







文章目录
Kubernetes快速实战与核心原理剖析(1)-CSDN博客
Kubernetes快速实战与核心原理剖析(2)-CSDN博客
1. K8S概览
1.1 K8S是什么
K8S官网文档:https://kubernetes.io/zh/docs/home/
K8S 是Kubernetes的全称,源于希腊语,意为“舵手”或“飞行员”。Kubernetes 是用于自动部署、扩缩和管理容器化应用程序的开源系统。 Kubernetes 源自 Google15年生产环境运维经验, 同时凝聚了社区的最佳创意和实践。
Docker:作为开源的应用容器引擎,可以把应用程序和其相关依赖打包生成一个 Image 镜像文件,是一个标准的运行环境,提供可持续交付的能力;
Kubernetes:作为开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理;
1.2 K8S核心特性
服务发现与负载均衡:无需修改你的应用程序即可使用陌生的服务发现机制。
存储编排:自动挂载所选存储系统,包括本地存储。
Secret和配置管理:部署更新Secrets和应用程序的配置时不必重新构建容器镜像,且不必将软件堆栈配置中的秘密信息暴露出来。
批量执行:除了服务之外,Kubernetes还可以管理你的批处理和CI工作负载,在期望时替换掉失效的容器。
水平扩缩:使用一个简单的命令、一个UI或基于CPU使用情况自动对应用程序进行扩缩。
自动化上线和回滚:Kubernetes会分步骤地将针对应用或其配置的更改上线,同时监视应用程序运行状况以确保你不会同时终止所有实例。
自动装箱:根据资源需求和其他约束自动放置容器,同时避免影响可用性。
自我修复:重新启动失败的容器,在节点死亡时替换并重新调度容器,杀死不响应用户定义的健康检查的容器。
1.3 K8S 核心架构
我们已经知道了 K8S 的核心功能:自动化运维管理多个容器化程序。那么 K8S 怎么做到的呢?这里, 我们从宏观架构上来学习 K8S 的设计思想。首先看下文:
K8S 是属于Master-Worker架构,即有 Master 节点负责核心的调度、管理和运维,Worker 节点则 执行用户的程序。但是在 K8S 中,主节点一般被称为Master Node ,而从节点则被称为Worker Node 或者 Node。
注意:Master Node 和 Worker Node 是分别安装了 K8S 的 Master 和 Woker 组件的实体服务器, 每个 Node 都对应了一台实体服务器(虽然 Master Node 可以和其中一个 Worker Node 安装在同一台服务器,但是建议 Master Node 单独部署),所有 Master Node 和 Worker Node 组成了K8S 集群,同一个集群可能存在多个 Master Node 和 Worker Node。
首先来看Master Node都有哪些组件:
kube-apiserver。K8S 的请求入口服务。API Server 负责接收 K8S 所有请求(来自 UI 界面或者 CLI 命令行工 具),然后,API Server 根据用户的具体请求,去通知其他组件干活。
Scheduler。K8S 所有 Worker Node 的调度器。当用户要部署服务时,Scheduler 会选择最合适的 Worker Node(服务器)来部署。
Controller Manager。K8S 所有 Worker Node 的监控器。Controller Manager 有很多具体的 Controller, Node Controller、Service Controller、Volume Controller 等。Controller 负责监控和调整在 Worker Node 上部署的服务的状态,比如用户要求 A 服务部署 2 个副本,那么当其中一个服务挂了的时候,Controller 会马 上调整,让 Scheduler 再选择一个 Worker Node 重新部署服务。
etcd。K8S 的存储服务。etcd 存储了 K8S 的关键配置和用户配置,K8S 中仅 API Server 才具备读写权限,其 他组件必须通过 API Server 的接口才能读写数据。
接着来看Worker Node的组件:
Kubelet。Worker Node 的监视器,以及与 Master Node 的通讯器。Kubelet 是 Master Node 安插在 Worker Node 上的“眼线”,它会定期向 Master Node 汇报自己 Node 上运行的服务的状态,并接受来自 Master Node 的指示采取调整措施。负责控制所有容器的启动停止,保证节点工作正常。
Kube-Proxy。K8S 的网络代理。Kube-Proxy 负责 Node 在 K8S 的网络通讯、以及对外部网络流量的负载均 衡。
Container Runtime。Worker Node 的运行环境。即安装了容器化所需的软件环境确保容器化程序能够跑起 来,比如 Docker Engine运行环境。

1.4 K8S集群安装
准备机器
搭建K8S集群,准备三台2核4G的虚拟机(内存至少2G以上),操作系统选择用centos 7以上版本
| 主机 | 说明 |
| 192.168.11.101 | k8s-master |
| 192.168.11.102 | k8s-node1 |
| 192.168.11.103 | k8s-node2 |
1.4.1 安装Docker
#如果安卓过docker,执行以下命令移除之前安装过的docker版本
sudo yum remove docker*
sudo yum install -y yum-utils
#配置docker的yum地址
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#安装指定版本
