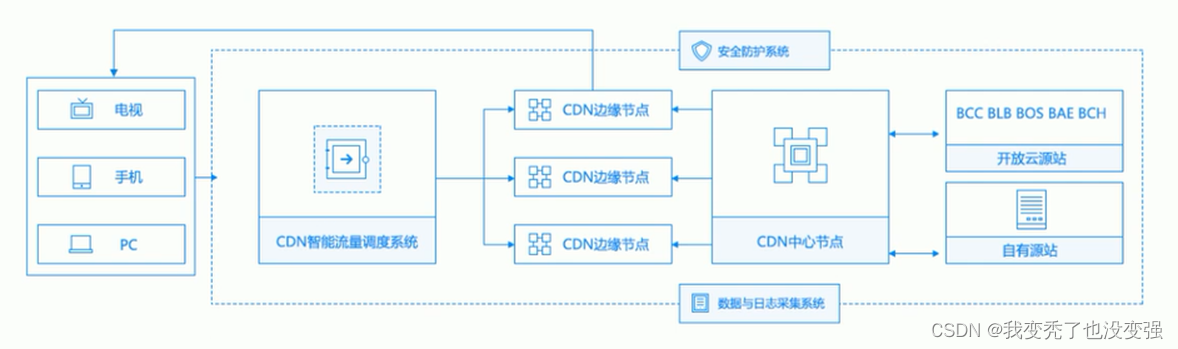
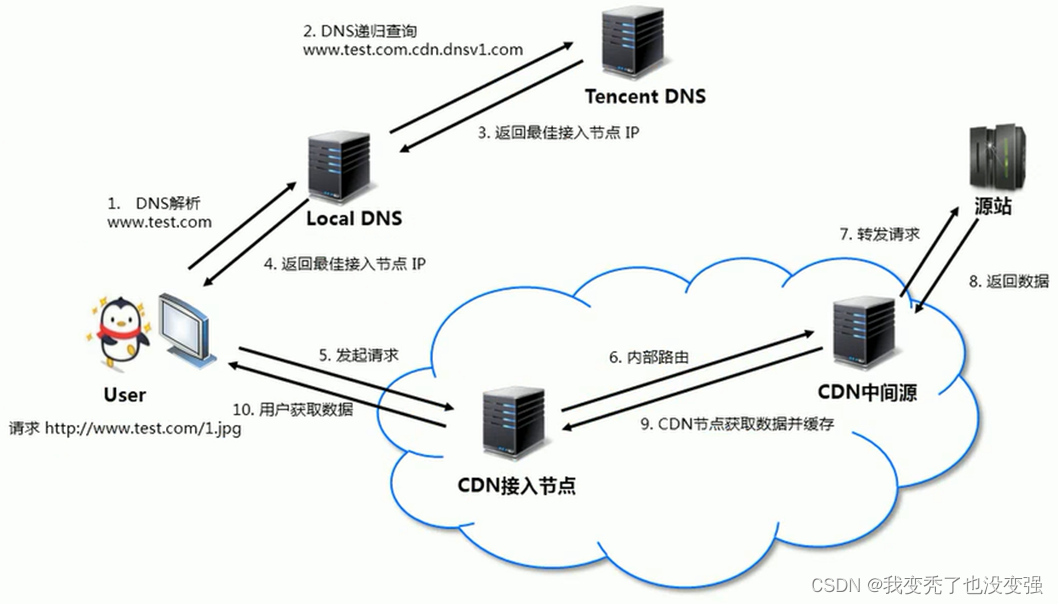
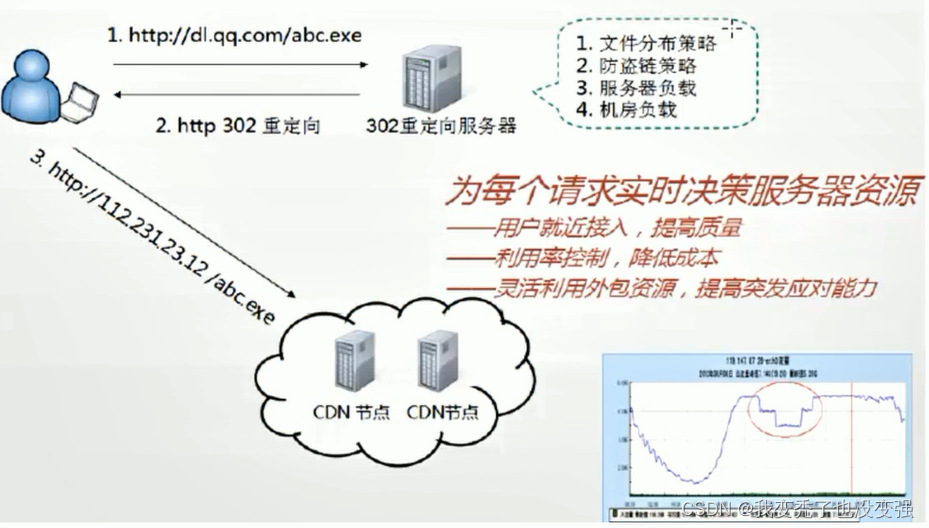
-
关系型数据库和非关系数据库的区别
关系型数据库和非关系型数据库的对比——背
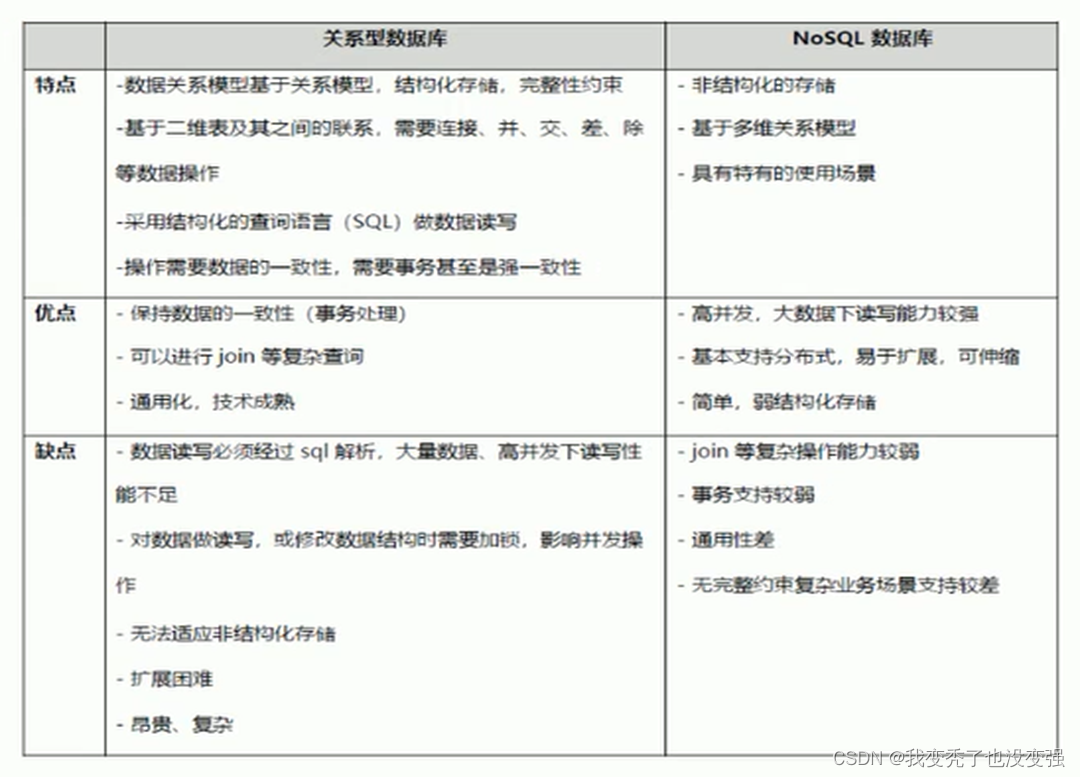
-
Redis的特点
速度快:10W QPS,基于内存,C语言实现
单线程(6.0版本后多线程——数据备份是多线程)
持久化
支持多种数据结构——最下面有图
支持多种编程语言的api
功能丰富:支持Lua脚本,发布订阅,事务、pipeline流水线 等功能
简单:代码短小精悍(单机核心代码只有23000左右),但线程开发容易,不依赖外部库,使用简单
主从复制
支持高可用和分布式
单线程:redis-6.0之前,可以基于多实例实现资源利用最大化。

-
Redis的应用场景
Session共享:常见于web集群中的Tomcat或者PHP等多种web应用程序服务器的session共享
缓存:数据查询、电商网站商品信息、新闻内容
计数器:访问排行榜、商品浏览数等和次数相关的数值统计场景
微博/微信社交场合:共同好友、粉丝数、关注、点赞评论等
消息队列:ELK的日志缓存、部分业务的订阅发布系统
地理位置:基于GEO(地理信息定位),实现摇一摇,附近的人,外卖等功能。
缓存雪崩、击穿、穿透原理和解决方案——具体要背
Redis 的缓存异常处理——缓存雪崩、缓存击穿、缓存穿透 - 腾讯云开发者社区-腾讯云
https://www.cnblogs.com/Deng-23-binb/p/15171957.html
-
数据更新的操作流程和读流程
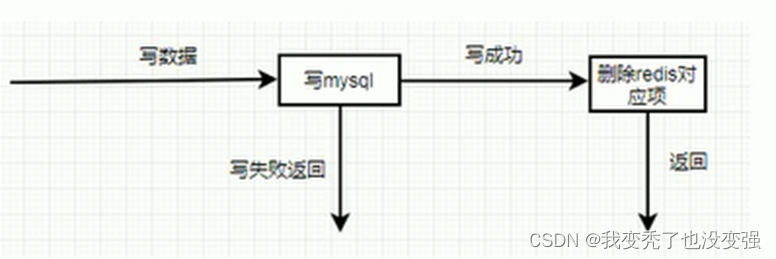
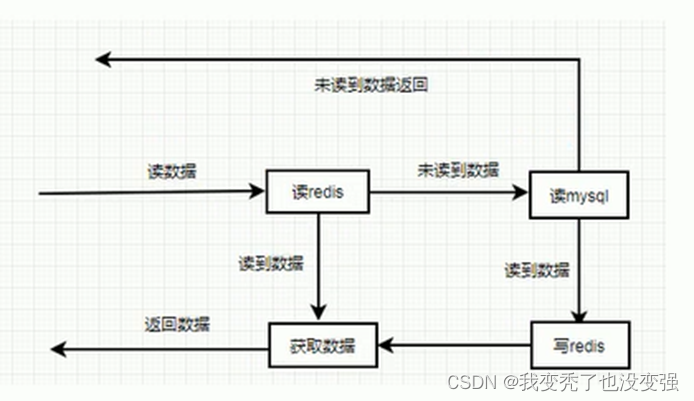
-
Redis的数据持久化,RD模式和AOF的原理,流程,备份策略
redis数据持久化
redis虽然是内存级别的缓存程序,但也可以将内存的数据按照一定的策略保存到硬盘上,从而实现数据的持久保存的目的。
目前redis支持两种不同方式的数据持久化保存机制,分别为RDB(类似覆盖)和AOF(不会消失)
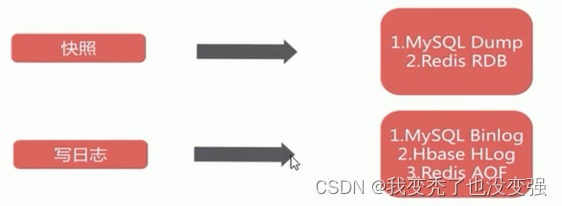
2.5.1 RDB模式
原理:基于时间的快照,默认只保留当前最新一次的快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间节点之间未快照的数据。
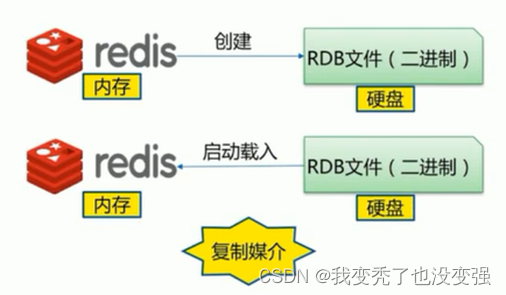
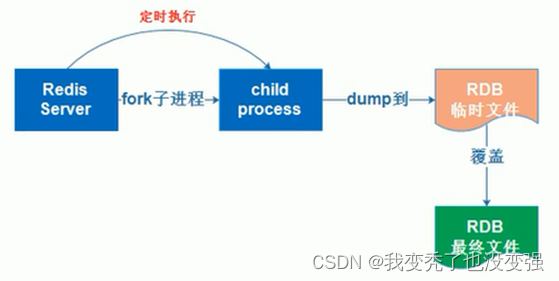
rdb做备份写数据的一个原理——背
redis从master主进程fork复制出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件,比如tmp-<pid>.rdb,当数据保存完成之后再将上一次保存的RDB文件进行替换,然后关闭子进程,这样可以保证每一次做RDB快照的数据都是完整的。
因为直接替换RDB文件的时候,可能会出现突然断电等问题,从而导致RDB文件还没有保存完整就突然关机停止保存,而导致数据丢失的情况,后续可以手动将每次生成的RDB文件进行备份,这样可以最大化保存历史数据
( redis-cli -p 6379 -a 666666 save & ); pstree -p | grep redis-server;ls -l /usr/local/redis/data/ //故意阻塞 看临时文件
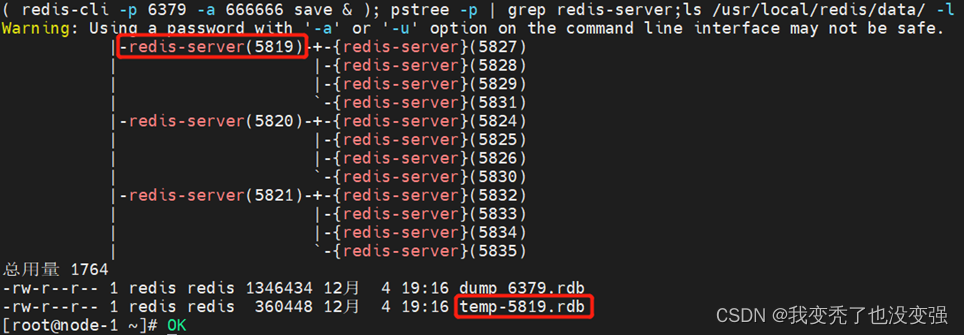
注意:①:恢复RDB数据的时候需要先停服,否则开机状态下拷贝会将新拷贝的数据写入内存,造成数据的差异化导致服务允许错误而停服。
②:不同版本的RDB数据不兼容
Redis的RDB快照备份策略
