






让我们先来简单认识一下Unicodehe和UTF8
- Unicode字符集将所有字符按照使用上的频繁度划分为17个层面(Plane),每个层面上有216=65536个字符码空间。
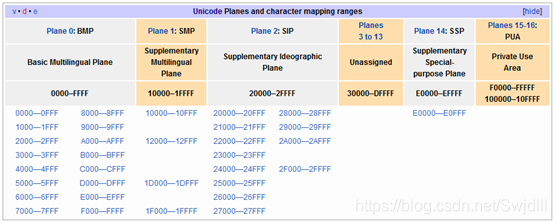
- UTF-8使用1~4字节为每个字符编码,UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。
Unicode的产生原因和Unicode与UTF8之间的转换关系
因为生活中需要被计算机记录的语言、符号越来越多,原先的编码体系已经不能满足人们的需要,各类新的编码规则也应运而生。Unicode最大程度的涵盖了各类语言,为每一个字符、符号都设了一个码。其通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节只需要把高字节全部填为0就可以。
ASCII早于Unicode产生所能表示的比Unicode少,所占用的字符也比Unicode少,因此当ASCII可以表示的字符使用UNICODE来表示时并不高效,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
UTF-8是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。
转化关系:
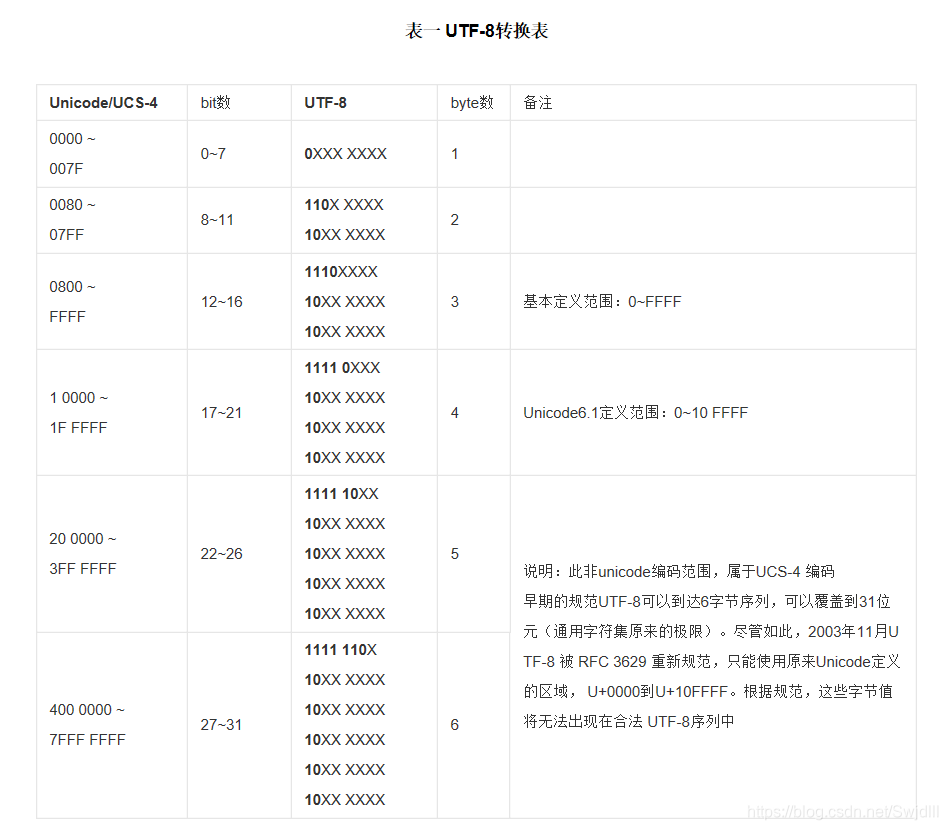
Unicode转换为UTF-8时,可以将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下示例所示的格式,前面按格式填补,不足8位用0填补。
示例
UNICODE uCA(1100 1010) 编码成UTF-8将需要2个字节:
uCA(Unicode)—— C3 8A(UTF8), 过程如下:
uCA(1100 1010)处于0080 ~07FF之间,从上文中的转换表可知对其编码需要2bytes,即两个字节,其对 应 UTF-8格式为: 110X XXXX10XX XXXX。从此格式中可以看到,对其编码还需要11位,而uCA(1100 1010)仅有8位,这时需要在其二进制数前补0凑成11位: 000 1100 1010, 依次填入110X XXXX 10XX XXXX的空位中, 即得 1100 0011 1000 1010(C38A)。















 9586
9586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









