






 Linux服务器在高负载下易出现性能瓶颈,可从硬件和软件方面优化。软件层从内核参数、CPU、IO、网络、内存等方面调优。介绍了系统优化步骤、性能相关概念,还阐述了vmstat、mpstat等工具监控资源信息,以及CPU、内存、磁盘、网络的调优方法。
Linux服务器在高负载下易出现性能瓶颈,可从硬件和软件方面优化。软件层从内核参数、CPU、IO、网络、内存等方面调优。介绍了系统优化步骤、性能相关概念,还阐述了vmstat、mpstat等工具监控资源信息,以及CPU、内存、磁盘、网络的调优方法。
Linux操作系统性能调优
前言:
Linux服务器运行了很多应用,在高负载下,服务器可能会出现性能瓶颈,例如CPU利用率过高、内存不足、磁盘I/O瓶颈等,从而导致系统卡顿,服务无法正常运行等问题。所以针对以上问题,可以通过调整内核参数和系统的相关组件,优化应用程序来提高服务器的性能和稳定性,避免系统崩溃和服务中断
Linux系统优化考虑的两个方面:
- 硬件方面: 例如加内存、换用企业级SSD、提高带宽等操作
- 软件方面: 系统内核参数、硬盘IO以及资源分配方面的配置
1.软件层系统优化
主要从系统内核参数、CPU、IO、网络、内存这几个方面来进行优化
- 内存调优:优化系统的内存使用效率,减少内存泄漏和内存碎片等问题
- 磁盘调优:提高磁盘的读写速度和可靠性,减少数据丢失和损坏的风险
- CPU调优:优化CPU的利用率,提高系统的性能和稳定性
- 网络调优:提高网络的性能和稳定性,减少数据传输的延迟和丢失
- 进程和线程调优:优化系统的进程调度算法、减少进程和线程的竞争等,提高系统的并发性能和稳定性
2.系统优化步骤
1.使用系统监控工具、性能测试工具等,收集系统的性能数据和指标,了解系统当前的运行状态,从而识别系统的瓶颈和优化空间
2.使用追踪工具进行追踪,定位到具体的应用程序和进程
3.根据定位到的应用程序和进程进行分析,分析导致出问题的原因,从而对内存、磁盘、CPU等方面进行优化
3.系统性能的相关概念
- IOPS:Input/Output Per Second.是指每秒钟可以进行的输入/输出操作次数,是衡量存储设备性能的重要指标之一
- 吞吐量:Throughput。系统在单位时间内能够处理的事务数量
- 响应时间:Response Time。系统从接收请求到返回结果所需的时间
- 带宽:Bandwidth。数据传输的速度,通常以每秒传输的比特数(bps)或字节(Bps)来衡量
- 延时:Latency。指从请求发出到收到响应所需的时间
- 瓶颈:Bottleneck。操作系统中限制系统性能的关键因素或资源。当系统中某个组件的处理能力达到极限,无法满足其他组件的需求时,就会出现瓶颈
- 工作负载:Workload。是指计算机系统中正在运行的应用程序或任务的集合
- 缓存:cache。缓存的作用就是用来提高系统性能的一种技术
- CPU缓存::CPU缓存是一种硬件设备,通常是集成在CPU芯片中。CPU缓存分为三个级别,包括L1、L2和L3缓存,这些级别按照缓存大小和访问速度逐渐递减。用于存储CPU需要频繁访问的数据和指令,以便更快地执行计算任务。CPU缓存速度非常快,通常比内存缓存快几个数量级,因此能够大大提高计算机的运行速度
- 内存缓存:内存缓存通常是通过在系统内存中划分出一部分空间来实现的,这部分空间被称为缓存区。缓存区是由操作系统内核管理的,它在系统启动时就被分配出来,并在系统运行期间一直存在. 当应用程序需要访问内存中的数据时,内存缓存会首先检查缓存区中是否已经缓存了该数据。如果已经缓存,则可以直接从缓存区中读取数据,从而避免了从内存中读取数据的时间和能耗。如果缓存区中没有该数据,则需要从内存中读取,并将数据存储到缓存区中以供下一次访问使用
- 缓冲:Buffer。缓冲通常是在内存中分配一块空间来实现的,这些空间被称为缓冲区。缓冲区是用于临时存储数据的区域,数据在这里被暂时保存并等待被进一步处理. 如将数据从一个设备传输到另一个设备时,缓冲可以暂存数据,以防止数据在传输过程中丢失或损坏。因为如果发送方速度太快,接受方不能及时接收就会导致数据丢失
- 输入缓冲区(Input Buffer):用于存储输入设备(例如键盘、鼠标等)发送过来的数据,等待系统进一步处理
- 输出缓冲区(Output Buffer):用于存储输出设备(例如打印机、屏幕等)接受数据,等待设备进行处理
- 文件缓冲区(File Buffer):用于存储文件数据的内存区域,通过将文件数据缓存到内存中,可以减少访问磁盘的次数,提高文件读写的效率
- 磁盘缓存(Disk Cache):用于存储磁盘上的数据,通过将常用的数据缓存到内存中,可以加速磁盘访问,提高系统的性能
4.Linux资源信息的监控
通过对系统性能参数的监控和收集,了解当前系统的负载、CPU使用情况,内存使用、IO等信息
4.1 查看系统整体的信息
4.1.1 vmstat工具
vmstat是系统自带的一个工具,vmstat主要查看的是内存和进程的使用情况,其它例如进程、系统IO、上下文切换这些信息也可以查看
语法介绍:
# vmstat --help
Usage:
vmstat [options] [delay [count]]
Options:
-a, --active 显示活动和非活动内存
-f, --forks 显示自启动以来的分叉数
-m, --slabs 显示网络缓存信息
-n, --one-header 只在开始时显示一次各字段名称
-s, --stats 显示各种事件计数器和内存统计信息的表
-d, --disk 显示磁盘相关统计信息
-D, --disk-sum 详细的磁盘活动报告
-p, --partition <dev> 显示指定磁盘分区统计信息
-S, --unit <char> 使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-w, --wide 宽字节输出
-t, --timestamp 向报表添加时间戳
-h, --help 显示此帮助手册并退出
-V, --version 输出版本信息并退出
使用详解:

[root@localhost ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1328008 2108 577680 0 0 11 2 164 231 0 0 99 0 0
相关参数介绍:
-
procs:显示进程的活动情况
- r :正在运行的以及处于排队状态的线程数,这个值和进程有关系,如果值长期大于cpu的核数(lscpu查看cpu个数),说明cpu不够,任务运行的进程太多
- b :进程阻塞的数量,阻塞状态就是一只处于排队状态。这个值长期大于0就表明cpu资源严重不够了。一直轮不到给你分配cpu
-
memory:显示系统的内存使用情况
- swpd:交换分区使用了多少。0表示还没有任何使用,如果已经开始使用交换分区了,说明内存已经不够用了