①:save 同步,生产环境再大规模的数据保存场景会产生阻塞,不推荐使用
②:bgsave 异步,后台执行,不影响其他命令的运行
③:自动 基于主配置文件进行设定
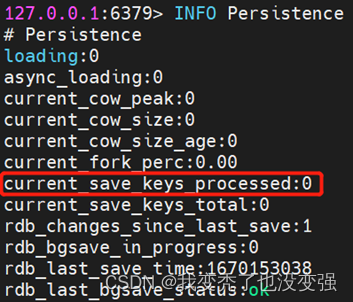
INFO Persistence 判断备份是否完成
AOF写数据三种策略
always(每次)
每次写入操作均同步到AOF文件中,数据零误差,性能较低,如果不是对数据非常严格不建议使用
everysec(每秒)
每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高,建议使用,也是默认配置,在系统突然宕机的情况下丢失1秒内的数据
no(系统控制)
由操作系统控制每次同步到AOF文件的周期,整体过程不可控
AOF:AppendOnlyFile 按照操作顺序依次将操作追加到指定的日志文件末尾
AOF和RDB一样使用了写时复制机制,AOF默认为每一秒中fsync一次,即将执行的命令保存到AOF文件当中,这样即便redis服务器发生故障最多只丢失1秒钟之内的数据,也可以设置不同的fsync策略always,即设置每次执行命令的时候执行fsync,fsync会在后台执行线程,所以主线程可以继续处理用户的正常请求而不受到写入AOF文件的I/O影响
注意:同时启用RDB和AOF,进行恢复时,默认AOF文件优先级高于RDB文件,即会使用AOF文件进行恢复

-
Redis的五大数据类型
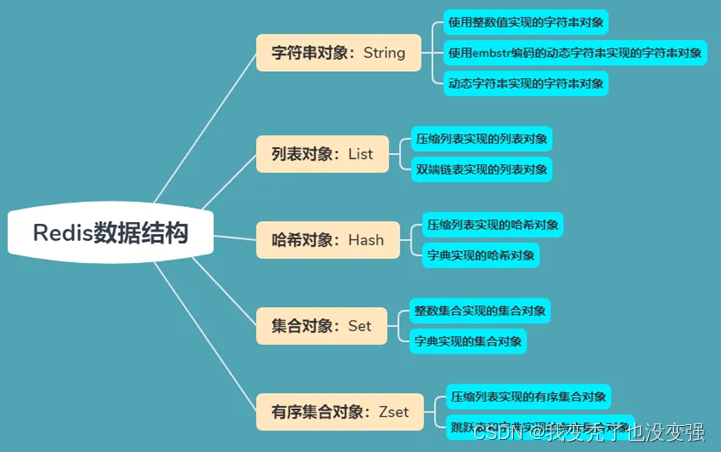
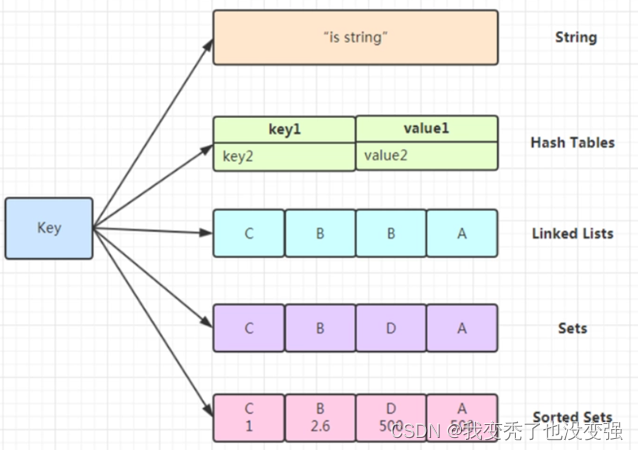
①:字符串
set 设置Key可以定义ex有效期
TTL可以查看过期时间 -1为永久有效 -2为此值不存在
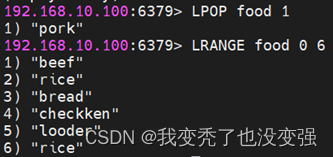
②:列表-主要做消息队列 是基于索引(下标)指引——用推送的方式插入
LPUSH(左->右) 创建或推送列表 LINDEX(右->左) 基于下标显示元素数据
LLEN 查询列表的数据长度
LRANGE 遍历列表连续下标的所有元素
LPOP 左侧开始弹出N个元素
RPOP 右侧开始弹出N个元素

![]()
③:无序集合
特点:元素内部没有次序,不重复。此数据类型一般用于取并集交集等相关的操作。
SADD 创建集合
SMEMBERS 列出某个集合的相关元素
SINTER:取多个集合的交集
SUNION:取并集
SDIFF:取差集
④:有序集合-一般用于做技术排名
特点:有序、无重复元素、每个元素是由score(可以重复)和value(不可重复)组成
ZADD 添加有序集合
ZRANGE:正序排序
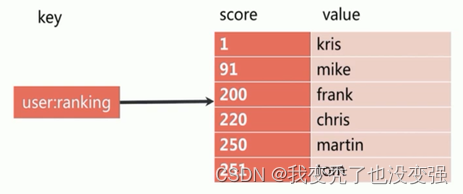
⑤:哈希hash
哈希:即字典,hash的value即也为一个键值对(kv)
HSET添加HASH数据
HDEL删除hash中的某个键值对
HGET 查询hash中的某个键值对数据
-
Redis主从复制的同步原理
主从复制的同步原理——背
主从复制的原理、优化、故障诊断
https://blog.csdn.net/qq_38571892/article/details/115626326
主从复制的数据分为全量数据同步和增量数据同步
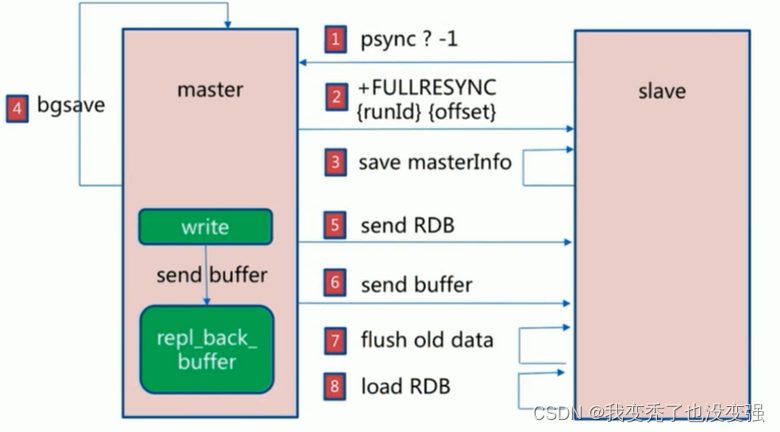
从服务器连接主服务器,发送PSYNC命令,主服务器接收到PSYNC命令后,开始执行BGSAVE命令生成RDB快照文件,并使用缓冲区记录此后执行的所有写命令,主服务器BGSAVE执行完后,向所有从服务器发送RDB快照文件,并在发送期间继续记录被执行的写命令,从服务器收到快照文件后丢弃所有旧数据,载入收到的快照至内存主服务器快照发送完毕后,开始向从服务器发送缓冲区中的写命令从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令后期同步会先发送自己slave_repl_offset位置,只同步新增加的数据,不再全量同步(除非从节点联系不到主节点),差值过大也会做全量