sudo yum install -y docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io-1.4.6
#启动&开机启动docker
systemctl enable docker --now
# docker镜像加速器配置
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://jbw52uwf.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
#配置生效
sudo systemctl daemon-reload
#重启docker
sudo systemctl restart docker1.4.2、安装Kubernetes
1.4.2.1 基本环境
所有机器执行以下操作
每个机器使用内网ip互通
# 1. 关闭防火墙并设置开机不启动
systemctl stop firewalld
systemctl disable firewalld
# 2. 关闭 selinux
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 3. 关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
systemctl reboot #重启生效
free -m #查看下swap交换区是否都为0,如果都为0则swap关闭成功
# 4. 给三台机器分别设置主机名
hostnamectl set-hostname xxx
第一台:k8s-master
第二台:k8s-node1
第三台:k8s-node2
# 5. 添加hosts,执行如下命令,ip需要修改成你自己机器的ip
cat >> /etc/hosts << EOF
192.168.11.101 k8s-master
192.168.11.102 k8s-node1
192.168.11.103 k8s-node2
EOF
# 6. 允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
# 7. 设置时间同步
yum install ntpdate -y
ntpdate time.windows.com
1.4.2.2 安装kubelet、kubeadm、kubectl
# 8. 配置k8s的yum源地址
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 9. 如果之前安装过k8s,先卸载旧版本
yum remove -y kubelet kubeadm kubectl
# 10. 查看可以安装的版本
yum list kubelet --showduplicates | sort -r
# 11. 安装 kubelet,kubeadm,kubectl指定版本,我们使用kubeadm方式安装k8s集群
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9
# 12. 开机启动kubelet
sudo systemctl enable --now kubelet1.4.2.3 初始化master节点
1.4.2.3.1 下载各个机器需要的镜像
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.20.9
kube-proxy:v1.20.9
kube-controller-manager:v1.20.9
kube-scheduler:v1.20.9
coredns:1.7.0
etcd:3.4.13-0
pause:3.2
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName
done
EOF
chmod +x ./images.sh && ./images.sh1.4.2.3.2 初始化主节点
# 在k8s-master机器上执行初始化操作(里面的第一个ip地址就是k8s-master机器的ip,改成你自己机器的,后面两个ip网段不用动)
#所有网络范围不重叠
kubeadm init \
--apiserver-advertise-address=192.168.11.101 \
--control-plane-endpoint=k8s-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16
# 可以查看kubelet日志
journalctl -xefu kubelet 如果初始化失败建议卸载重装
1.4.2.3.3 根据提示继续
master成功后提示如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-master:6443 --token 50rexj.yb0ys92ynnxxbo2s \
--discovery-token-ca-cert-hash sha256:10fd9d2a9f4e2d7dff502aa3fb31a80f0372666efc92defde3707b499ba000e9 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-master:6443 --token 50rexj.yb0ys92ynnxxbo2s \
--discovery-token-ca-cert-hash sha256:10fd9d2a9f4e2d7dff502aa3fb31a80f0372666efc92defde3707b499ba000e9注意最后这行,这是从节点加入集群所需要的命令
如果忘记,可以通过下面的命令在主节点重新生成令牌
kubeadm token create --print-join-command
设置.kube/config