- free:可用内存大小,单位为k
- buff:用作缓冲的内存大小,一般是往硬盘里面写的时候会占用这个值
- cache:用作缓存的内存大小, 单位也是k
-
swap:显示系统的交换空间使用情况
-
si:swap input:硬盘到交换分区的一个大小
-
so:swap output:从交换分区到硬盘的一个大小
说明:si和so只要大于0,说明内存有问题了。例如内存泄露、内存不够等情况
-
-
io:显示系统的磁盘I/O活动情况。
-
bi:往硬盘里面写的一个值.单位是k
-
bo:往硬盘里面读的一个值,单位是k
说明:如果系统的bi和bo值很大,说明io有问题
-
-
system:显示系统的CPU使用情况
-
in:每秒中断数,包括时钟中断
-
cs:上下文切换的数目
说明:如果系统中存在大量的上下文切换和终端,说明系统可能存在某些问题
-
us:用户进程所消耗的时间
-
sy:系统进程消耗的一个时间
-
id:系统的空闲时间
-
wa:硬盘io出现了阻塞,数据太多入口被堵死了。但是写不进去,所以就开始等待。 如果wa这个值比较大说明cpu的资源够,但是io有问题导致浪费了cpu
-
st:在虚拟化的时候会用到
-
相关使用记录
显示系统启动后创建的进程总数,查看系统已经fork了多少次
[root@localhost ~]# vmstat -f
616700 forks
显示网络缓存信息
[root@localhost ~]# vmstat -m
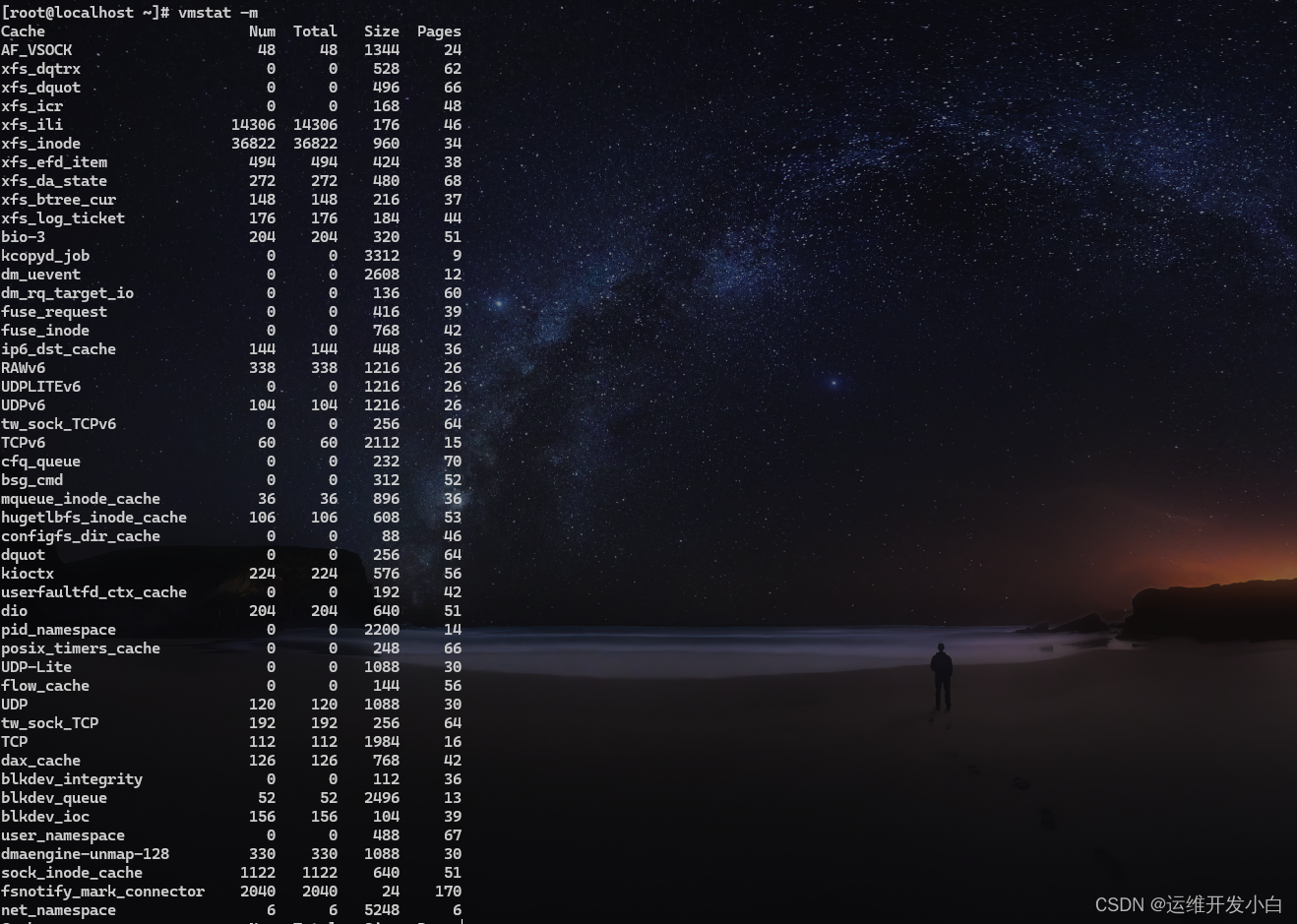
头信息仅显示一次
[root@localhost ~]# vmstat -n
以表格方式显示事件计数器和内存状态
[root@localhost ~]# vmstat -s
指定单位
[root@localhost ~]# vmstat -S M 1 2
`以1秒为间隔,执行两次查询

显示活动命令
[root@localhost ~]# vmstat -a 2 2
`以两秒为间隔,执行2次查询

查看磁盘的读写
[root@localhost ~]# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
sda 9520 50 909896 9154 3327 692 135614 2531 0 6
sdb 3959 0 135560 4526 325 221 20164 256 0 3
sr0 0 0 0 0 0 0 0 0 0 0
dm-0 8428 0 849038 8896 4008 0 131478 3089 0 6
dm-1 88 0 4408 23 0 0 0 0 0 0
**相关参数介绍:**
reads:读
total: 成功读取的总数
merged: 分组读取(产生一个 IO)
sectors: 成功读取的扇区数
ms: 读取花费的毫秒
writes:写
total: 成功写入的总数
merged: 分组写入(产生一个 IO)
sectors: 成功写入的扇区数
ms: 写花费的毫秒
IO
cur: 正在进行的IO
sec: IO花费的秒数
查看磁盘的活动报告
[root@localhost ~]# vmstat -D
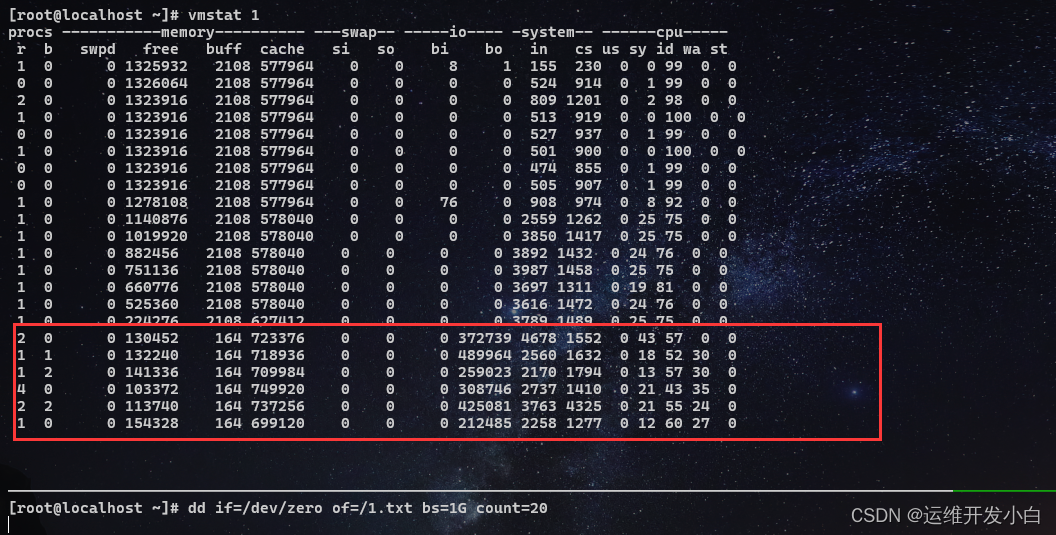
压力测试,查看磁盘情况
[root@localhost ~]# vmstat 1
`另开终端
[root@localhost ~]# dd if=/dev/zero of=/1.txt bs=1G count=20
4.1.2 mpstat工具
mpstat工具和vmstat不同点在于mpstat主要监视CPU使用情况,包括每个CPU的使用率、上下文切换、中断和软中断等信息。vmstat和mpstat 命令的差别:mpstat 可以显示每个处理器的统计,而 vmstat 显示所有处理器的统计
语法介绍:
mpstat [ options ] [ <interval> [ <count> ] ]
**Options : **
[ -A ] [ -u ] [ -V ] [ -I { SUM | CPU | SCPU | ALL } ]
[ -P { <cpu> [,...] | ON | ALL } ]
-A:此选项等效于指定 -u -I ALL -P ALL
-I { SUM | CPU | SCPU | ALL }:报告中断统计
SUM:表示每个处理器的中断总数
CPU:显示 CPU 每秒接收的每个单独中断的数量
SCPU:表示每个核每秒的软中断数量,内核版本在2.6.31之后才支持
ALL:ALL 关键字等同于指定以上所有关键字,因此显示所有中断统计信息
-P { cpu [,...] | ON | ALL }
cpu:指示要报告其统计信息的处理器编号。 cpu 是处理器编号。 请注意,处理器 0 是第一个处理器
ON:表示要为每个在线处理器报告统计信息
ALL:表示要为所有处理器报告统计信息
-u:显示 CPU 利用率
-V:打印版本号并退出
interval:每次采样的间隔时间
count:采样次数
# 当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
使用详解:

```mpstat的安装部署
# 对于基于 Debian 的系统(如 Ubuntu)
apt-get update
apt-get install sysstat
# 对于基于 Red Hat 的系统(如 CentOS)
yum install sysstat
[root@localhost ~]# mpstat
Linux 3.10.0-1160.108.1.el7.x86_64 (localhost) 2024年03月04日 _x86_64_ (4 CPU)
14时15分16秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
14时15分16秒 all 0.13 0.00 0.44 0.01 0.00 0.02 0.00 0.00 0.00 99.41
[root@localhost ~]# mpstat -P ALL 3 # 每 3 秒的间隔显示所有 CPU 核心的使用率和统计信息
相关参数介绍:
-
CPU:显示每个CPU的编号,all表示所有的CPU
-
%usr:显示用户空间进程使用CPU的百分比
说明:如果%usr较高,表示用户空间进程占用了大量CPU资源,可能是某个进程出现了问题或者某个进程需要更多的CPU资源
-
%nice:显示优先级较低的用户空间进程使用CPU的百分比
-
%sys:显示内核空间进程使用CPU的百分比
说明:如果%sys较高,表示内核空间进程占用了大量CPU资源,可能是某个内核模块出现了问题或者某个进程在等待内核资源
-
%iowait:显示CPU等待I/O完成的百分比
