







 本文介绍了图的存储(邻接矩阵和邻接表)、深度优先搜索(DFS)的实现以及广度优先搜索(BFS)的应用,结合ACWING846和847题目,详细讲解了如何构建图并运用DFS和BFS求解问题,包括计算删除某顶点后的连通块顶点数量和最短路径等。
本文介绍了图的存储(邻接矩阵和邻接表)、深度优先搜索(DFS)的实现以及广度优先搜索(BFS)的应用,结合ACWING846和847题目,详细讲解了如何构建图并运用DFS和BFS求解问题,包括计算删除某顶点后的连通块顶点数量和最短路径等。
目录
在写题之前先补充图的存储和遍历两个知识点
图的存储
因为树可以看作特殊的图,因此我们只讨论图的存储即可。
关于图的存储有两种方式:邻接矩阵和邻接表,在之前学习数据结构的时候,这两种方法也都写过。有需要的可以看一下
还有之前写哈希表的拉链法的时候,当时就提到其结构很想邻接表,到现在可以自信的说他就是邻接表了hh
由于邻接矩阵比较浪费空间,因此我们一般采用邻接表进行存储。
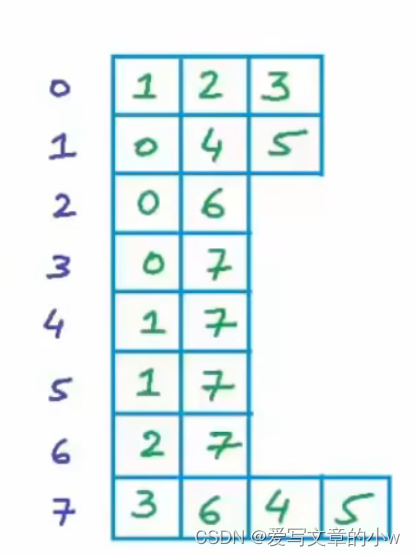
邻接表的主要思想就是:创建一个数据元素是链表的顶点集数组。数组中存放与该顶点相连的其他顶点,一个顶点可能与多个顶点相连,这些定点之间用链表进行连接。
也就是图中这种形式
图的遍历
深度优先 :从一个顶点开始,一直走到最深处

广度优先:从一个顶点开始,逐层遍历

图的深度优先搜索
(这里默认树和图的dfs和bfs每个顶点都只搜一遍)
由于无向图也就是两个顶点之间有两条分别指向对方有向边的意思,因此我们只考虑有向图的深搜,对于无向图,在加边的时候记得两个顶点集的链表中都加上就好。
基本的代码思路是这样的。
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10,M=N*2;//M代表最大边数
int n,m;
int h[N];//存放顶点集
int e[M],ne[M],idx;//模拟单链表 共享的节点池
bool st[N];//标记搜过的点
//添加一条由a指向b的边
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}
//按顶点进行深搜
void dfs(int u)
{
st[u]=1;
for(int i=h[u];i!=-1;i=ne[i])
{
int j=e[i];
if(!st[j])dfs(j);
}
}
int main()
{
memset(h,-1,sizeof h);//将所有链表的头节点均初始化为-1
add(1, 2);
add(2, 3);
dfs(1);//从某个顶点开始深搜
return 0;
}acwing-846

题目理解
看到这道题我比较疑惑的就是关于重心的定义:

