







Spark Streaming
引入
实时和离线 数据处理 ?
指的是数据处理延迟的长短,
实时数据处理是毫秒级别 !离线处理级别的延迟在小时、天;
流式和批量 处理 ?
数据处理的方式角度;
流式是来一条处理一条,批量是一次积攒一批再做处理;
1. Spark Streaming 是什么
SparkStreaming就是将连续的数据 持久化,离散化,然后进行批量处理的框架;
SparkStreaming是准实时(秒级别)、微批次的数据处理框架;
- 为什么是微批次 ?
如果来一条处理一条,资源浪费;数据量太大,延迟越大,吞吐量小;
所以SparkStreaming使用微批次,介于【离线和实时之间】!
微批次使得吞吐量更大 !
基本思想:
和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作DStream。
DStream 是随时间推移而收到的数据的序列。
DStream是Spark Streaming特有的数据类型;
Spark Streaming将接收到的实时流数据,按照一定时间间隔对数据进行拆分,交给 Spark Engine引擎进行处理,最终得到一批批的结果。
Dstream:
Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream;
假如外部数据不断涌入,按照一分钟切片,每个一分钟内部的数据是连续的(连续数据流),而一分钟与一分钟的切片却是相互独立的(离散流)。
Spark Streaming将产生高度分离的数据流叫DStream(discretized Stream);
DStream既可以从输入数据源创建得来(如Kafka、Flume),也可以从其他DStream经过一些算子操作得来;
在内部,每个【时间区间】收到的数据都作为 RDD 存在,而 DStream 是由这些RDD 所组成的序列 (因此得名“离散化”);
Dstream可以看做一组RDDs, 即对 RDD 在【实时数据处理场景】的一种封装;
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream;
在底层,其实其原理为 对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。
底层的RDD的transformation操作 还是由Spark Core的计算引擎来实现的。
任何对DStream的操作都会转变为对底层RDD的操作(通过算子):

Dstream 和 RDD:
DStream可以说是逻辑级别的,RDD就是物理级别的,DStream所表达的最终都是通过RDD的转化实现的。前者是更高级别的抽象,后者是底层的实现。DStream实际上就是在时间维度上对RDD集合的封装,DStream与RDD的关系就是随着时间流逝不断的产生RDD,对DStream的操作就是在固定时间上操作RDD。
数据流向:
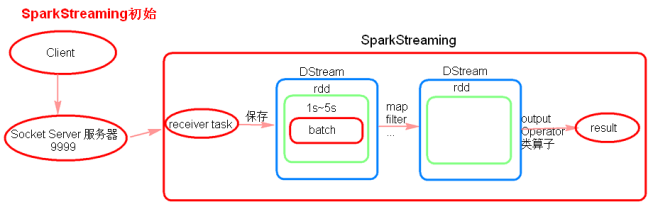
receiver task是一直在执行的,一直在接受数据,将【一段时间内】接收到的数据保存到batch中(默认为5秒)那么会将接受来的数据每隔5秒(可设置)封装到一个batch中,batch没有分布式计算的特性,这一个batch的数据又被封装到一个RDD中最终封装到一个DStream中;
如:
假设批处理间隔(batchInterval)为5秒,每隔5秒通过SparkStreaming将得到的一个DStream,在第6秒的时候开始计算这个DStream;
假设执行任务的时间是3秒,那么第6-9秒一边接受数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作