说明:如果%iowait较高,表示CPU正在等待I/O操作完成,可能是磁盘、网络或其他I/O设备出现了瓶颈
-
%irq:显示CPU处理硬件中断的百分比
说明:如果%irq较高,表示CPU正在处理大量硬件中断,可能是某个硬件设备出现了问题
-
%soft:显示CPU处理软件中断的百分比
说明:如果%soft较高,表示CPU正在处理大量软件中断,可能是某个进程出现了问题或者某个内核模块在处理大量请求
-
%steal:显示被虚拟机偷走的CPU时间的百分比
-
%guest:显示虚拟机使用CPU的百分比
-
%idle:显示CPU空闲的百分比
说明:如果%idle较低,表示CPU正在忙碌,可能是系统负载过高或者某个进程占用了大量CPU资源
// 监控全部CPU
[root@localhost ~]# mpstat -P ALL

// 每隔2s输出一次,输出3次
[root@localhost ~]# mpstat 2 3

// 监控2号CPU
[root@localhost ~]# mpstat -P 2

// 查看CPU每秒钟接收每个中断的次数
[root@localhost ~]# mpstat -I CPU
// 查看CPU中断的统计
[root@localhost ~]# mpstat -I SUM
// 查看所有CPU中断的统计
[root@localhost ~]# mpstat -P ALL -I SUM
4.1.3 iostat工具
iostat主要监视磁盘I/O使用情况,包括每个磁盘的读写速度、I/O等待时间、I/O请求队列长度等,主要使用iostat工具来了解系统磁盘I/O使用情况,识别磁盘I/O瓶颈和瓶颈进程
语法介绍:
[root@localhost ~]# iostat --help
用法: iostat [ 选项 ] [ <时间间隔> [ <次数> ] ]
选项:
[ -c ] [ -d ] [ -h ] [ -k | -m ] [ -N ] [ -t ] [ -V ] [ -x ] [ -y ] [ -z ]
[ -j { ID | LABEL | PATH | UUID | ... } ]
[ [ -T ] -g <用户组名> ] [ -p [ <设备> [,...] | ALL ] ]
[ <设备> [...] | ALL ]
** 选项 **
-c: 仅显示CPU利用率相关信息
-d: 仅显示磁盘I/O相关信息
-k: 显示输出的数据单位为KB/s而不是默认的字节/s
-t: 在输出中显示时间戳(时间戳格式YYYY-MM-DD HH:MM:SS)
-m:显示状态以兆字节每秒为单位
-p:仅显示块设备和所有被使用的其他分区的状态
-V:显示版号并退出
-x:显示扩展状态
使用详解:

[root@localhost ~]# iostat
Linux 3.10.0-1160.108.1.el7.x86_64 (localhost) 2024年03月04日 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.12 0.00 0.45 0.01 0.00 99.42
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.97 34.93 5.13 454940 66831
sdb 0.33 5.20 0.77 67780 10082
dm-0 0.94 32.59 4.97 424511 64763
dm-1 0.01 0.17 0.00 2204 0
相关使用记录
间隔5秒查看3次信息
[root@localhost ~]# iostat 5 3
只查看磁盘状态,展示磁盘的读写速率、I/O等待时间、CPU使用率等信息
[root@localhost ~]# iostat -d
Linux 3.10.0-1160.108.1.el7.x86_64 (localhost) 2024年03月04日 _x86_64_ (4 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 2.62 31.59 484.57 554076 8500194
sdb 0.27 4.10 0.60 71920 10599
dm-0 2.72 29.84 484.45 523535 8498089
dm-1 0.01 0.13 0.00 2204 0
实时监控,每隔5秒就显示磁盘信息
[root@localhost ~]# iostat -d 5
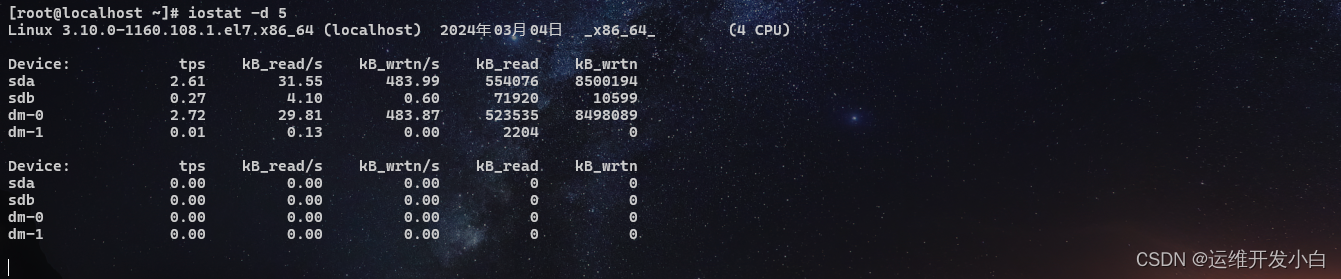
以k或M为单位显示信息
[root@localhost ~]# iostat -k
[root@localhost ~]# iostat -m
查看某块磁盘I/O的详细情况
[root@localhost ~]# iostat -x /dev/sda
** 相关参数介绍 **
Device 监测设备名称
rrqm/s 每秒需要读取需求的数量
wrqm/s 每秒需要写入需求的数量
r/s 每秒实际读取需求的数量
w/s 每秒实际写入需求的数量
rsec/s 每秒读取区段的数量
wsec/s 每秒写入区段的数量
rkB/s 每秒实际读取的大小,单位为KB
wkB/s 每秒实际写入的大小,单位为KB
avgrq-sz 需求的平均大小区段
avgqu-sz 需求的平均队列长度
await 等待I/O平均的时间(milliseconds)
svctm I/O需求完成的平均时间
%util 被I/O需求消耗的CPU百分比
查看CPU状态信息
[root@localhost ~]# iostat -c 5 2 # 每隔5秒查询一次,一共两次
** 相关参数介绍 **
%user:表示用户空间程序执行的CPU时间百分比
%nice:表示以较高的优先级运行的用户进程的CPU时间百分比
%system:表示内核空间程序执行的CPU时间百分比
%iowait:表示CPU等待I/O操作完成的时间百分比
%steal:表示由于运行虚拟机等原因被其他虚拟机占用的CPU时间百分比
%idle:表示CPU空闲时间的百分比

总结:
- 磁盘模块分析
在使用IOStat进行系统性能监控时,需要注意综合分析磁盘和CPU等多个性能指标,以全面评估系统性能瓶颈的位置和原因。通过监控以上指标,可以识别磁盘的瓶颈位置,例如:- 如果r/s和w/s较高,说明磁盘IO压力较大,需要考虑更换更高性能的硬盘
- 如果await和svctm较高,说明磁盘处理I/O请求的能力不足,可能需要更换磁盘控制器或升级磁盘阵列等
- CPU模块分析
通过监控以上指标,可以识别CPU的瓶颈位置,例如- 如果%user和%system较高,说明CPU的负载较大,可能需要考虑升级CPU或增加CPU核心数
- 如果%iowait较高,说明CPU等待IO完成的时间较长,可能需要优化磁盘性能或者减少磁盘IO操作