# 配置使用 kubectl 命令工具
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
安装Calico网络插件
curl https://docs.projectcalico.org/archive/v3.20/manifests/calico.yaml -O
kubectl apply -f calico.yaml如果配置多网卡,出现下面的错误:calico/node is not ready: BIRD is not ready: BGP not established with xxx
修改calico.yaml的内容,指定网卡,添加下面两行:
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"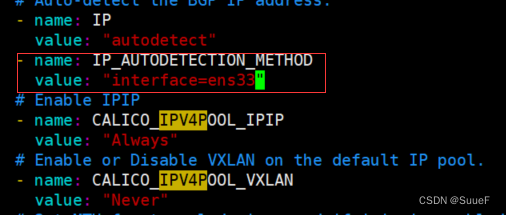
1.4.2.3.4 加入node节点
# 将node节点加入进master节点的集群里
kubeadm join k8s-master:6443 --token 50rexj.yb0ys92ynnxxbo2s \
--discovery-token-ca-cert-hash sha256:10fd9d2a9f4e2d7dff502aa3fb31a80f0372666efc92defde3707b499ba000e9# node节点执行kubectl命令kubectl get nodes出现下面的错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
# 解决方案: 在node节点配置KUBECONFIG环境变量即可
echo "export KUBECONFIG=/etc/kubernetes/kubelet.conf" >> /etc/profile
source /etc/profile1.4.2.3.5 验证集群节点状态
#在k8s-master机器执行查看节点命令
kubectl get nodes
所有pod状态都为Running则证明集群安装成功
2. K8s快速实战
2.1 kubectl命令使用
kubectl是apiserver的客户端工具,工作在命令行下,能够连接apiserver实现各种增删改查等操作 kubectl官方使用文档: https://kubernetes.io/zh/docs/reference/kubectl/overview/
K8S的各种命令帮助文档做得非常不错,遇到问题可以多查help帮助
2.2 Namespace
K8s 中,命名空间(Namespace)提供一种机制,将同一集群中的资源划分为相互隔离的组。同一命名空间内的资 源名称要唯一,命名空间是用来隔离资源的,不隔离网络。 Kubernetes 启动时会创建四个初始命名空间:
default
Kubernetes 包含这个命名空间,以便于你无需创建新的命名空间即可开始使用新集群。
kube-node-lease
该命名空间包含用于与各个节点关联的 Lease对象。 节点租约允许 kubelet 发送 ,由此控制面能够检测到节点故障。
kube-public
所有的客户端(包括未经身份验证的客户端)都可以读取该命名空间。 该命名空间主要预留为集群使 用,以便某些资源需要在整个集群中可见可读。 该命名空间的公共属性只是一种约定而非要求。
kube-system
该命名空间用于 Kubernetes 系统创建的对象。
# 查看namespace
kubectl get namespace
#查看kube-system下的pod
kubectl get pods -n kube-system
#查看所有namespace下的pod
kubectl get pods -A创建Namesapce示例
命令行方式
可以使用下面的命令创建Namespace:
kubectl create namespace ems
yaml方式
新建一个名为 my-namespace.yaml 的 YAML 文件,并写入下列内容:
apiVersion: v1
kind: Namespace
metadata:
name: ems然后运行:
kubectl apply -f my-namespace.yaml删除namesapce
kubectl delete namespace ems
kubectl delete -f my-namespace.yaml
2.3 Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个)容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。
创建Pod示例:运行一个NGINX容器
命令行方式
#创建pod
kubectl run mynginx --image=nginx:1.14.2 -n ems
#获取pod的信息,-owide 表示更详细的显示信息 -n 命名空间 查询对应namespace下的pod
kubectl get pod
kubectl get pod -owide
kubectl get pod -owide -n <namespace-name>
#查看pod的详情
kubectl describe pod <pod-name>
# 查看Pod的运行日志
kubectl logs <pod-name>
# 删除pod
kubectl delete pod <pod-name>yaml方式
#vim nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80然后运行:
kubectl apply -f nginx-pod.yaml -n ems删除pod
kubectl delete -f nginx-pod.yaml -n ems思考:一个pod中可以运行多个容器吗?