-
Redis-cluster工作原理
Redis Cluster 工作原理
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以保证redis服务的正常使用,但是无法解决reds单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大小、并发数量、网卡速率等因素。为了解决单机性能的瓶颈,提高Redis 性能,可以使用分布式集群的解决方案
-
Redis-cluster特点
Redis Cluster五大基本特点
①:所有Redis节点使用(PING机制)互联
②:集群中某个节点是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效,内置一个哨兵,做了Redis Cluster等于做了哨兵和redis主从复制
③:客户端不需要proxy即可直接连接redis,应用程序中需要配置有全部的redis服务器IP
④:redis cluster把所有的redis node平均映射到0-16383个槽位slot上,读与需要到指定的redis node上进行操作,因此有多少redis node相当于redis 并发扩展了多少倍,每个redis node 承担16384/N个槽位
⑤:Redis cluster预先分配16384slot,槽位,当需要在redis集群中写入key-value的时候,会使用RC16key算法 md 16384之后的值,决定将Kev写入值哪个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈。

-
什么是ELK
什么是 ELK——搜索引擎数据库、使用分布式采集基于json格式文档——可扩充的非关系型数据库
ELK是由一家elastic公司开发的三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。三个项目各有不同的功能,之后又增加了许多新项目, 于是 从5.X版本后改名为Elastic Stack
Elasticsearch:是一个实时的全文搜索,存储库和分析引擎。
Logstash:是服务器端数据处理的管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如Elasticsearch 等存储库中。也可以转tcp这种数据流,缺点:沉重(java开发)
Kibana:则可以让用户在 Elasticsearch中使用图形和图表对数据进行可视化。
Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
-
什么是elasticsearch
Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch 在 Apache Lucene 的基础上开发而成,由Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件
Elasticsearch 支持数据的实时全文搜索搜索、支持分布式和高可用、提供API接口,可以处理大规模的各种日志数据的处理,比如: Nginx、Tomcat、系统日志等功能。
Elasticsearch 基于 Java 语言开发,利用全文搜索引擎 Apache Lucene 实现
-
什么是Kibana
Kibana(5601)
Kibana 为 elasticsearch 提供一个查看数据的 web 界面,其主要是通过elasticsearch 的 API 接口进行数据查找,并进行前端数据可视化的展现,另外还可以针对特定格式的数据生成相应的表格、柱状图、饼图等。
Kibana 是一款适用于 Elasticsearch 的基于Javascript语言实现的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。Kibana 同时还包括诸如 Canvas (新版本有的)和 Elastic Maps 等高级应用程序;