如果job的执行的时间 > 批处理间隔,接收到的数据会越积越多,最后可能导致OOM;
Spark与Spark Streaming区别:
Spark -> RDD:transformation action + RDD DAG
Spark Streaming -> Dstream:transformation output(它不能让数据在中间激活,必须保证数据有输入有输出) + DStreamGraph
时间区间:
一个采集数据的周期 ,类似滑动窗口;
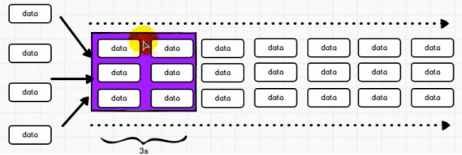
一个时间周期内,由数据采集器将数据采集完成后作为RDD序列,封装成DStream;
最终将RDD发给Driver,形成Task:
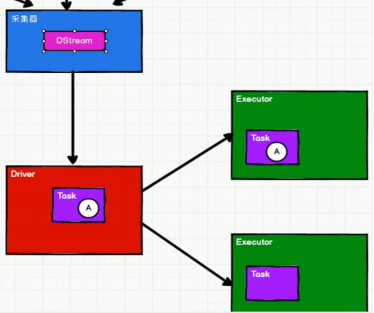
Dstream Graph:
一系列transformation操作的抽象,Dstream之间的转换所形成的的依赖关系全部保存在DStreamGraph中,DStreamGraph对于后期生成RDD Graph至关重要;
持久化:
即接收到的数据暂存。
为什么持久化?做容错的,当数据流出错了,因为没有得到计算,需要把数据从源头进行回溯,暂存的数据可以进行恢复。
离散化:
按时间分片,形成处理单元
SparkStreaming与Storm的区别
- Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批次);因为微批处理,SparkStreaming的吞吐量比Storm要高;
- Storm的事务机制要比SparkStreaming的要完善;
- Storm支持的动态资源调度(Spark1.2及以后也支持)
- SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总计算;
2. 基本架构
Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RDD
Worker(Executor):从网络接收数据,存储并执行RDD计算
Client:负责向Spark Streaming中灌入数据
调度:按照时间触发。
Worker(Executor)里面有个重要的角色:receiver,
receiver:接收器,接收不同的数据源,进行针对性的获取,Spark Streaming 也提供了不同的接收器分布在不同的节点上,每个接收器都是一个特定的进程,每个节点接收一部分作为输入。
receiver接受完不马上做计算,先存储到它的内部缓存区。
因为Streaming 是按照时间不断的分片,所以需要等待,【一旦定时器到时间了】,缓冲区就会把数据转换成数据块block,(缓冲区的作用:按照用户定义的时间间隔切割),然后把数据块放到一个队列里面去,然后Block manager从队列中把数据块拿出来,把数据块转换成一个spark能处理的数据块。
为什么 receiver 是一个进程?
container -> Executor 是一个JVM进程, 所以receiver 是进程级别的 ;
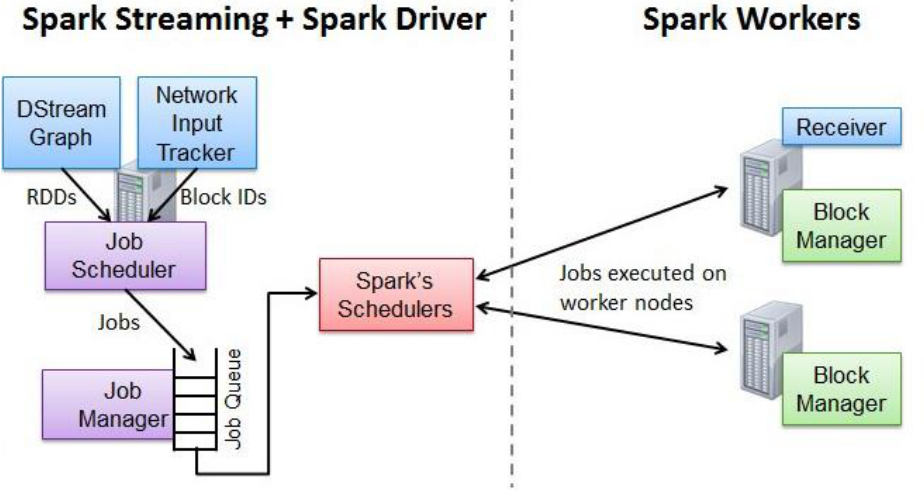
Spark Streaming 作业提交:
- Network Input Tracker:跟踪每一个网络received数据,并且将其映射到相应的input Dstream上
- Job Scheduler:周期性的访问DStreamGraph并生成Spark Job,将其交给JobManager执行
- Job Manager:获取任务队列,并执行Spark任务
3. 运行流程
以wordcount为例:
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息,至少是2 个线程,一个同于接收数据,一个用于处理数据;