- 如果%idle值高,表示CPU较空闲,系统处于空闲状态,无太多处理任务
- 如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
- 如果%idle较低,说明CPU负载较大,可能需要考虑优化应用程序或增加CPU资源等
4.1.4 sar工具
相比于vmstat和mpmstat,sar工具提供了更全面的系统性能监控和历史数据分析功能。可以将输出的信息重定向到一个文件里面,便于后续的分析
语法介绍:
用法: sar [ 选项 ] [ <时间间隔> [ <次数> ] ]
主选项和报告:
-b I/O 和传输速率信息状况
-B 分页状况
-d 块设备状况
-I { <中断> | SUM | ALL | XALL }
中断信息状况
-m 电源管理信息状况
-n { <关键词> [,...] | ALL }
网络统计信息
关键词可以是:
DEV 网卡
EDEV 网卡 (错误)
NFS NFS 客户端
NFSD NFS 服务器
SOCK Sockets (套接字) (v4)
IP IP 流 (v4)
EIP IP 流 (v4) (错误)
ICMP ICMP 流 (v4)
EICMP ICMP 流 (v4) (错误)
TCP TCP 流 (v4)
ETCP TCP 流 (v4) (错误)
UDP UDP 流 (v4)
SOCK6 Sockets (套接字) (v6)
IP6 IP 流 (v6)
EIP6 IP 流 (v6) (错误)
ICMP6 ICMP 流 (v6)
EICMP6 ICMP 流 (v6) (错误)
UDP6 UDP 流 (v6)
-q 队列长度和平均负载
-r 内存利用率
-R 内存状况
-S 交换空间利用率
-u [ ALL ]
CPU 利用率
-v Kernel table 状况
-w 任务创建与系统转换统计信息
-W 交换信息
-y TTY 设备状况
-o {<文件路径>}
将命令结果以二进制格式存放在指定文件中
查看CPU的使用情况
[root@localhost ~]# sar -u 1 3

相关参数说明:
-
%user:用户空间进程所占用CPU时间的百分比
-
%nice:被nice值提高的用户空间进程所占用CPU时间的百分比
-
%system:内核空间进程所占用CPU时间的百分比
如果%user和%system占用率较高,可能表示系统负载较高,需要进一步检查进程、IO等情况
-
%iowait:CPU等待I/O操作完成所占用CPU时间的百分比
如果%iowait占用率较高,可能表示IO瓶颈
-
%steal:被虚拟化程序(如VMware)偷走的CPU时间的百分比
-
%idle:CPU空闲时间的百分比
如果%idle占用率较高,可能表示系统资源未充分利用
监视内存使用情况
[root@localhost ~]# sar -r 1 3

相关参数说明:
-
kbmemfree:可用内存大小(单位:KB)
-
kbmemused:已用内存大小(单位:KB)
-
%memused:已用内存占总内存的百分比
如果可用内存(kbmemfree)较少,已用内存(kbmemused)和已用内存占总内存的百分比(%memused)较高,可能表示内存不足
-
kbbuffers:缓存的内存大小(单位:KB)
-
kbcached:缓存的文件系统缓存大小(单位:KB)
如果缓存的内存(kbbuffers)和缓存的文件系统缓存(kbcached)较高,可能表示系统的文件系统缓存良好
-
kbcommit:提交内存大小(单位:KB)
-
%commit:提交内存占总内存的百分比
如果提交内存(kbcommit)较高,可能表示应用程序提交的内存较多
-
kbactive:活跃内存大小(单位:KB)
-
kbinact:非活跃内存大小(单位:KB)
如果活跃内存(kbactive)和非活跃内存(kbinact)较高,可能表示系统当前运行的应用程序较多
-
kbdirty:脏页的内存大小(单位:KB)
监视磁盘I/O使用情况
[root@localhost ~]# sar -b 1 3

相关参数说明:
-
tps:每秒传输的I/O请求数(包括读写请求)
如果tps较高,可能表示磁盘I/O瓶颈
-
rtps:每秒读请求传输的I/O请求数
-
wtps:每秒写请求传输的I/O请求数
如果rtps或wtps较高,可以进一步确认是读操作或写操作的问题
-
bread/s:每秒读取的数据块数量(单位:512字节)
-
bwrtn/s:每秒写入的数据块数量(单位:512字节)
如果bread/s或bwrtn/s较高,可能表示磁盘I/O吞吐量不足
查看网络的基本信息DEV
主要查看的是接收和发送数据包的速率、接收和发送数据量的速率
[root@localhost ~]# sar -n DEV 2 3
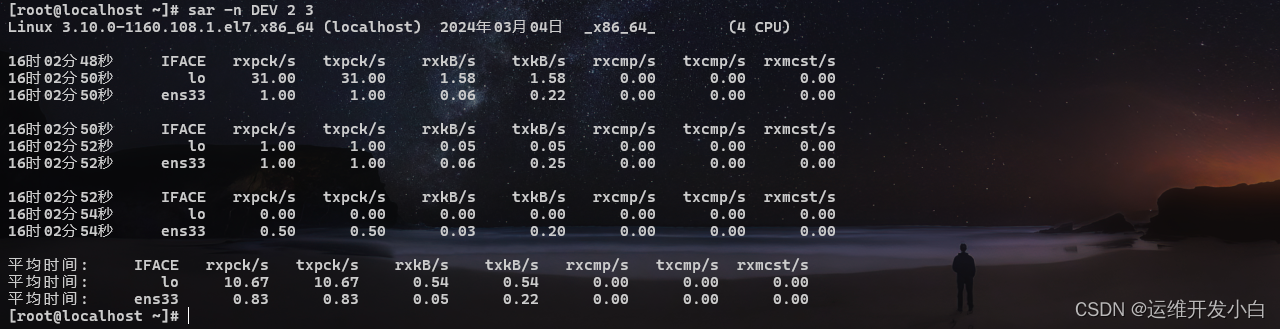
相关参数说明:
-
IFACE:网络接口名称
-
rxpck/s:每秒接收的数据包数量
-
txpck/s:每秒发送的数据包数量
-
rxkB/s:每秒接收的数据量(KB)
-
txkB/s:每秒发送的数据量(KB)
如果rxkB/s和txkB/s非常高,但%ifutil非常低,则可能存在网络拥塞的问题
-
rxcmp/s:每秒接收的压缩数据包数量
-
txcmp/s:每秒发送的压缩数据包数量
如果rxcmp/s和txcmp/s非常高,可能存在数据压缩的问题
-
rxmcst/s:每秒接收的多播数据包数量
如果rxmcst/s非常高,可能存在多播网络流量的问题
数据压缩:为了减少数据的传输量,可以对数据进行压缩。压缩的过程是将原始数据使用某种压缩算法进行编码,使其占用更少的带宽
查看网络的错误信息EDEV
可以查看网络设备的错误和丢包数
[root@localhost ~]# sar -n EDEV 1 1

相关参数说明:
-
rxerr/s:每秒接收的错误数
-
txerr/s:每秒发送的错误数
-
coll/s:每秒发生的冲突数
coll/s的值很高,可能存在网络中的冲突问题,例如网络中存在多个设备尝试同时发送数据包
-
rxdrop/s:每秒接收的丢包数
rxerr/s或rxdrop/s的值很高,可能存在网络中的接收问题,例如硬件故障或网络拥塞等
-
txdrop/s:每秒发送的丢包数
txerr/s或txdrop/s的值很高,可能存在网络中的发送问题,例如硬件故障或网络拥塞
-
txcarr/s:每秒发生的载波错误数
-
rxfram/s:每秒接收的帧错误数
-
rxfifo/s:每秒钟由于接收FIFO队列溢出而丢失的数据包数
-
txfifo/s:每秒钟由于发送FIFO队列溢出而丢失的数据包数
4.2 查看某个进程的资源占用信息
4.2.1 top工具
top命令可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理
语法介绍
top(选项)
**选项**
-b:以批处理模式操作;