Canvas 允许用户基于自身数据创建定制的动态信息图表,而 Elastic Maps 则可用来对地理空间数据进行可视化。
官方文档 https://www.elastic.co/cn/what-is/kibana
主要是通过接口调用elasticsearch的数据,并进行前端数据可视化的展现。
Kibana 与 Elasticsearch 和更广意义上的 Elastic Stack 紧密的集成在一起,这一点使其成为支持以下场景的理想选择:
搜索、查看并可视化 Elasticsearch 中所索引的数据,并通过创建柱状图、饼图、表格、直方图和地图对数据进行分析。仪表板视图能将这些可视化元素组织到一起,然后通过浏览器进行分享,以提供对海量数据的实时分析视图,所支持的用例如下:
1. 日志处理和分析
2. 基础设施指标和容器监测
3. 应用程序性能监测 (APM)
4. 地理空间数据分析和可视化
5. 安全分析
6. 业务分析
-
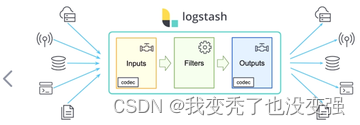
什么是Logstash,支持哪些插件,6-7个
Logstash 是一个具有实时传输能力的数据收集引擎,其可以通过插件实现日志收集和转发,支持日志过滤,支持普通 log、自定义 json 格式的日志解析,最终把经过处理的日志发送给 elasticsearch。
-
ELK stack 主要优点
文档、索引、副本、分片、字段
功能强大:Elasticsearch是实时全文索引,具有强大的搜索功能
配置相对简单:Elasticsearch 全部基于 JSON,Logstash使用模块化配置,Kibana(5601)的配置都比较简单。
检索性能高效:基于优秀的设计,每次查询可以实时响应,即使百亿级数据的查询也能达到秒级响应。
集群线性扩展:Elasticsearch 和 Logstash都可以灵活线性扩展
前端操作方便:Kibana提供了比较美观UI前端,操作也比较简单
EFK 由ElasticSearch、Fluentd和Kiabana三个开源工具组成。Fluentd是一个实时开源的数据收集器,和logstash功能相似,比logstash轻量,这三款开源工具的组合为日志数据提供了分布式的实时搜集与分析的监控系统。
Fluentd官网和文档:
Fluentd | Open Source Data Collector | Unified Logging Layer
-
原理
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。数据采集指在Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。在Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数组、地理位置或其他类型的数据)之间建立联系。key-value形式
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
-
基本概念
Near Realtime(NRT) 几乎实时
Elasticsearch是一个几乎实时的搜索平台。意思是,从索引一个文档到这个文档可被搜索只需要一点点的延迟,这个时间一般为毫秒级。
Cluster 集群
群集是一个或多个节点(服务器)的集合, 这些节点共同保存整个数据,并在所有节点上提供联合索引和搜索功能。一个集群由一个唯一集群ID确定,并指定一个集群名(默认为“elasticsearch”)。该集群名非常重要,因为节点可以通过这个集群名加入群集,一个节点只能是群集的一部分。确保在不同的环境中不要使用相同的群集名称,否则可能会导致连接错误的群集节点。拆分化、组合性、联合性
Node节点
节点是单个服务器实例,它是群集的一部分,可以存储数据,并参与群集的索引和搜索功能。就像一个集群,节点的名称默认为一个随机的通用唯一标识符(UUID),确定在启动时分配给该节点。如果不希望默认,可以定义任何节点名。这个名字对管理很重要,目的是要确定网络服务器对应于ElasticSearch群集节点。
Document 文档
