









一. 生产环境服务器变慢,诊断思路及性能评估
- 查看整机性能 top命令查看整机性能 load average平均1、5、15分钟负载值相加除以3乘100%是否大于60%

- 系统性能精简版命令uptime

- 查看CPU:vmstat -n 2 3第一个参数时间间隔数、第二个参数采样次数
- procs
- r:运行和等待CPU时间片的进程树原则上是1核CPU运行队列不超过2,整个系统运行队列不超过总核数的2倍,否则表示系统压力过大
- b:等待资源进程数,比如正等待磁盘I/O、网络I/O等
- CPU
- us:用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序
- sy:内核进程消耗CPU时间百分比
- id:处于空闲的CPU百分比
- wa:等待IO的CPU时间百分比
- st:来自于虚拟机偷取CPU时间的百分比

- CPU:查看所有CPU信息 mapstat -P ALL 2 3 %idle

- CPU: pidstat -u 1 -p 进程编号 用户每秒采样一次

- 内存:free -m
- 经验值
- 应用程序可用内存/物理内存>70%内存充足
- 应用程序可用内存/物理内存<20%内存不足,需要增加内存
- 20%< 应用程序可用内存/物理内存<70%内存基本够用

- 内存:pidstat -p 进程号 -r 采样间隔数 总共采样次数(pidstat -p 2545 -r 2 5)

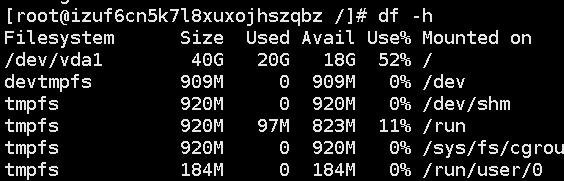
- 硬盘:查看磁盘剩余空间 df -h
- 网路IO:iostat -xdk 2 3
- 磁盘块设备分布
- 具体参数解释
- rkB/s每秒读取数据量KB
- wkB/s每秒写入数据量KB
- svctm I/O请求的平均服务时间,单位毫秒
- util一秒钟有百分之记得时间用于I/O操作。接近100%,表示磁盘带宽跑满,需要优化程序或增加磁盘
- rkB/s、wkB/s根据系统不同会有不同值,但规律遵循:长期、超大数据读写,肯定不正常,需要优化程序
- scvm的值和await的值接近,表示没有I/O等待,磁盘性能好
- 如果await的值远高于scvm的值,表示I/O等待时间太长,需要优化程序或更换磁盘

- 查看网络I/O: pidstat -d 2 5 -p 2545

二. CPU占用过高,分析思路及定位
- 先用top命令找出CPU占比最高的

- ps -ef或jps进一步定位,的值是怎样一个程序给我们惹事

- 定位到具体线程或代码 ps -mp 24425 -o THREAD,tid,time
- 参数解释
- -m 显示所有线程
- -p pid线程使用CPU的时间
- -o 该参数后是用户自定义格式
es 6.1 19 - futex_ - - 24463 6-05:04:23

- 将需要的线程ID转化为16进制格式(英文小写格式) printf “%x\n” 有问题的线程ID
- 具体步骤
- 将10进制的线程ID转化为16进制格式
- jstack 24425 | grep tid(16进制线程ID小写英文) -A60

















 1533
1533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