-c:显示完整的命令;
-d:屏幕刷新间隔时间;
-I:忽略失效过程;
-s:保密模式;
-S:累积模式;
-i<时间>:设置间隔时间;
-u<用户名>:指定用户名;
-p<进程号>:指定进程;
-n<次数>:循环显示的次数。
top交互命令
在top命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了-s选项, 其中一些命令可能会被屏蔽
h:显示帮助画面,给出一些简短的命令总结说明;
k:终止一个进程;
i:忽略闲置和僵死进程,这是一个开关式命令;
q:退出程序;
r:重新安排一个进程的优先级别;
S:切换到累计模式;
s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
f或者F:从当前显示中添加或者删除项目;
o或者O:改变显示项目的顺序;
l:切换显示平均负载和启动时间信息;
m:切换显示内存信息;
t:切换显示进程和CPU状态信息;
c:切换显示命令名称和完整命令行;
M:根据驻留内存大小进行排序;
P:根据CPU使用百分比大小进行排序;
T:根据时间/累计时间进行排序;
w:将当前设置写入~/.toprc文件中。
top命令说明
[root@localhost ~]# top
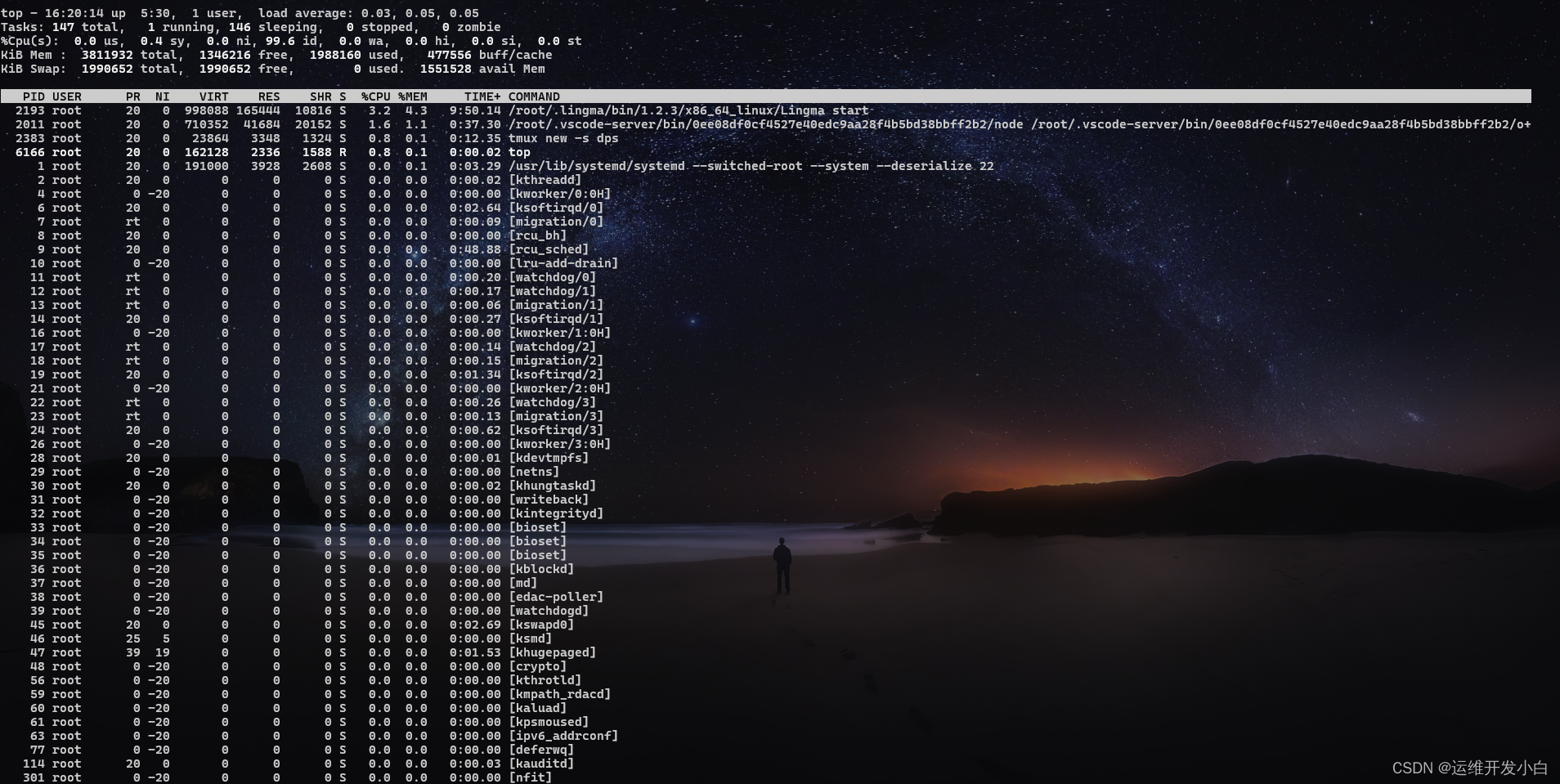
top命令的结果分为两个部分:
-
统计信息:前五行是系统整体的统计信息;
-
统计信息说明:
- 第1行:Top 任务队列信息(系统运行状态及平均负载),与uptime命令结果相同。
- 第1段:系统当前时间,例如:16:07:37
- 第2段:系统运行时间,未重启的时间,时间越长系统越稳定. 格式:up xx days, HH:MM .例如:241 days, 20:11, 表示连续运行了241天20小时11分钟
- 第3段:当前登录用户数,例如:1 user,表示当前只有1个用户登录
- 第4段:系统负载,即任务队列的平均长度,3个数值分别统计最近1,5,15分钟的系统平均负载 . 系统平均负载:单核CPU情况下,0.00 表示没有任何负荷,1.00表示刚好满负荷,超过1侧表示超负荷,理想值是0.7;多核CPU负载:CPU核数 * 理想值0.7 = 理想负荷,例如:4核CPU负载不超过2.8何表示没有出现高负载
- 第2行:Tasks 进程相关信息
- 第1段:进程总数,例如:Tasks: 231 total, 表示总共运行231个进程
- 第2段:正在运行的进程数,例如:1 running,
- 第3段:睡眠的进程数,例如:230 sleeping,
- 第4段:停止的进程数,例如:0 stopped,
- 第5段:僵尸进程数,例如:0 zombie
- 第3行:Cpus CPU相关信息,如果是多核CPU,按数字1可显示各核CPU信息,此时1行将转为Cpu核数行,数字1可以来回切换。
- 第1段:us 用户空间占用CPU百分比,例如:Cpu(s): 12.7%us,
- 第2段:sy 内核空间占用CPU百分比,例如:8.4%sy,
- 第3段:ni 用户进程空间内改变过优先级的进程占用CPU百分比,例如:0.0%ni,
- 第4段:id 空闲CPU百分比,例如:77.1%id,
- 第5段:wa 等待输入输出的CPU时间百分比,例如:0.0%wa,
- 第6段:hi CPU服务于硬件中断所耗费的时间总额,例如:0.0%hi,
- 第7段:si CPU服务软中断所耗费的时间总额,例如:1.8%si,
- 第8段:st Steal time 虚拟机被hypervisor偷去的CPU时间(如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)
- 第4行:Mem 内存相关信息(Mem: 12196436k total, 12056552k used, 139884k free, 64564k buffers)
- 第1段:物理内存总量,例如:Mem: 12196436k total,
- 第2段:使用的物理内存总量,例如:12056552k used,
- 第3段:空闲内存总量,例如:Mem: 139884k free,
- 第4段:用作内核缓存的内存量,例如:64564k buffers
- 第5行:Swap 交换分区相关信息(Swap: 2097144k total, 151016k used, 1946128k free, 3120236k cached)
- 第1段:交换区总量,例如:Swap: 2097144k total,
- 第2段:使用的交换区总量,例如:151016k used,
- 第3段:空闲交换区总量,例如:1946128k free,
- 第4段:缓冲的交换区总量,3120236k cached
- 第1行:Top 任务队列信息(系统运行状态及平均负载),与uptime命令结果相同。
-
进程信息:统计信息下方类似表格区域显示的是各个进程的详细信息,默认5秒刷新一次。在top命令中按f按可以查看显示的列信息,按对应字母来开启/关闭列,大写字母表示开启,小写字母表示关闭。带*号的是默认列。
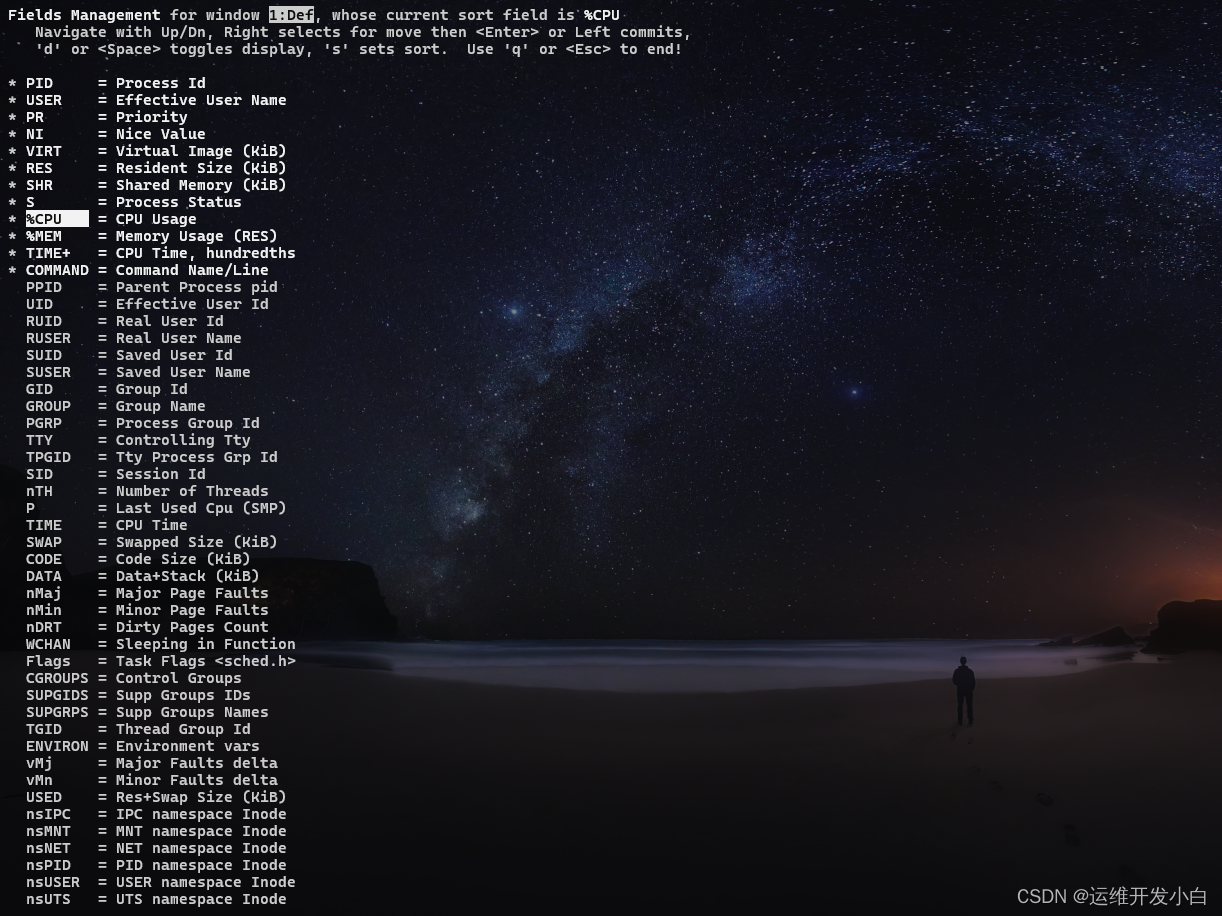
- PID = (Process Id) 进程Id;
- USER = (User Name) 进程所有者的用户名;
- PR = (Priority) 优先级
- NI = (Nice value) nice值。负值表示高优先级,正值表示低优先级
- VIRT = (Virtual Image (kb)) 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES = (Resident size (kb)) 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR = (Shared Mem size (kb)) 共享内存大小,单位kb
- S = (Process Status) 进程状态。D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程
- %CPU = (CPU usage) 上次更新到现在的CPU时间占用百分比
- %MEM = (Memory usage (RES)) 进程使用的物理内存百分比
- TIME+ = (CPU Time, hundredths) 进程使用的CPU时间总计,单位1/100秒
- PPID = (Parent Process Pid) 父进程Id
- RUSER = (Real user name)
- UID = (User Id) 进程所有者的用户id
- GROUP = (Group Name) 进程所有者的组名
- TTY = (Controlling Tty) 启动进程的终端名。不是从终端启动的进程则显示为 ?