文档是可以被索引的信息的基本单位。例如,您可以为单个客户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。本文件的表示形式为JSON(JavaScript Object Notation)格式,这是一种非常普遍的互联网数据交换格式。在索引/类型中,您可以存储尽可能多的文档。
Shards & Replicas/ˈrɛplɪkəz/ 分片与副本
老版本默认分5片,新版本默认分1片一副本
索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文件占用磁盘空间1TB的单指标可能不适合对单个节点的磁盘, 或者仅从单个节点的搜索请求服务可能太慢,为了解决这一问题,Elasticsearch提供细分指标分成多个块称为分片的能力。当创建一个索引,可以简单地定义想要的分片数量。每个分片本身是一个全功能的、独立的“指数”,可以托管在集群中的任何节点。
Shards分片的重要性主要体现在以下两个特征:
分片允许您水平拆分或缩放内容的大小
分片允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量
这个机制中的碎片是分布式的以及其文件汇总到搜索请求是完全由ElasticSearch管理,对用户来说是透明的。
在同一个集群网络或云环境上,故障是任何时候都会出现的,拥有一个故障转移机制以防分片和结点因为某些原因离线或消失是非常有用的,并且被强烈推荐。为此,Elasticsearch允许你创建一个或多个拷贝,索引分片进入所谓的副本或称作复制品的分片,简称Replicas。
Replicas的重要性主要体现在以下两个特征:
副本为分片或节点失败提供了高可用性。为此,需要注意的是,一个副本的分片不会分配在同一个节点作为原始的或主分片,副本是从主分片那里复制过来的。
副本允许用户扩展你的搜索量或吞吐量,因为搜索可以
-
Elk应用场景
运维主要应用场景:
将分布在不同主机的日志统一收集,并进行转换,通过集中的WebUI进行查询和管理,通过查看汇总的日志,找到故障的根本原因
Web 展示和报表功能
实现安全和事件等管理
大数据运维主要应用场景:
查询聚合, 大屏分析
预测告警, 网络指标,业务指标安全指标
日志查询,问题排查,基于API可以实现故障恢复和自愈
用户行为,性能,业务分析
-
集群工作原理
ES的节点有三种
1.1 Master 节点
ES集群中只有一个 Master 节点,用于控制整个集群的操作
Master 节点负责增删索引,增删节点,shard分片的重新分配
Master 主要维护Cluster State,包括节点名称,节点连接地址,索引名称和配置认证等
Master 接受集群状态的变化并推送给所有节点,集群中各节点都有一份完整的集群状态信息,都由master node负责维护
Master 节点不需要涉及到文档级别的变更和搜索等操作协调创建索引请求或查询请求,将请求分发到相关的node上。
当Cluster State有新数据产生后, Master 会将数据同步给其他 Node 节点
Master节点通过超过一半的节点投票选举产生的
可以设置node.master: true 指定为是否参与Master节点选举, 默认true
1.2 Data 节点
存储数据的节点即为 data 节点
当创建索引后,索引创建的数据会存储至某个数据节点
Data 节点消耗内存和磁盘IO的性能比较大
配置node.data: true, 默认为 true,即默认节点都是 data类型
1.3 Coordinating 节点(协调)
-
ES集群分片和副本-根据自己理解
①:分片 Shard
ES 中存储的数据可能会很大,有时会达到PB级别,基于性能和容量等原因,可以将一个索引数据分割成多个小的分片,再将每个分片分布至不同的节点,从而实现数据的分布存储,实现性能和容量的水平扩展;在读取时,可以实现多节点的并行读取,提升性能