val sparkConf =
new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 StreamingContext,如果是RDD则是 new SparkContext(sparkConf)
val ssc = new StreamingContext(sparkConf, Seconds(3)) // 采集周期为3秒
//3.通过监控端口创建 DStream,拿到的就是读进来的一行行的数据
val datas= ssc.socketTextStream("linux1", 9999) // ip+ 端口号
//对Dstream中的每一行数据做切分,形成一个个单词
val wordStreams = datas.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print() // print方法会打印
// 启动采集器
ssc.start()
// 等待采集器的执行
ssc.awaitTermination()
}
}
注意:
- 通过
socketTextStream("linux1", 9999)创建Dstream; - 通过
awaitTermination()等待计算完成,防止应用退出;
启动程序并使用 netcat 工具发送数据;
输出:


设置 batch interval 采集周期为3秒,则 前5个a在一个周期内,后面1个a在周期外;
宏观流程:
- StreamingContext 会在底层创建出SparkContext,用来处理数据
其构造函数可以指定处理一次数据的间隔(batch interval),这里指定为3秒,即3秒 采集一次数据; - 由 socketTextStream() 创建Dstream, 然后指定Dstream计算的步骤;
- 到此时只是设定好了要进行的计算步骤,系统收到数据时计算就会开始。要开始接收数据,必须显式调用StreamingContext 的start() 方法;
- 这样,Spark Streaming 就会开始把Spark 作业不断交给下面的SparkContext 去调度执行。执行会在另一个线程中进行,所以需要调用awaitTermination 来等待流计算完成,来防止应用退出。
详细流程:
(1)初始化StreamingContext + 输出 DStream
-
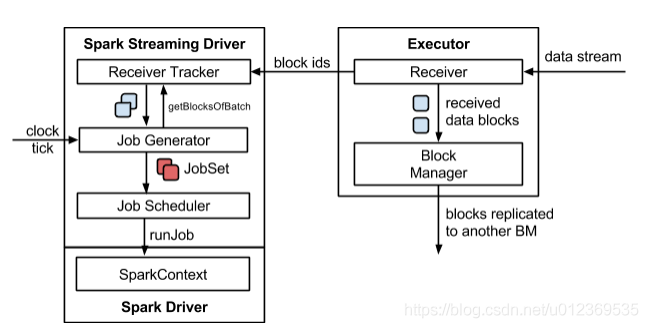
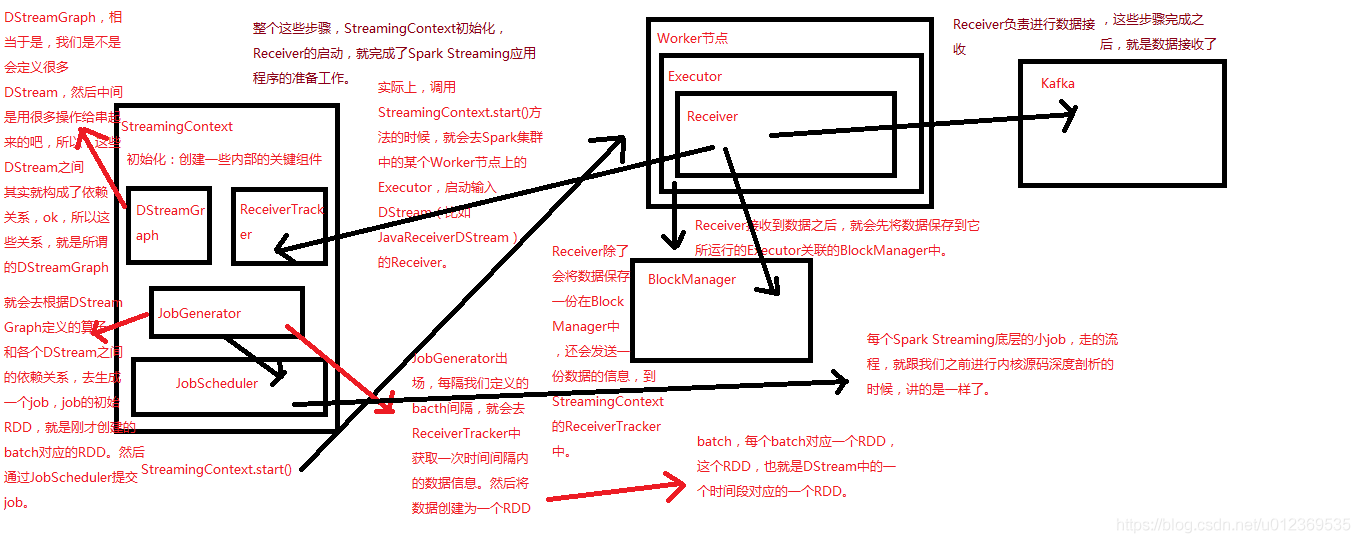
【在Driver端】,StreamingContext初始化时会创建DStreamGraph、ReceiverTracker、JobGenerator、JobScheduler 等;
同时,在Spark集群中的某个【Worker节点上】的Executor,启动输入DStream的Receiver接收器 ; -
Receiver接收器 负责从外部数据源接收数据,
Receiver接收到数据之后,会启动一个BlockGenerator,其会每隔一段时间(可配置,默认是200ms)将Receiver接收到的数据,打包成一个block,
每个block除了会保存到所运行的Executor关联的BlockManager中之外,还会发送一份block信息如blockId到Driver端的ReceiverTracker上,其会将一个一个的block信息存入一个HashMap中,key就是时间; -
JobGenerator会每隔我们定义的batch时间间隔,就会去ReceiverTracker中获取经过这个【batch时间间隔内的】数据信息blocks,将这些block聚合成一个batch,然后这个batch会被创建为一个RDD;