下图中做了解释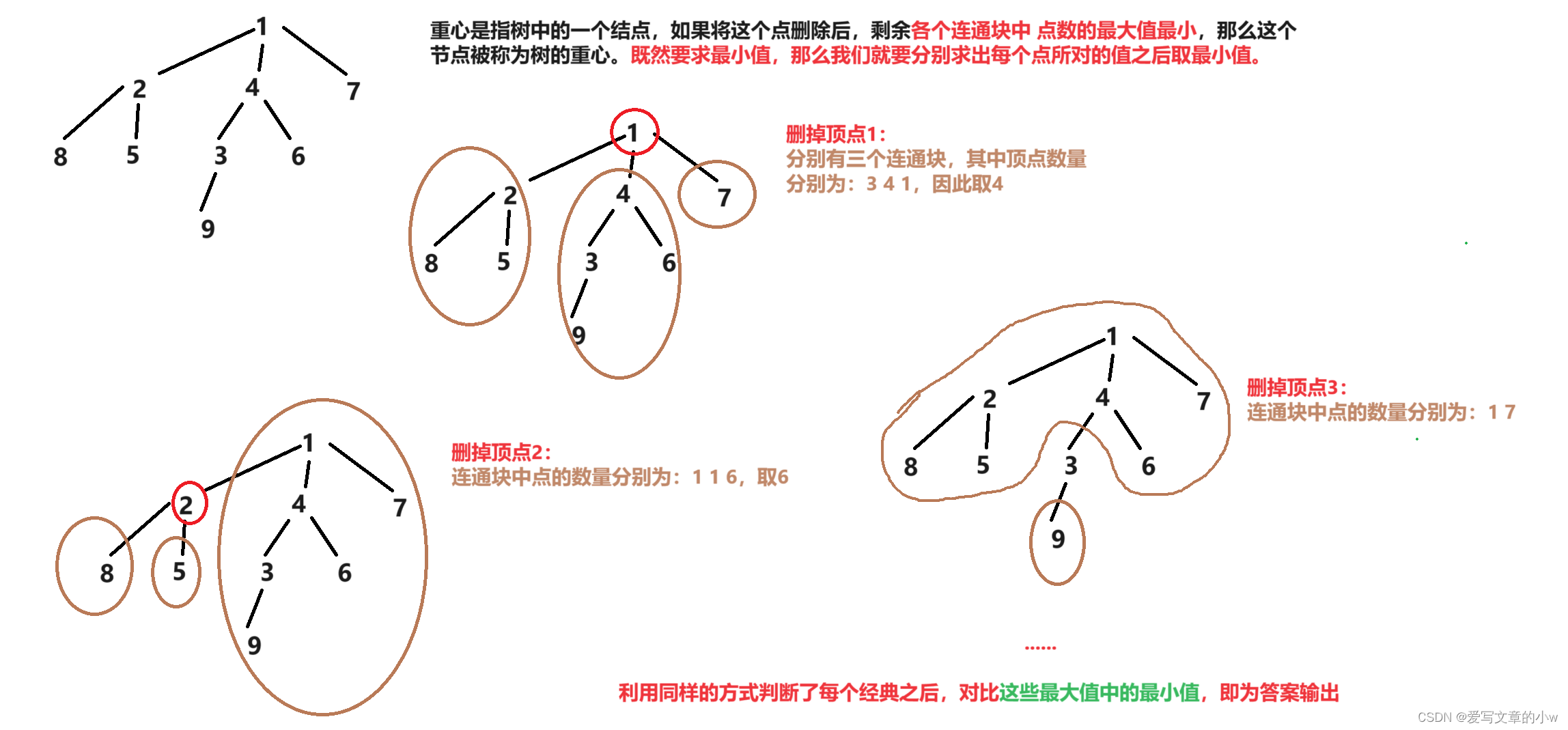
应该可以理解了哈。
其他需要注意的就是:首先这是无向图,注意添加边的时候两个顶点都要加边。
明白了题意还是不知到代码应该怎么写呀🥀
代码思路
我们要做的就是,先加边,以邻接表的方式构成一个无向图(树是特殊的图 这里直接称图了)之后,我们就要深搜每一个节点,算出去掉某顶点之后,剩下的连通块中所含顶点的最大值,最后在把这些最大值直接做个比较求出最小值。这是我们的主要任务,关键是求连通块中点的数量
由于删掉一个顶点之后,各个连通块中点的数量,形成的连通块包含两个部分:该顶点的直连节点所分出来的连通块,和 该子树之外的那个连通块。
该顶点的直连节点所分出来的连通块 也就是该节点的每个子树所包含的顶点数,该子树之外的那个连通块 我们利用总的顶点数减去该顶点的子树所含节点数就得到了。
由此我们dfs函数的主要工作就是求该顶点的子树所包含的顶点数。
先定义ans,记录每个连通块的最大值,最后会得到全局最小值,即最终所求。
我们定义sum,来记录当前顶点的子树中顶点个数,由于该顶点自身就是一个点,所以初始值为1。定义res,用来记录连通块中点的数量的最大值,利用max函数,每求出一个顶点对应的最大值,就直接将其 与前一个连通块重点的数量 进行比较,直接更新为更大的那个。
利用for循环,遍历与顶点u直连的顶点。如果遍历到的顶点未被搜索过,就调用dfs函数求该连通块的顶点数也就是以其为根节点的子树的顶点个数,用s来记录,每次都直接与res所记录的进行比较。且每次都记得要加在sum上。
遍历完之后,通过n-sum就得以该顶点为根的子树之外的那个连通块中点的数量,对res在进行一次max比较,得出该顶点u所对的的最大值,再与ans所记录过的其他顶点的最大值进行min比较,来得出最小值。
代码如下
详细的解释都在注释里,应该可以理解哈
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10,M=2*N;
int n;
int h[N];
int e[M],ne[M],idx;
bool st[N];
int ans=N;//用于存储最终结果,由于求的是最小值,我们将其初始值设为最大
//添加一条由a指向b的边
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}
int dfs(int u)//搜索顶点u
{
st[u]=1;//将u标记为已访问
int sum=1,res=0;//sum记录以u为根的子树的大小,res记录去掉u后,剩下的各部分中最大的那部分的大小
for(int i=h[u];i!=-1;i=ne[i])//遍历u的所有邻接节点
{
int j=e[i];
if(!st[j])
{
int s=dfs(j);//每求出一个邻接节点所对子树的顶点个数,也就是得到了该连通块中的顶点数
res=max(res,s);
sum+=s;//不断累加顶点u所对的各个子树的顶点之和,也就得到了以u为根节点的子树的定点数之和
}
}
res=max(res,n-sum);//那么n-sum表示的就是最后一个连通块中所含顶点数
ans=min(res,ans);//每求出一个res就直接更新ans 判断最小值
return sum;
}
int main()
{
cin>>n;
memset(h,-1,sizeof h);
for(int i=0;i<n-1;i++)//n个顶点其实只要加n-1条边
{
int a,b;
cin>>a>>b;
//这里是无向图,两个顶点对应都要加
add(a,b);
add(b,a);
}
dfs(1);
cout<<ans<<endl;
return 0;
}acwing-847