除此之外,如果一个分片的主机宕机,也不影响其它节点分片的读取横向扩展即增加服务器,当有新的Node节点加入到集群中时,集群会动态的重新进行分配和负载;例如原来有两个Node节点,每个节点上有3个分片,即共6个分片,如果再添加一个node节点到集群中,集群会动态的将此6个分片分配到这三个节点上,最终每个节点上有两个分片。
7,X 默认每个索引只有一个分片
②:副本 Replication
将一个索引分成多个分片,仍然存在数据的单点问题,可以对每一个分片进行复制生成副本,即备份,实现数据的高可用
ES的分片分为主分片(primary shard)和副本分片(复制replica shard),而且通常分布在不同节点
主分片实现数据读写,副本分片只支持读每个数据分片只有一个主分片,而副本分片可以有多个,比如;一个副本,即有一个备份
7,X 默认每个索引只有一个副本分片
ES故障后先基于集群选举然后再故障转移,但分片的数据丢失,需要副本支持。
注意:
ES7.0版本默认分片为1个,并且只有1个副本
ES6.X版本前默认分片为5个副本1个
-
ES文档创建流程和读取流程
ES 文档创建流程
master节点——发布命令交给协调节点
node节点
协调节点——没有协调节点master充当协调节点
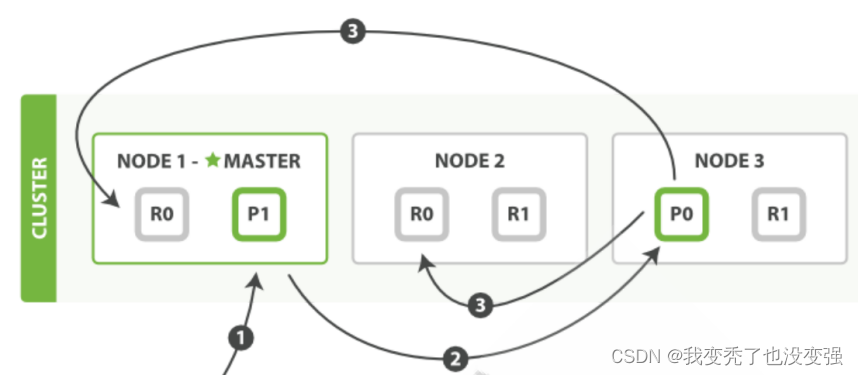
客户端向协调节点 Node1 发送新建索引文档或者删除索引文档请求。
Node1节点使用文档的 _id 确定文档属于分片 0 。
因为分片 0 的主分片目前被分配在 Node 3 上,请求会被转发到 Node 3
Node3 在主分片上面执行创建或删除请求
Node3 执行如果成功,它将请求并行转发到 Node1 和 Node2 的副本分片上。
一旦所有的副本分片都报告成功, Node3 将向协调节点Node1 报告成功,协调节点Node1 客户端报告成功。在客户端收到响应时,文档变更已经在主分片和所有副本分片执行完成
4:ES 文档读取流程
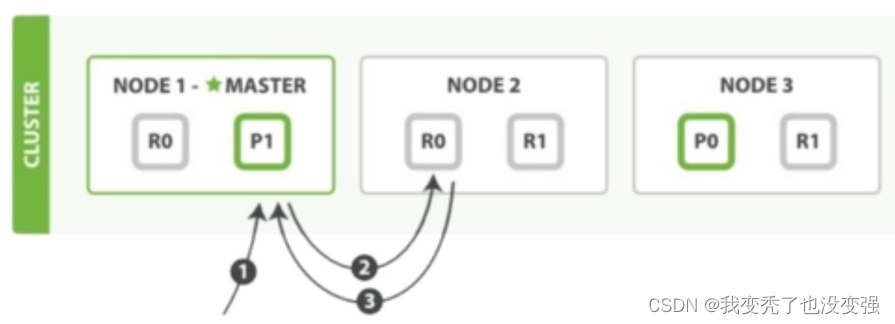
客户端向 Node1 发送读取请求。
节点使用文档的 _id 号来确定文档属于分片 0。分片 0 的副本分片存在于所有的三个节点上。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在这种情况下,它将请求转发到 Node2 。
Node2 将文档返回给 Node1 ,然后将文档返回给客户端。
-
常见的解决方案和软件 5个
开源监控软件:cacti(监控流量)、nagios(传统型企业用的多,报警系统强)、zabbix(各方面都很强,支持分布式)、smokeping、open-falcon(小米猎鹰)、Nightingale(滴滴夜莺)、Prometheus(普罗米修斯,适用于云原生环境)等
商业监控方案:http://ping.chinaz.com/ 站长之家
https://www.jiankongbao.com/ 监控宝
https://www.toushibao.com/ 透视宝
https://www.tingyun.com/ 听云
-
监控模式 ①:IPMI——基于硬件的监控模式,温度湿度运行状况
②:SNMP——网络数据监控,比如cisco的交换机路由器
③:agent——普通监控模式(监控的代理端),默认情况下,zabbix为server-agent模式
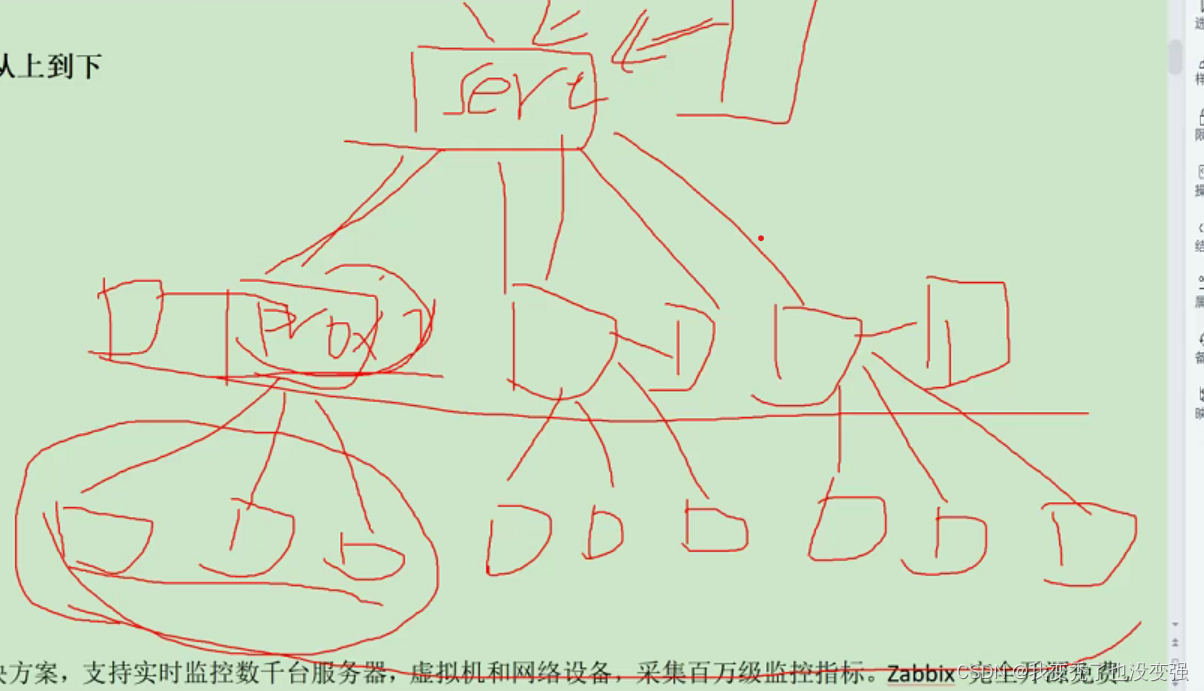
④:Proxy——分布式监控
⑤:API——关联第三方api,可以实现对其他类型的监控
-
Zabbix主要特点
指标收集:从任何设备、系统、应用程序上进行指标采集
问题监测:定义智能阈值(yuzhi)
可视化:基于ui界面进行统一界面管理
告警和修复:确保及时、有效的告警(超过阈值关联触发器进行故障自愈)
安全和认证:保护您所有层级的数据 支持证书
轻松搭建部署:大批模板,开箱即用,节省您宝贵的时间
自动发现:自动监控大型动态环境,其他agent关联10051端口,支持服务自动发现,纳入到自己的监控体系
分布式监控:基于proxy可以无限制扩展
ZABBIX API :将 Zabbix 集成到您 IT 环境的其他任何部分