这样每隔一个batch interval时间间隔,就会将这个时间间隔内的数据形成一个RDD,然后形成一个RDD序列,每个RDD代表数据流中一个时间间隔内的数据;
正是这个RDD序列,形成SparkStreaming应用的输入DStream。
(2)DStream的转化 + 输出
在底层,其实其原理为 对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。
Spark Streaming中作业的生成与Spark核心类似,对DStream进行的各种操作让它们之间构建起依赖关系(DStreamGraph);
【当遇到DStream使用输出操作时】,这些DStream之间的依赖关系以及它们之间的操作会被记录到名为DStreamGraph的对象中,触发一个job。
这些job注册到DStreamGraph并不会立即运行,而是等到【Spark Streaming启动后】,【到达批处理时间时】,才根据DSteamGraph生成job处理该批处理时间内接收的数据。
在Spark Streaming如果应用程序中存在多个输出操作,那么在批处理中会产生多个job。
与RDD中的惰性操作类似,RDD遇到行动算子触发job,StreamingContext中遇到输出操作,才执行 job;
常见的Spark Streaming输出:

注意:
尽管这些函数看起来像作用在整个Dstream上一样,但事实上每个DStream 在内部是由许多RDD(批次)组成,且这些转化操作是分别应用到每个RDD 上的;
4. 运行架构
总体来说,Spark Streaming是将流式计算分解成一系列短小的批处理作业;
这里的批处理引擎是Spark Core,也就是Spark Streaming将输入数据按照batch interval分成一段一段的数据(Dstream),每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的Transformation操作变为针对DSteam内各个RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中;
Driver端:
StreamingContext实例。该实例包括DStreamGraph和JobScheduler(包括ReceiverTracker和JobGenerator)等;
Client端:
ReceiverSupervisor和Receiver等;
大致流程分为:
启动流处理引擎、接收及存储流数据、处理流数据、输出处理结果
1) 初始化
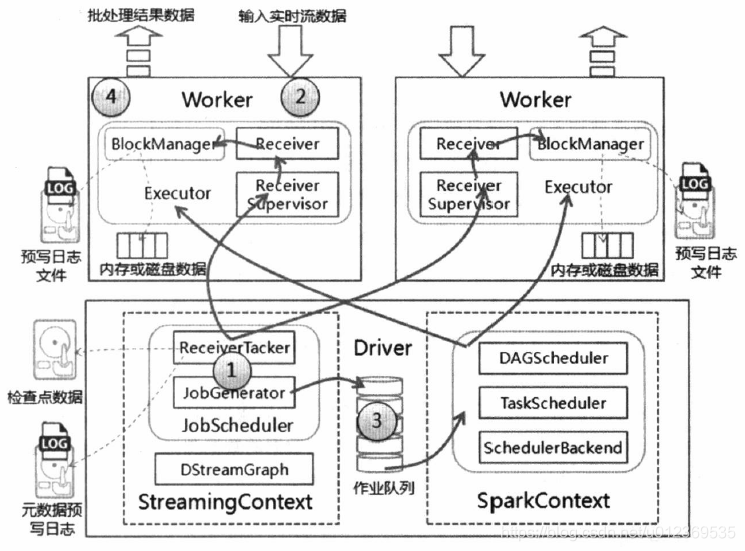
初始化StreamingContext实例,在该对象启动过程中实例化DStreamGraph和JobScheduler(ReceiverTracker+JobGenerator),
DStreamGraph用于存放DStream以及DStream之间的依赖关系等信息,
JobScheduler中包括ReceiverTracker和JobGenerator。
其中ReceiverTracker为Driver端流数据接收器(Receiver)的管理者,JobGenerator为批处理作业生成器。
在ReceiverTracker启动过程中,根据流数据接收器分发策略通知对应的Executor中的流数据接收管理器(ReceiverSupervisor)启动,再由ReceiverSupervisor启动流数据接收器Receiver。
2) 接收及存储流数据
当流数据接收器Receiver启动后,持续不断地接收实时流数据,根据传过来数据的大小进行判断,如果数据量很小,则攒多条数据成一块,然后再进行block块存储;如果数据量大,则直接进行块存储。