- P = (Last used cpu (SMP)) 最后使用的CPU,仅在多CPU环境下有意义
- SWAP = (Swapped size (kb)) 进程使用的虚拟内存中,被换出的大小,单位kb
- TIME = (CPU Time) 进程使用的CPU时间总计,单位秒
- CODE = (Code size (kb)) 可执行代码占用的物理内存大小,单位kb
- DATA = (Data+Stack size (kb)) 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
- nFLT = (Page Fault count) 页面错误次数
- nDRT = (Dirty Pages count) 最后一次写入到现在,被修改过的页面数
- WCHAN = (Sleeping in Function) 若该进程在睡眠,则显示睡眠中的系统函数名
- Flags = (Task Flags <sched.h>) 任务标志,参考 sched.h
- COMMAND = (Command name/line) 命令名/命令行
4.2.2 ps 工具
ps 命令是 Linux 系统中常用的进程查看工具,它可以查看当前系统中正在运行的进程信息。ps 命令可以显示进程的 ID、状态、执行命令、占用内存等信息,对于系统管理员来说,使用 ps 命令可以方便地监控和管理系统中的进程
ps 命令语法及选项
ps [选项]
** 选项 **
-a 显示所有进程,包括其他用户的进程
-u 显示进程的详细信息
-x 显示没有控制终端的进程
-e 显示系统中所有的进程
-f 显示进程的完整格式,包括进程的命令行参数
-l 显示进程的详细信息,包括进程的状态、资源占用等
-h 隐藏标题行
举例说明
使用 ps 命令可以查看当前用户的所有进程,命令如下:
[root@localhost ~]# ps
该命令会显示当前用户的所有进程信息,如下所示:

在输出结果中,第一列是进程的 ID (PID),第二列是进程所在的控制终端 (TTY),第三列是进程运行的时间 (TIME),第四列是进程的命令 (CMD)
…
5.系统调优方法
5.1 操作系统基本概念说明:
操作系统:
操作系统是一个系统软件,操作系统的作用是管理和控制计算机硬件
内核:
内核是操作系统的核心部分,是操作系统管理计算机硬件和软件资源的核心代码。操作系统则由内核和其他系统工具程序共同组成的。例如文件管理器、用户界面、设备驱动程序等
程序:
指的是一组计算机指令和数据,可以被计算机执行。程序是静态的,通常存储在硬盘或其他存储设备中,需要通过操作系统加载到内存中才能运行
进程:
是计算机中正在运行的程序的实例。进程是操作系统中进行资源分配的基本单位
线程:
是进程中的一个执行单元,是操作系统调度的最小单位
内核空间:
内核空间是操作系统的核心部分,是操作系统内核运行的地址空间。内核空间是操作系统独占的,只有内核才能访问这个地址空间
用户空间:
是程序运行的地址空间。用户空间是操作系统分配给应用程序的地址空间,应用程序可以在这个空间中运行和使用系统资源
进程和程序的关系:
首先程序被加载到内存中,没有开始运行的时候,只是一组静态的代码和数据。当程序被操作系统调用并开始执行时,就成为了一个进程。一个进程里面包含了程序代码、数据、寄存器等系统资源,所以每个进程都是一个程序的实体,进程是操作系统中进行资源分配和调度的基本单位
两个虚拟文件系统:
在Linux中,/sys和/proc是两个不同的虚拟文件系统,里面的信息都是动态生成的,因为这两个目录中的数据信息随着系统状态的变化而变化。这两个文件提供了操作内核数据的接口。
-
/proc文件系统:主要用于展示进程相关的信息,例如可以查询内核状态和进程信息,例如CPU、内存、网络、硬件等系统信息
-
/sys文件系统:则用于展示设备和内核参数的信息。/sys中不包含进程的信息,只有系统的状态和设备信息
说明:
修改了/proc/sys中的参数后可以通过sysctl工具来实现持久化配置
修改了/sys 中的信息不能使用sysctl工具来持久化配置,需要写入到/etc/rc.locl这个文件中实现持久化配置
例如:echo deadline > /sys/block/sda/queue/scheduler就需要放到/etc/rc.locl中
5.2 PAM和Cgroup限制资源
PAM:
PAM是一个独立的动态共享库,其功能是提供身份验证、授权和帐户管理等功能。LInux内核只提供了基本的身份验证和访问控制功能,PAM模块扩展了身份验证和访问控制的功能,可以通过配置PAM模块来实现用户身份验证和访问控制。
在Linux PAM中,每个模块可以设置两个限制:软限制和硬限制,用于控制用户对系统资源的访问。
-
软限制:超过了限制的值会发送警告信息
-
硬限制:超过了限制的值会直接拒绝
Cgroup模块:
Control group。是 Linux 内核中的一个机制,可以用于限制进程的资源使用(例如 CPU、内存、磁盘 I/O 等)和优先级分配,以实现资源隔离和性能优化。Cgroup 模块是 Linux 系统中的一个内核模块,提供了对 Cgroup 机制的支持
5.3 CPU的优化方法
1.设置CPU的亲和性
使用场景:
系统中的CPU资源较为紧张,或者应用程序的负载不均衡,可以考虑使用CPU亲和性设置来优化CPU资源的利用
实现方法:
通过taskset命令进行设置CPU的亲和性,该命令可以将进程或线程绑定到指定的CPU核心上,以提高程序的性能和可靠性。
例如,以下命令将进程ID为1234的进程绑定到CPU核心0和1上:
taskset -c 0,1 -p 1234
2.调整CPU的调度策略
默认的CFS策略已经能够满足日常需求,如果在某些特定的情况下可以改变调度策略来进行优化,例如高负载、需要实时响应等场景。
实现方法:
需要编译内核加上对应的驱动程序,风险极大
3.调整时间片大小
场景:
如果应用程序需要更快的响应时间,可以考虑减小时间片大小。
实现方法:
需要编译内核启用对cpu时间片大小修改的支持,风险极大。
缺点:
会增加系统的开销,可能会降低系统的整体性能,因为需要增加系统上下文的切换次数
4.调整CPU的迁移开销
场景:
通过CPU迁移开销的调整,可以提高系统的负载均衡和响应速度
实现方法:
也是需要编译内核加上对应的驱动程序才可以,通过修改对应的值来调整CPU的迁移开销。修改内核风险极大。
缺点:
减小CPU迁移开销可能会导致更频繁的CPU迁移,从而增加系统的开销和延迟,导致进程的局部性和缓存效率下降,从而降低系统的整体性能
5.4 内存的优化方法
1.优化对swap分区的使用
swap分区是一块硬盘空间,用于存放内存中不常用的数据。在Linux系统中,合理设置swap分区的大小可以有效地提高系统的稳定性和性能。因为swap分区的速度太慢,一般都是直接关闭swap分区的使用.
关闭swap分区的方法:
# swapoff -a # 临时关闭
# 使用命令 `sed -i '/swap/d' /etc/fstab` 来永久关闭Swap分区。这会从`/etc/fstab`文件中删除所有关于Swap分区的挂载信息
2.调整虚拟内存参数
如果一定要使用swap分区,可以通过调整/proc/sys/vm/swappiness的值为0来确保尽量使用物理内存
# 1. 修改内核参数
# vim /etc/sysctl.conf
vm.swappiness = 60
# 2. 生效
# sysctl -p
3.调整脏页的最大内存量
在操作系统的上下文中,“脏页”(dirty page)指的是那些被修改过但尚未写回到磁盘的内存页面。当操作系统使用页式内存管理时,会将物理内存划分为固定大小的页面,并且这些页面会被映射到进程的虚拟地址空间。当页面内容被修改时,它就被标记为"脏",意味着它需要被写回到磁盘以确保数据的持久性。
操作系统通常会使用一种称为"写回缓存"或"延迟写"的策略,将脏页保留在内存中,直到某个时间点再将它们写回到磁盘。这可以提高性能,因为磁盘I/O操作通常比内存访问要慢得多。然而,如果脏页数量过多,可能会消耗大量的内存,甚至导致内存不足的问题。
要调整操作系统中脏页的最大内存量,通常涉及到调整虚拟内存子系统的参数
在Linux中,你可以通过调整vm.dirty_ratio和vm.dirty_background_ratio来控制脏页的数量。这些参数定义了相对于总内存量的脏页百分比。
vm.dirty_ratio:当脏页的数量达到这个百分比时,系统将开始将脏页写回到磁盘,即使它们还没有被后台写回进程选中vm.dirty_background_ratio:当脏页的数量达到这个百分比时,后台写回进程开始将脏页写回到磁盘
可以通过编辑/etc/sysctl.conf文件或运行sysctl命令来修改这些参数。例如:
# sysctl vm.dirty_ratio=20
# sysctl vm.dirty_background_ratio=10
# sysctl vm.dirty_bytes=1073741824 将脏页的内存量调整到1G
4.使用内存缓存
tmpfs:tmpfs是一种基于内存的文件系统,tmpfs中的数据不需要将数据写入硬盘,因此可以获得更快的文件读写速度
# 1. 创建挂载点
mkdir /mnt/cache
# 2. 挂载tmpfs文件系统
mount -t tmpfs -o size=2G tmpfs /mnt/cache
# 3. 将需要进行缓存的文件或目录复制到挂载点目录下
cp -r /path/to/files /mnt/cache
# 4. 应用程序或脚本中的文件路径修改为挂载点目录下的路径
# 5. 当文件读取或写入完成后,可以通过rsync
等工具将缓存中的文件同步到硬盘上,从而避免数据的丢失。
rsync -a /mnt/cache/ /path/to/files/
内存缓存适用的场景:
- Web服务器:在Web服务器中,通常会缓存静态文件(如CSS、JavaScript、图片等),以提高网站的性能和响应速度。使用tmpfs作为内存缓存,可以将这些静态文件缓存到内存中,提高数据读取速度,减轻磁盘负载
- 数据库服务器:在数据库服务器中,经常需要将一些数据放在内存中进行缓存,以提高查询性能。使用tmpfs作为内存缓存,可以将这些数据缓存到内存中,避免频繁的磁盘IO操作,提高查询性能
- 虚拟机:在虚拟机环境中,可以使用tmpfs作为内存缓存,以提高虚拟机的磁盘IO性能。例如,可以将虚拟机的磁盘镜像文件(如vmdk、qcow2等)缓存到tmpfs中,避免频繁的磁盘IO操作
5.配置大页
配置大页(HugePages)是操作系统内存管理的一种优化手段,它允许操作系统使用比标准页面(通常为4KB)更大的内存页面,通常是2MB或更大。使用大页可以减少页表的大小,提高页表缓存的效率,从而可能提高系统性能。
要配置大页,你需要进行以下步骤:
-
检查硬件和内核支持:首先,确保你的硬件和操作系统内核支持大页。不是所有的硬件和内核版本都支持大页,所以你需要确认你的系统具备这个功能。
-
计算需要的大页数量:根据你的应用程序和工作负载,确定需要配置多少大页。通常,这涉及到评估你的应用程序的内存使用情况和性能需求。
-
配置内核参数:在Linux系统中,你可以通过修改内核启动参数来配置大页。这些参数包括
hugepages,hugepagesz, 和default_hugepagesz。例如,要在启动时分配128个2MB的大页,你可以在GRUB配置文件中设置如下参数:bash复制代码 hugepagesz=2M hugepages=128 default_hugepagesz=2M对于1GB的大页,参数将如下所示:
bash复制代码 hugepagesz=1G hugepages=N default_hugepagesz=1G其中
N是你想要分配的大页数量。请注意,配置1GB的大页需要CPU和内核都支持pdpe1gb特性。 -
重新编译内核(如果需要):如果你的系统内核不支持大页或者不支持你想要的大页大小,你可能需要重新编译内核并启用相应的选项。
-
重启系统:在修改GRUB配置文件后,你需要重启系统以使更改生效。
-
验证配置:重启后,你可以使用
free -m -h命令来查看大页的使用情况。你应该能看到类似于HugePages_Total和HugePages_Free的字段,它们显示了系统配置的总大页数量和当前空闲的大页数量。 -
调整应用程序:最后,你需要确保你的应用程序能够使用大页。这通常涉及到修改应用程序的配置文件或代码,以便它请求使用大页内存。
请注意,配置大页是一个高级优化手段,通常只在特定的应用场景下才会使用。在大多数情况下,标准页面的管理已经足够好,而且大页的配置和使用相对复杂。因此,在决定使用大页之前,请确保你了解它的工作原理,并已经评估了它对你的系统性能的实际影响
6.脏数据的回收
脏数据就是对内存中已被修改但尚未写入磁盘的数据进行回收.