-
两幅图:主要功能和主要架构
Zabbix 完整监控流程:
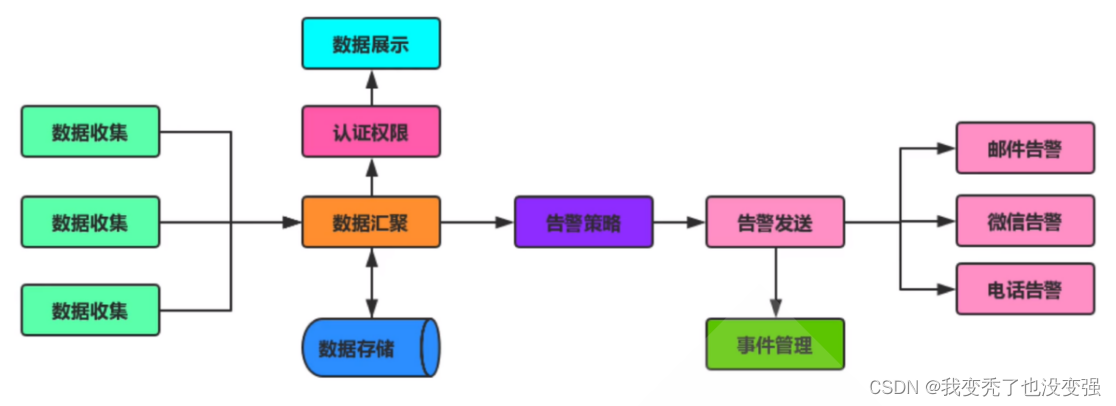
被监控端安装agent应用程序,被监控端可以采集数据,基于主动模式或被动模式将历史数据或者趋势数据发送给zabbix的服务端,服务端会将数据进行汇聚,将历史数据存储到数据库,关联他的认证执行系统,将收集的趋势数据基于特定的UI格式展示出来,同时汇聚的数据到告警策略区,一旦数据指标出现超过阈值的情况,会触发告警策略,关联到用户管理系统、认证执行系统、媒介系统,动作系统,发送告警,会关联后面的告警媒介,基于邮件微信电话或者短信告警,同时将告警的事件记录到事件管理器,在主面板展示出来,故障修复之后,事件管理器会重新定义事件,将已经修复的事件移除。
-
Zabbix体系架构
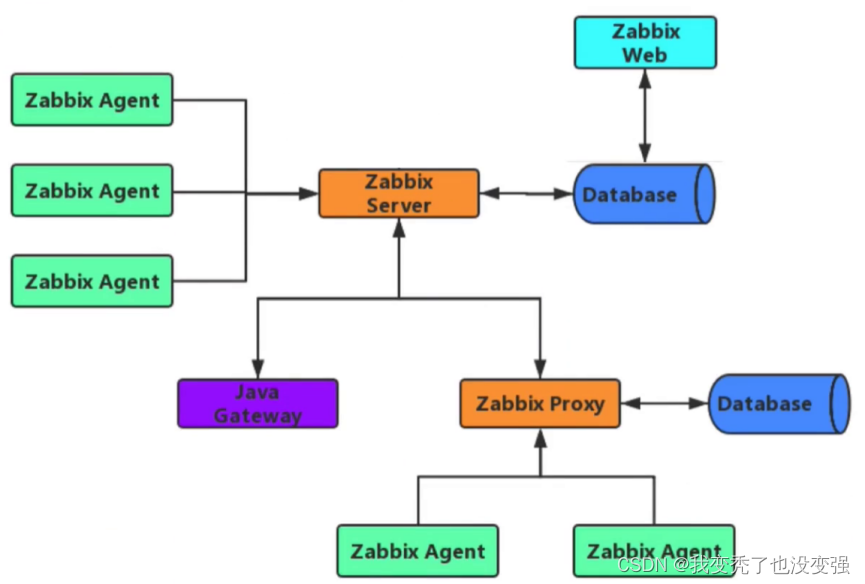
Zabbix支持多种模式,zabbix支持普通的zabbix server到zabbix agent端模式,也支持zabbix-sever到zabbix-proxy模式,zabbix-server同时关联多个zabbix-agent,将zabbix-agent的历史数据存储到zabbix-server管理的数据库中,然后经过zabbix的web(也就是nginx)展示出来;
zabbix支持proxy代理模式,只需要授权proxy监听在特定的端口上10052,而对应的proxy会独立的管理他下面的zabbix-agent,并将zabbix-agent的数据存储到proxy管理的数据库中,zabbix-server没有存储zabbix-proxy数据的功能,是将proxy的数据放到zabbix web展示区进行展示;
Zabbix是基于php开发的,默认使用fastcgi,而Java不支持fastcgi模式,为了采集展示进行可视化java对应的指标数据,要让Java支持fastcgi,需要安装一个JMX的java类,zabbix关联java gateway,java中的应用体系支持gateway进行绑定起来,基于JMX就可以收集到Java gateway的数据并将其在zabbix web上进行图表展示。
-
内部配置的主要流程
Zabbix 内部的数据流对Zabbix的使用也很重要。首先,为了创建一个采集数据的监控项,就必须先创建主机。其次,在任务的另外一端,必须要有监控项才能创建触发器(trigger),必须要有触发器来创建动作(action)。因此,如果您想要收到类似“X个server上CPU负载过高”这样的告警,您必须首先为 Server X 创建一个主机条目,其次创建一个用于监控其 CPU的监控项,最后创建一个触发器,用来触发 CPU负载过高这个动作,并将其发送到您的邮箱里。虽然这些步骤看起来很繁琐,但是使用模板的话,实际操作非常简单。也正是由于这种设计,使得 Zabbix 的配置变得更加灵活易用。
-
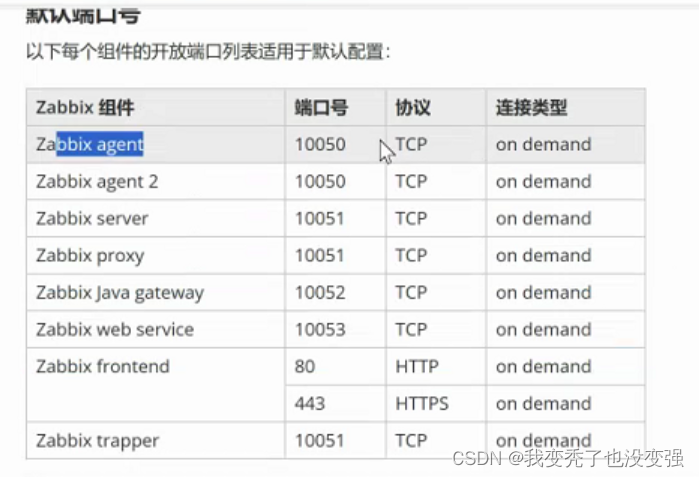
架构里面的名词定义
4.1 相关名词
SERVER
Zabbix server 是 Zabbix 软件的核心组件
Zabbix Agent 向其报告可用性、系统完整性信息和统计信息。
Zabbix server也是存储所有配置信息、统计信息和操作信息的核心存储库。
Zabbix server也是Zabbix监控系统的告警中心。在监控的系统中出现任何异常,将发出通知给管理员。
基本的 Zabbix Server 的功能分解成为三个不同的组件。他们是:Zabbix server、Web前端和数据库。
Zabbix 的所有配置信息都存储在 Server和Web前端进行交互的数据库中。例如,当你通过Web前端(或者API)新增一个监控项时,它会被添加到数据库的监控项表里。然后,Zabbix server 以每分钟一次的频率查询监控项表中的有效项,接着将它存储在 Zabbix server 中的缓存里。这就是为什么 Zabbix前端所做的任何更改需要花费两分钟左右才能显示在最新的数据段的原因。
数据库