图的宽度优先搜索就和之前走迷宫的宽搜重合度很高了,我就不再多写了,可以回顾一下那个题
【第十九课】BFS:广度优先搜索 (acwing-844走迷宫 / 含过程演示的视频推荐 / c++代码)
走迷宫那道题,每次的选择有四个方向,而这里每次的选择就只有该顶点直连的那几个顶点。 代码的不同也主要体现在这里。
代码如下
需要提示的都写在注释里了
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10;
int n,m;
int h[N],e[N],ne[N],idx;
int q[N],d[N];//q为队列 d为最短距离
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}
int bfs()
{
int hh=0,tt=0;
q[0]=1;//将顶点1放入队列作为起始顶点(可以从任何一个顶点开始进行广度优先搜索)
memset(d,-1,sizeof d);//初始化距离,表示未识别到该点
d[1]=0;//将顶点1设为0 如果选择的起始顶点不是1,那么对应的 d 数组的下标就应该是所选起始顶点的编号
while(hh<=tt)
{
int t=q[hh++];
for(int i=h[t];i!=-1;i=ne[i])//遍历该顶点的直连节点
{
int j=e[i];
if(d[j]==-1)//没被搜过
{
d[j]=d[t]+1;
q[++tt]=j;
}
}
}
return d[n];//由于顶点从1开始计数,因此最后一个点为第n个点的位置
}
int main()
{
cin>>n>>m;
memset(h, -1, sizeof h);//初始化头节点数组
while(m--)
{
int a,b;
cin>>a>>b;
add(a,b);
}
cout<<bfs()<<endl;
return 0;
}bfs与dfs
这样写下来,感觉利用深搜每次的代码都不太一样,不好想,宽搜的代码就比较相近。
先简单有个印象。

先写到这了,状态还是不太好啊🥀
有问题欢迎指出!一起加油!!















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