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx:1.14.2
name: nginx
- image: tomcat:9.0.55
name: tomcat
2.4 Deployment
Deployment负责创建和更新应用程序的实例,使Pod拥有多副本,自愈,扩缩容等能力。创建 Deployment后,Kubernetes Master 将应用程序实例调度到集群中的各个节点上。如果托管实例的 节点关闭或被删除,Deployment控制器会将该实例替换为群集中另一个节点上的实例。这提供了一 种自我修复机制来解决机器故障维护问题。
创建一个Tomcat应用程序
使用 kubectl create deployment 命令可以创建一个应用部署deployment与pod
#my-tomcat表示pod的名称 --image表示镜像的地址
kubectl create deployment my-tomcat --image=tomcat:9.0.55
#查看一下deployment的信息
kubectl get deployment
#删除deployment
kubectl delete deployment my-tomcat
#查看Pod打印的日志
kubectl logs my-tomcat-6d6b57c8c8-n5gm4
#使用 exec 可以在Pod的容器中执行命令
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- env #使用 env 命令查看环境变量
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- ls / # 查看容器的根目录下面内容
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- sh #进入Pod容器内部并执行bash命令,如果想退出容器可以使用exit命令
自愈
现在我们来删除刚刚添加的pod,看看会发生什么
#查看pod信息,-w意思是一直等待观察pod信息的变动
kubectl get pod -w开另外一个命令窗口执行如下命令,同时观察之前命令窗口的变化情况
kubectl delete pod my-tomcat-6d6b57c8c8-n5gm4我们可以看到之前那个tomcat的pod被销毁,但是又重新启动了一个新的tomcat pod,这是k8s的服务自愈功能,不需要运维人员干预
多副本
命令行的方式
# 创建3个副本
kubectl create deployment my-tomcat --image=tomcat:9.0.55 --replicas=3yaml方式
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-tomcat
name: my-tomcat
spec:
replicas: 3
selector:
matchLabels:
app: my-tomcat
template:
metadata:
labels:
app: my-tomcat
spec:
containers:
- image: tomcat:9.0.55
name: tomcat扩缩容
# 扩容到5个pod
kubectl scale --replicas=5 deployment my-tomcat
# 缩到3个pod
kubectl scale --replicas=3 deployment my-tomcat
#修改 replicas
kubectl edit deployment my-tomcat滚动升级与回滚
对my-tomcat这个deployment进行滚动升级和回滚,将tomcat版本由tomcat:9.0.55升级到 tomcat:10.1.11,再回滚到tomcat:9.0.55
滚动升级:
kubectl set image deployment my-tomcat tomcat=tomcat:10.1.11 --record可以执行 kubectl get pod -w 观察pod的变动情况,可以看到有的pod在销毁,有的pod在创建查看pod信息
kubectl get pod查看某个pod的详细信息,发现pod里的镜像版本已经升级了
kubectl describe pod my-tomcat-85c5c8f685-lnkfm
版本回滚: 查看历史版本
kubectl rollout history deploy my-tomcat回滚到上一个版本
kubectl rollout undo deployment my-tomcat #--to-revision 参数可以指定回退的版本
#回滚(回到指定版本)
kubectl rollout undo deployment/my-dep --to-revision=2查看pod详情,发现版本已经回退了
访问tomcat pod
集群内访问(在集群里任一worker节点都可以访问)
curl 10.244.169.164:8080集群外部访问
当我们在集群之外访问是发现无法访问,那么集群之外的客户端如何才能访问呢?这就需要我们的 service服务了,下面我们就创建一个service,使外部客户端可以访问我们的pod
2.5 Service
Service是一个抽象层,它定义了一组Pod的逻辑集,并为这些Pod支持外部流量暴露、负载均衡和服务发现。
尽管每个Pod 都有一个唯一的IP地址,但是如果没有Service,这些IP不会暴露在群集外部。Service允 许您的应用程序接收流量。Service也可以用在ServiceSpec标记type的方式暴露,type类型如下:
ClusterIP(默认):在集群的内部IP上公开Service。这种类型使得Service只能从集群内访问。
NodePort:使用NAT在集群中每个选定Node的相同端口上公开Service。使用 : 从集 群外部访问Service。是ClusterIP的超集。
LoadBalancer:在当前云中创建一个外部负载均衡器(如果支持的话),并为Service分配一个固定的外部IP。是 NodePort的超集。
ExternalName:通过返回带有该名称的CNAME记录,使用任意名称(由spec中的externalName指定)公开 Service。不使用代理。
创建service示例
命令行的方式
kubectl expose deployment my-tomcat --name=tomcat --port=8080 --type=NodePort
#查看service信息,port信息里冒号后面的端口号就是对集群外暴露的访问接口
# NodePort范围在 30000-32767 之间
kubectl get svc -o wide集群外部访问
使用集群节点的ip加上暴露的端口就可以访问
yaml的方式
# vim mytomcat-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: my-tomcat
name: my-tomcat
spec:
ports:
- port: 8080 # service的虚拟ip对应的端口,在集群内网机器可以访问用service的虚拟ip加该端口号访问服务
nodePort: 30001 # service在宿主机上映射的外网访问端口,端口范围必须在30000-32767之间
protocol: TCP
targetPort: 8080 # pod暴露的端口,一般与pod内部容器暴露的端口一致
selector:
app: my-tomcat
type: NodePort
执行如下命令创建service:
kubectl apply -f mytomcat-service.yaml














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