所有配置信息以及 Zabbix 采集到的数据都被持久存储在数据库中
可以支持MySQL,PostgreSQL,Oracle 等多种数据库
WEB 界面
WEB 界面是 Zabbix server 的一部分,用于实现展示和配置的界面
通常(但不一定)和 Zabbix server 运行在同一台物理机器上
基于 Apache(Nginx)+PHP 实现,早期只支持LAMP架构,从Zabbix5.0开始支持LNMP
AGENT
Zabbix agents 部署在被监控目标上,用于主动监控本地资源和应用程序,并将收集的数据发送给
Zabbix server。从Zabbix5.0开始支技Zabbix Agent2
版本:
agent 基于c开发比较沉重
agent2 基于go开发比较轻量
PROXY
Zabbix Proxy 可以代替 Zabbix Server 采集性能和可用性数据
Zabbix Proxy 在 Zabbix 的部署是可选部分
Zabbix Proxy 的部署可以很好的分担单个Zabbix server的负载
Java 网关
Zabbix 要监控 tomcat 服务器和其它JAVA程序,需要使用 Java gateway 做为代理,才能从JAVA程序中获取数据
-
Zabbix的术语
被监控: 即 Zabbix 监控的主机或设备
监控项item:即 Zabbix 监控的相关指标,比如:CPU利用率,内存使用率,TCP连接数等。监控项可以自定义
应用集Application:为方便管理众多的监控项,可将多个同类型的监控项进行归类,纳入一个集合中,即应用集
触发器Trigger:是一个表达式,或者说一个条件,如磁盘利用率超过80%等,当触发条件后,会导致一个触发事件,这个事件会执行一个或多个动作
动作Action:动作是触发器的条件被触发后的行为,可以是发送一条短信,微信或邮件,或是重启某个服务
告警:当触发器和动作二者结合起来时,就构成了的告警机制,比如cpu的使用率达到80%以上,触发了报警动作,系统将自动发送一封邮件到指定的邮箱。然后运维可以及时的去处理此错误。
Web 监测:对WEB服务进行检测,比如:访问指定网站是否可正常访问
模板 Template: 可以方便地应用于多个主机的一组实体的集合。而这些实体包括:
items(监控项)
applications(应用集)
triggers(触发器)
graphs(图形)
screens (聚合图形,自Zabbix 2.0起)
陷入器(trapper)——用于处理主动采集、陷入以及分布式节点间或服务器代理的通信
不可到达轮询器(unreachable poller)——用于轮询不可到达到的设备
vmware 收集器(vmware collector)——负责从vmware服务进程中收集数据(服务器代理端不支持这种类型的进程);
可用的mode参数包括:
avg——指定类型所有进程的平均值
count——返回创建的指定类型进程的数量
max——最大值
min——最小值
——进程号,含义参见“描述”中所述的;
可用的state参数包括:
繁忙(busy)——表示处于繁忙状态的进程;
空闲(idle)——表示处于空闲状态的进程;
low-level discovery rules (自动发现规则 ,自Zabbix 2.0起)
web scenarios (web场景, 自Zabbix 2.0起)。
-
自定义监控项的基本原理和完整流程
自定义监控项配置流程
首先要确定好agent端盒server端要监控的指标是什么,在agent端对应的配置文件中编写要监控的脚本,agent端的agent主配置文件要编写userparameter,定义key和传递的参数,传递多个参数可以用位置$1,$2来传递中括号里面的参数,在zabbix的server端或者proxy端使用zabbix-get对其进行探测是否异常,正常的话后期就关联到自定义监控项的模版中,并做后续的绘图。



















 2418
2418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