对于这些数据Receiver直接交给ReceiverSupervisor,由其进行数据转储操作。
数据存储完毕后,ReceiverSupervisor会把数据存储的元信息上报给ReceiverTracker;
3) 处理流数据
在StreamingContext的JobGenerator中维护一个定时器,该定时器在【批处理时间到来时】会进行生成作业的操作。在该操作中进行如下操作:
- 通知ReceiverTracker将接收到的数据进行提交,在提交时采用
synchronized关键字进行处理,保证每条数据被划入一个且只被划入一个批次中; - 要求DStreamGraph根据DSream依赖关系生成作业序列Seq[Job];
- 从第一步中ReceiverTracker获取本批次数据的元数据;
- 把批处理时间time、作业序列Seq[Job]和本批次数据的元数据包装为JobSet,调用JobScheduler.submitJobSet(JobSet)提交给JobScheduler,JobScheduler将把这些作业发送给SparkCore进行处理,由于该执行为异步,因此本步执行速度将非常快;
- 只要提交结束(不管作业是否被执行),SparkStreaming对整个系统做一个检查点(Checkpoint);
(4)输出处理结果
在Spark核心的作业队数据进行处理,处理完毕后输出到外部系统,如数据库或文件系统,输出的数据可以被外部系统所使用;
由于实时流数据的数据源源不断地流入,Spark会周而复始地进行数据处理,相应地也会持续不断地输出结果。
注意事项:
-
local模式下需要启动至少两个线程,因为只开启了一条线程(这里只有接收数据的线程,却没有处理数据的线程)
new SparkConf().setMaster("local[2]").setAppName("SimpleDemo"); -
Durations时间(batch intervals)的设置–接收数据划分批次的时间间隔,即多久触发一次job;
new StreamingContext(conf, Seconds(1)) -
业务逻辑完成后,需要有一个输出操作,将SparkStreaming处理后的数据输出到外部存储系统;
-
关于 StreamingContext 的 start()和 stop()
StreamingContext.start()// Spark Streaming应用启动之后是不能再添加业务逻辑
StreamingContext.stop()// 无参的stop方法会将SparkContext一同关闭,解决办法:stop(false)
StreamingContext.stop()// 停止之后是不能在调用start() -
DStreams(Discretized Streams–离散的流),应用在每个DStream的算子操作,会应用在DStream内的各个RDD,进而应用在RDD的各个Partition,应用在Partition中的一条条数据,最终应用到每一条记录上
参考:
https://blog.csdn.net/weixin_44735572/article/details/102831434
https://www.cnblogs.com/fishperson/p/10447033.html
https://blog.csdn.net/u012369535/article/details/93042905
https://www.imooc.com/article/268318

















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