脏数据自动回收:通过修改vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值来调整脏数据回收的时间间隔
[root@localhost ~]# cat /proc/sys/vm/dirty_expire_centisecs # 脏数据在内存中存留的时间,单位秒
3000
[root@localhost ~]# cat /proc/sys/vm/dirty_writeback_centisecs
脏数据手动回收:
使用sync命令将内存中的所有脏数据写回磁盘,以减少数据丢失或损坏的风险。sync命令会强制将文件系统中所有修改过的数据缓存写回磁盘,包括脏数据和元数据
sync 命令是 Unix 和类 Unix 系统(包括 Linux)中的一个常用命令,用于将内存中的脏页(即已修改但尚未写入磁盘的数据)强制写回磁盘。这通常用于确保数据的一致性和完整性,特别是在系统关机或重启之前。
当你在 Linux 系统中执行 sync 命令时,系统会尝试将所有挂起的写操作(即那些已经写入缓冲区但还没有实际写入磁盘的数据)发送到磁盘。这样可以确保在系统突然断电或崩溃时,尽可能多的数据被保存下来,从而减少数据丢失或损坏的风险。
执行 sync 命令很简单,只需在终端或命令行界面中输入 sync 并按回车即可
如何调整脏数据回收的时间:
如果追求系统的性能,可以把vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值改大,减少磁盘IO的操做。
如果追求数据的安全性,可以把vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值改小,防止数据丢失。
7.清理缓存
只有在应用程序出现崩溃或无响应的情况,系统出现“内存不足”或“无法为应用程序分配足够的内存”中各种情况可以考虑清理缓存,以确保系统的正常运行。
注意:清空缓存可能会导致系统性能下降,因为需要重新从磁盘读取数据。因此,在清空缓存之前,需要仔细考虑清空缓存的必要性,并确保系统有足够的内存来重新缓存数据。
例如:free非常小,而available比较大,说明系统正在使用大量的缓存来提高性能,并且这些缓存可以被重新分配给新的进程或应用程序,这种情况清理缓存会影响性能。
清空内存缓存(Linux)
在Linux系统中,你可以使用sync和echo命令来清空内存缓存。sync命令将所有挂起的文件系统写入磁盘,而echo命令则用于将缓存清空
-
清空页缓存(Page Cache)
sync; echo 1 > /proc/sys/vm/drop_caches -
清空目录项和inode缓存(dentries and inodes)
sync; echo 2 > /proc/sys/vm/drop_caches -
清空所有缓存(Page Cache, dentries and inodes):
sync; echo 3 > /proc/sys/vm/drop_caches
清空文件系统缓存(Linux)
在Linux中,文件系统缓存通常指的是页缓存(Page Cache)。你可以使用上面的方法来清空页缓存。此外,你还可以使用clear_cache命令来清空某个挂载点的缓存
echo 3 > /proc/sys/vm/drop_caches # 清空所有缓存
或者,对于特定的挂载点,你可以使用clear_cache命令:
echo 1 > /proc/sys/vm/local_fs_cache
sync
echo 2 > /proc/sys/vm/local_fs_cache
5.5 磁盘的优化方法
1.挂载参数优化
在挂载硬盘时,使用noatime选项可以避免在每次读取文件时更新文件的访问时间,减少磁盘IO操作,提高硬盘性能。在/etc/fstab文件中添加noatime选项即可
2.选择合适的文件系统
对于大量小文件的读写,使用 ext4 文件系统可能比使用 XFS 文件系统更适合
3.根据不同的场景选择磁盘调度算法
在Linux系统中,磁盘的三种调度算法分别为 CFQ、Deadline 和 NOOP
-
CFQ调度算法
Linux系统默认的磁盘调度算法,会根据每个进程的优先级和历史I/O请求时间来计算每个队列的权重,然后按照权重顺序调度I/O请求。
使用场景: 适合多任务环境下的桌面系统和服务器系统。例如Web服务器、数据库服务器
修改CFQ调度器通常涉及调整内核参数以改变其行为。例如,可以修改
/sys/block/<device>/queue/iosched文件来选择不同的调度器,其中<device>是设备名称(如sda)。要将调度器更改为CFQ,可以执行以下命令:bash复制代码 echo cfq > /sys/block/sda/queue/iosched此外,还可以调整CFQ的其他参数,如权重、I/O超时等。
-
Deadline调度算法
将I/O请求分为两类:实时I/O请求和普通I/O请求。实时I/O请求是指需要立即响应的请求,例如鼠标、键盘输入等。普通I/O请求是指需要等待一定时间才能得到响应的请求,例如文件读写操作等。
将实时I/O请求插入到队列头部,优先处理;对于普通I/O请求,则会设置一个截止时间(deadline),在此之前尽可能地处理请求。
使用场景:适合需要响应速度较快的应用程序,例如实时音视频应用、游戏等
要切换到Deadline调度器,可以执行以下命令:
echo deadline > /sys/block/sda/queue/ioschedDeadline调度器通常不需要进一步的调整,但也可以配置其读写超时参数。
-
NOOP调度算法
一种简单的调度算法,它不会对I/O请求进行排序或调度,而是按照请求的先后顺序依次处理。在高负载的情况下,NOOP调度算法可以减少CPU的消耗,但是在磁盘较忙的情况下可能会导致响应时间较长。
使用场景:适合低负载的系统,例如桌面系统或者轻负载的服务器系统。或者SSD磁盘
要将调度器设置为NOOP,可以执行以下命令:
echo noop > /sys/block/sda/queue/iosched由于NOOP调度器不进行任何优化,因此在大多数现代系统中,它可能不是最佳选择。
修改I/O调度器通常不需要重新编译内核,但是修改后需要重新启动系统才能使更改生效。此外,这些更改只对特定的磁盘设备有效,并且可以通过cat /sys/block/<device>/queue/iosched来查看当前生效的I/O调度器。
在选择和修改I/O调度器时,建议根据具体的工作负载和性能需求进行测试和评估,以确定最适合的调度器配置
4.设置预读取数据的大小
在Linux系统中,预读取(readahead)是一种优化磁盘访问性能的技术,它通过在读取操作之前预测并提前加载数据到内存中,从而减少了磁盘I/O操作的延迟。预读取数据的大小(即预读扇区数)可以通过blockdev命令进行设置。
预读取数据的大小通常以512字节的扇区为单位进行设置。要设置预读取数据的大小,可以使用blockdev命令的--setra选项,后面跟上你想要设置的扇区数。例如,如果你想要设置预读取数据的大小为4KB(即8个512字节的扇区),你可以执行以下命令
[root@localhost ~]# blockdev --setra 8 /dev/sda
# 通过设置块设备的预读取数据大小/sys/block/sda/queue/read_ahead_kb,以加快读取速度。
这里的/dev/sda是你要设置预读取大小的磁盘设备。请确保替换为你实际想要设置的设备名称。
另外,你可以使用--getra选项来查看当前设备的预读取设置:
[root@localhost ~]# blockdev --getra /dev/sda
这将返回当前设备的预读取扇区数。
预读取大小的设置规则:
一般预读取大小在 64KB 到 256KB 之间是比较合适,如果太小浪费磁盘IO,太大浪费内存资源。高速 SSD 设备,预读取的大小页不要超过 1MB。
请注意,修改预读取设置可能会对系统性能产生影响,因此在进行任何更改之前,建议仔细考虑并测试其效果。此外,对于大多数现代Linux发行版,内核和文件系统已经内置了智能的预读取机制,因此手动调整预读取设置可能不是必要的,除非你有特定的性能需求或遇到了特定的性能问题
5.优化磁盘碎片
磁盘碎片是指硬盘上存储的文件在写入和删除过程中被分割成不连续的片段,使得文件在硬盘上的物理位置不再是连续的。所以导致磁盘的读写速度变慢。
查看和清理磁盘碎片:
`ext4文件系统:
# dumpe2fs /dev/sda1 查看是否存在磁盘碎片
# e4defrag /dev/sda1 清理磁盘碎片 清理sda1的磁盘碎片
`xfs文件系统:
# xfs_db -c frag /dev/sda1 查看是否存在磁盘碎片
# xfs_fsr /dev/sda1 清理磁盘碎片
5.6 网络的优化方法
1.调整TCP/IP参数来优化网络
Linux系统默认的TCP/IP参数适用于多数情况,但是对于高负载或者高流量的应用需要调整TCP窗口大小、最大并发连接数、最大传输单元(MTU)等参数。
例如:如果需要处理10000个并发连接,可以将这两个参数设置为10000:
echo "10000" > /proc/sys/net/ipv4/tcp_max_syn_backlog # TCP最大连接数,默认是1024
echo "10000" > /proc/sys/net/core/somaxconn # 最大同步连接数,默认是1024
2.开启TCP的快速连接机制
在Linux内核版本3.7及以上,TCP快速打开已经默认启用。CP快速打开可以减少TCP三次握手的时间,从而提高连接速度和性能
[root@localhost ~]# echo "2" > /proc/sys/net/ipv4/tcp_fastopen
# 0:禁用TCP Fast Open功能
# 1:启用TCP Fast Open客户端功能,但不启用服务器端功能。这是默认值
# 2:启用TCP Fast Open客户端和服务器端功能
3.启用TCP拥塞控制算法
启用和调优TCP拥塞控制算法是网络系统调优中的一个重要环节。TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议,它在网络中扮演着关键的角色。当网络拥塞时,TCP通过拥塞控制算法来调整发送速率,以避免网络拥塞进一步恶化
以下是一些步骤和考虑因素,可以帮助你启用和调优TCP拥塞控制算法:
-
选择合适的拥塞控制算法:
- Linux内核支持多种TCP拥塞控制算法,如
reno、cubic、vegas、bic、hybla、illinois、bbr(Bottleneck Bandwidth and Round-trip propagation time)等。 - 默认情况下,许多现代Linux发行版使用
cubic算法,因为它在许多情况下都表现良好。cubic算法:更为适用于高延迟、高带宽的网络环境 reno算法:适合传输速度相对较快,延迟较低,丢包率也较低的网络环境bbr算法是近年来比较流行的选择,它试图直接估计瓶颈带宽和往返时间,以更有效地管理拥塞
- Linux内核支持多种TCP拥塞控制算法,如
-
查看当前拥塞控制算法
`当前系统中可用的TCP拥塞控制算法 cat /proc/sys/net/ipv4/tcp_available_congestion_control `当前系统中设置的TCP拥塞控制算法 cat /proc/sys/net/ipv4/tcp_congestion_control -
更改拥塞控制算法
echo "bbr" > /proc/sys/net/ipv4/tcp_congestion_control -
持久化设置
# vim /etc/sysctl.conf net.ipv4.tcp_congestion_control=cubic
4.调整网络缓冲区大小
调整网络缓冲区大小(也称为套接字缓冲区大小)是在网络调优中常用的技术,旨在提高网络吞吐量或减少延迟。这些缓冲区用于在将数据发送到网络或从网络接收数据之前暂存数据。Linux 提供了几种方法来修改这些缓冲区的大小。
以下是如何调整 TCP/IP 套接字缓冲区大小的步骤:
- 临时调整(不需要重启)
你可以使用 net.core.rmem_default、net.core.rmem_max、net.core.wmem_default 和 net.core.wmem_max 这些系统参数来临时调整套接字缓冲区大小。这些值都是以字节为单位的
# 设置接收缓冲区默认和最大值
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.rmem_max=262144
# 设置发送缓冲区默认和最大值
sysctl -w net.core.wmem_default=262144
sysctl -w net.core.wmem_max=262144
这些更改是临时的,只会在当前会话中生效。系统重启后,这些值将恢复到 /etc/sysctl.conf 或 /etc/sysctl.d/ 目录下的配置文件中指定的值
-
永久调整(需要重启)
要永久调整缓冲区大小,你需要修改
/etc/sysctl.conf文件或/etc/sysctl.d/目录下的某个文件。编辑/etc/sysctl.conf文件,添加或修改以下行:net.core.rmem_default = 262144 net.core.rmem_max = 262144 net.core.wmem_default = 262144 net.core.wmem_max = 262144然后,运行以下命令使更改生效:
sysctl -p 或者,你也可以创建一个新的配置文件在
/etc/sysctl.d/目录下,例如network-buffers.conf,并在其中添加上述设置,然后运行sudo sysctl -p /etc/sysctl.d/network-buffers.conf来应用更改
注意事项
- 在增加缓冲区大小时,请确保系统有足够的内存来支持这些更大的缓冲区。如果系统内存不足,这可能会导致其他问题
- 增加缓冲区大小可能并不会总是提高性能。在某些情况下,增加缓冲区大小可能会导致不必要的内存使用,甚至可能降低性能。因此,在调整这些值之前,最好先通过性能测试来确定最佳配置
- 如果你在虚拟机上运行系统,那么宿主机的网络配置和资源分配也可能会影响性能,因此需要相应地考虑
- 这些设置可能需要根据不同的网络环境和应用程序需求进行调整。例如,对于高带宽、低延迟的网络连接,可能需要增加缓冲区大小;而对于低带宽、高延迟的网络连接,可能需要减少缓冲区大小以减少延迟
5.禁用IPv6
如果没有使用IPv6,禁用IPv6协议,从而减少网络连接的负载
-
通过系统配置文件
/etc/sysctl.conf-
打开
/etc/sysctl.conf文件。 -
添加以下行来禁用整个系统的IPv6:
net.ipv6.conf.all.disable_ipv6 = 1如果你只想禁用某个特定接口的IPv6(例如
eth0),则可以添加:net.ipv6.conf.eth0.disable_ipv6 = 1 -
保存并关闭文件。
-
运行以下命令使更改生效:
sysctl -p /etc/sysctl.conf
-
-
通过内核启动时传递参数
-
打开
/etc/default/grub文件。 -
找到
GRUB_CMDLINE_LINUX或GRUB_CMDLINE_LINUX_DEFAULT行。 -
在该行的引号内添加
ipv6.disable=1,例如:GRUB_CMDLINE_LINUX="ipv6.disable=1 quiet" -
保存并关闭文件。
-
更新GRUB配置并重新生成启动加载器:
update-grub -
重启系统使更改生效。
-
6.调整TCP窗口大小
TCP窗口大小是TCP连接中的一个重要参数,它决定了在一次连接中可以发送的最大数据量。窗口大小由接收方的接收缓冲区大小、网络带宽和往返时延等因素共同决定。窗口大小以字节为单位,并且可以根据这些因素进行计算。
TCP窗口大小是可以动态变化的,它受到多种因素的影响,例如网络拥塞、接收方的接收缓冲区大小、发送方的发送缓冲区大小等。在TCP连接建立之初,窗口大小通常较小,然后随着连接的进行,窗口大小会逐渐增大,直到达到窗口大小的最大限制。
需要注意的是,不同的操作系统和网络环境可能会有不同的默认窗口大小设置。此外,窗口大小还可以通过网络配置进行调整,以满足特定的性能需求
通过修改窗口的大小,提升网络的传输速度和网络性能
例如:
vim /etc/sysctl.conf
net.ipv4.tcp_window_scaling = 1 #启用TCP窗口扩展功能
net.ipv4.tcp_rmem = 4096 131072 6291456 # 最小值、默认值和最大值
net.ipv4.tcp_wmem = 4096 16384 4194304
7.调整连接队列和最大连接数
如果TCP的连接队列太小,就会导致客户端连接请求被拒绝,如果连接队列太大,就会占用过多的内存资源
如果TCP的最大连接数设置得太低,会导致系统无法支持足够的并发连接,从而导致系统响应变慢或者连接超时。
调整TCP的连接队列和最大连接数:
# 查看当前系统的最大连接数:
# 查看当前的TCP最大连接数是否接近
系统的最大连接数,如果接近就修改为一个更大的值。
[root@localhost ~]# ss -n | grep tcp | grep ESTABLISHED | wc -l
# 查看TCP的最大连接数 默认TCP的最大连接数是256
[root@localhost ~]# cat /proc/sys/net/core/somaxconn
128
# 设置TCP的最大连接数
[root@localhost ~]# sysctl -w net.core.somaxconn=2048
# 设置TCP的连接队列 一般设置为最大连接数的两倍
[root@localhost ~]# sysctl -w net.core.somaxconn=1024
3. 保存并关闭文件。
4. 运行以下命令使更改生效:
```bash
sysctl -p /etc/sysctl.conf
```
2. **通过内核启动时传递参数**
1. 打开 `/etc/default/grub` 文件。
2. 找到 `GRUB_CMDLINE_LINUX` 或 `GRUB_CMDLINE_LINUX_DEFAULT` 行。
3. 在该行的引号内添加 `ipv6.disable=1`,例如:
```bash
GRUB_CMDLINE_LINUX="ipv6.disable=1 quiet"
```
4. 保存并关闭文件。
5. 更新GRUB配置并重新生成启动加载器:
```bash
update-grub
```
6. 重启系统使更改生效。
**6.调整TCP窗口大小**
TCP窗口大小是TCP连接中的一个重要参数,它决定了在一次连接中可以发送的最大数据量。窗口大小由接收方的接收缓冲区大小、网络带宽和往返时延等因素共同决定。窗口大小以字节为单位,并且可以根据这些因素进行计算。
TCP窗口大小是可以动态变化的,它受到多种因素的影响,例如网络拥塞、接收方的接收缓冲区大小、发送方的发送缓冲区大小等。在TCP连接建立之初,窗口大小通常较小,然后随着连接的进行,窗口大小会逐渐增大,直到达到窗口大小的最大限制。
需要注意的是,不同的操作系统和网络环境可能会有不同的默认窗口大小设置。此外,窗口大小还可以通过网络配置进行调整,以满足特定的性能需求
通过修改窗口的大小,提升网络的传输速度和网络性能
例如:
```shell
vim /etc/sysctl.conf
net.ipv4.tcp_window_scaling = 1 #启用TCP窗口扩展功能
net.ipv4.tcp_rmem = 4096 131072 6291456 # 最小值、默认值和最大值
net.ipv4.tcp_wmem = 4096 16384 4194304
7.调整连接队列和最大连接数
如果TCP的连接队列太小,就会导致客户端连接请求被拒绝,如果连接队列太大,就会占用过多的内存资源
如果TCP的最大连接数设置得太低,会导致系统无法支持足够的并发连接,从而导致系统响应变慢或者连接超时。
调整TCP的连接队列和最大连接数:
# 查看当前系统的最大连接数:
# 查看当前的TCP最大连接数是否接近
系统的最大连接数,如果接近就修改为一个更大的值。
[root@localhost ~]# ss -n | grep tcp | grep ESTABLISHED | wc -l
# 查看TCP的最大连接数 默认TCP的最大连接数是256
[root@localhost ~]# cat /proc/sys/net/core/somaxconn
128
# 设置TCP的最大连接数
[root@localhost ~]# sysctl -w net.core.somaxconn=2048
# 设置TCP的连接队列 一般设置为最大连接数的两倍
[root@localhost ~]# sysctl -w net.core.somaxconn=1024

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









