






文章目录
目录
引言
在日常网络数据采集中,视频资源下载是爬虫技术的典型应用场景。本文将通过8行核心代码演示如何用Python的Requests库实现视频下载功能,特别适合具备Python基础、想快速上手爬虫实践的开发者。代码已通过Bilibili CSDN资源测试(注:实际应用请遵守平台规则)
一、技术实现详解(以vscode为例)
1.1 环境准备
# 导入requests库(需提前安装:pip install requests)
import requests- 使用
requests库发送HTTP请求,这是Python最主流的网络请求库
1.2 核心代码解析(逐行注释版)
以爬取b站某歌手视频为例(也可随意选取视频),由于我们requests一般是爬取整个页面的网址,所以我们要先找到其中视频所在的真实网址
: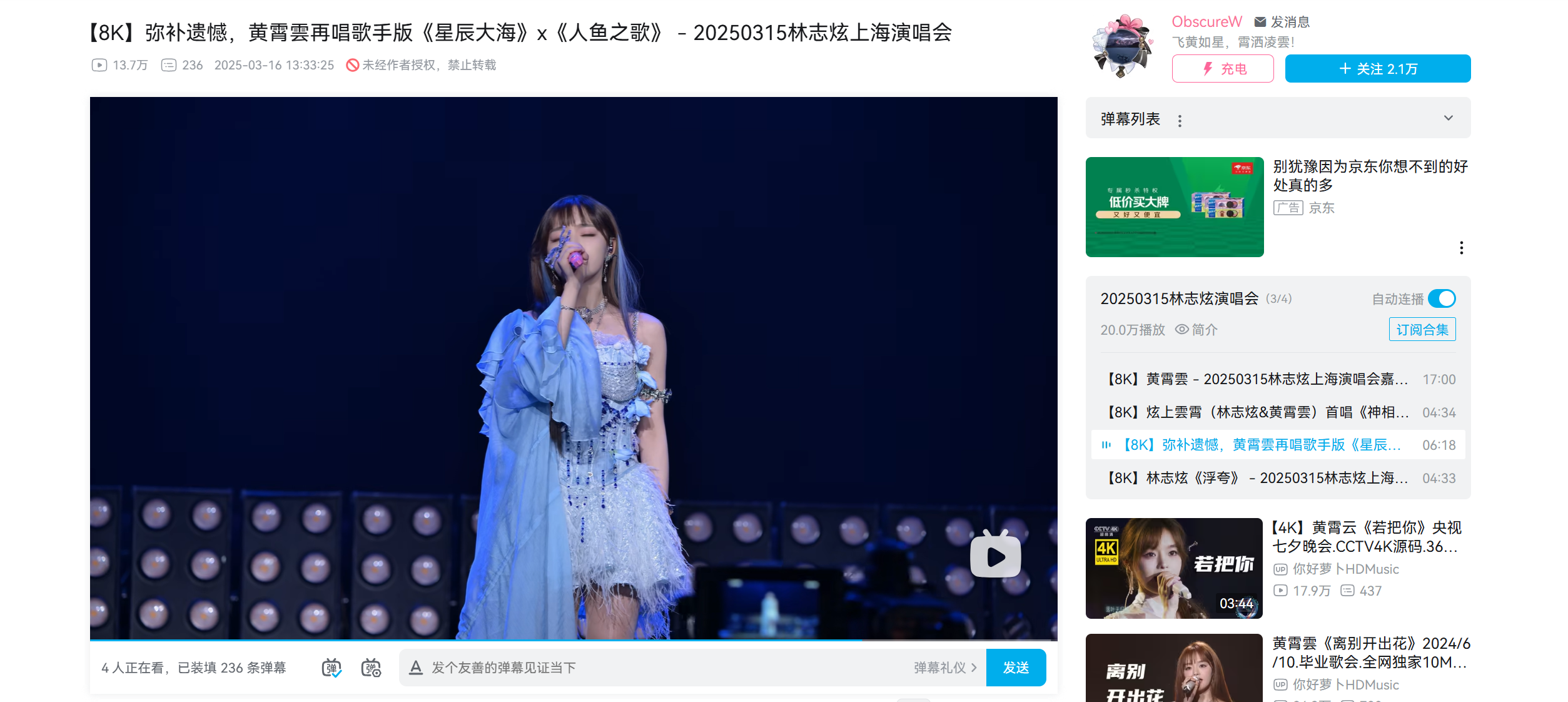
点击进入视频页面,按键盘上F12键(或者右键单击页面空白处,点击检查)
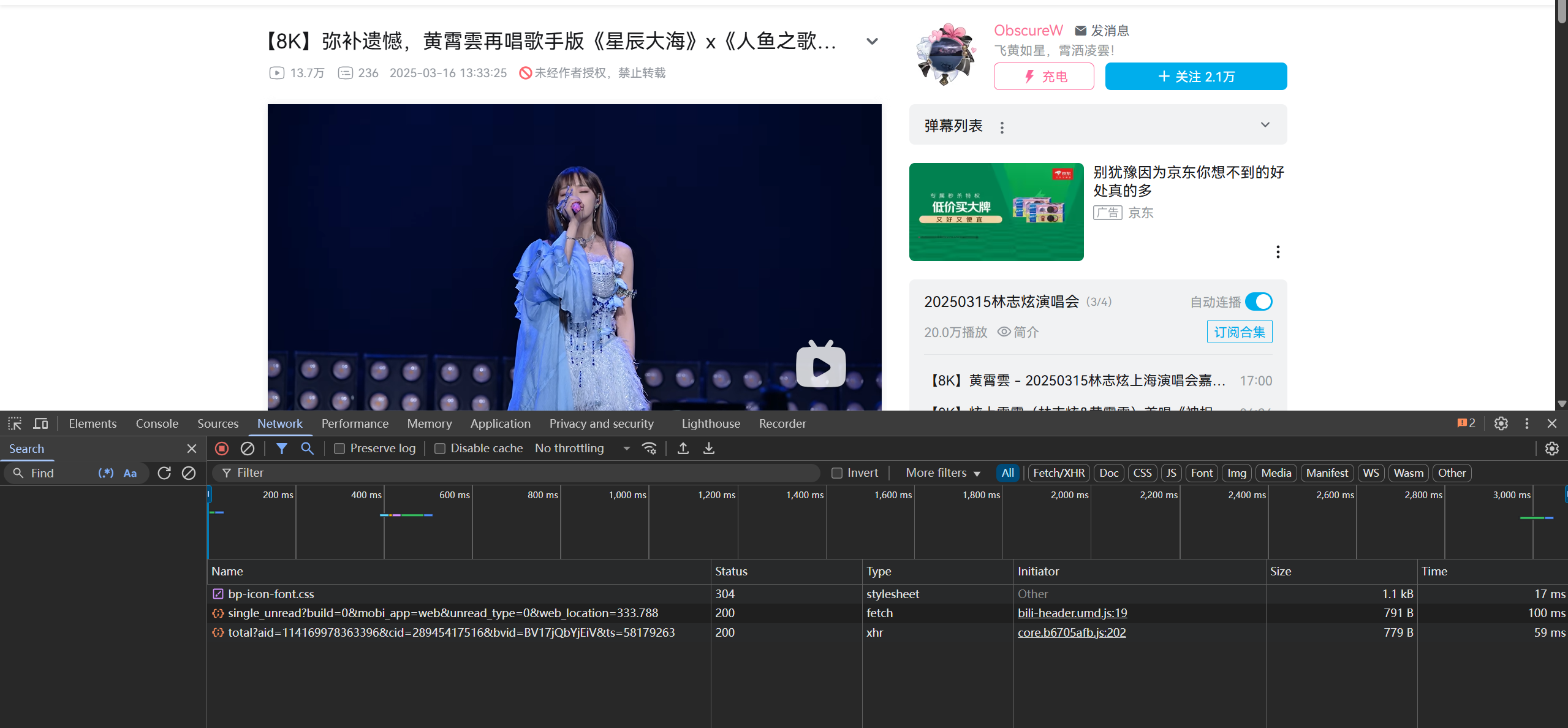
下方是页面的前端代码和一些资源,我们点击下方左上角的第二个小按钮
再点击右侧Media

此时下方会出现它的视频加载地址(若没有出现,按F5刷新即可)

单击,在Headers中找到对应的user-agent(也可在浏览器中搜索爬虫请求头):
h = {'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Mobile Safari/537.36'}
#模拟浏览器双击进入视频:
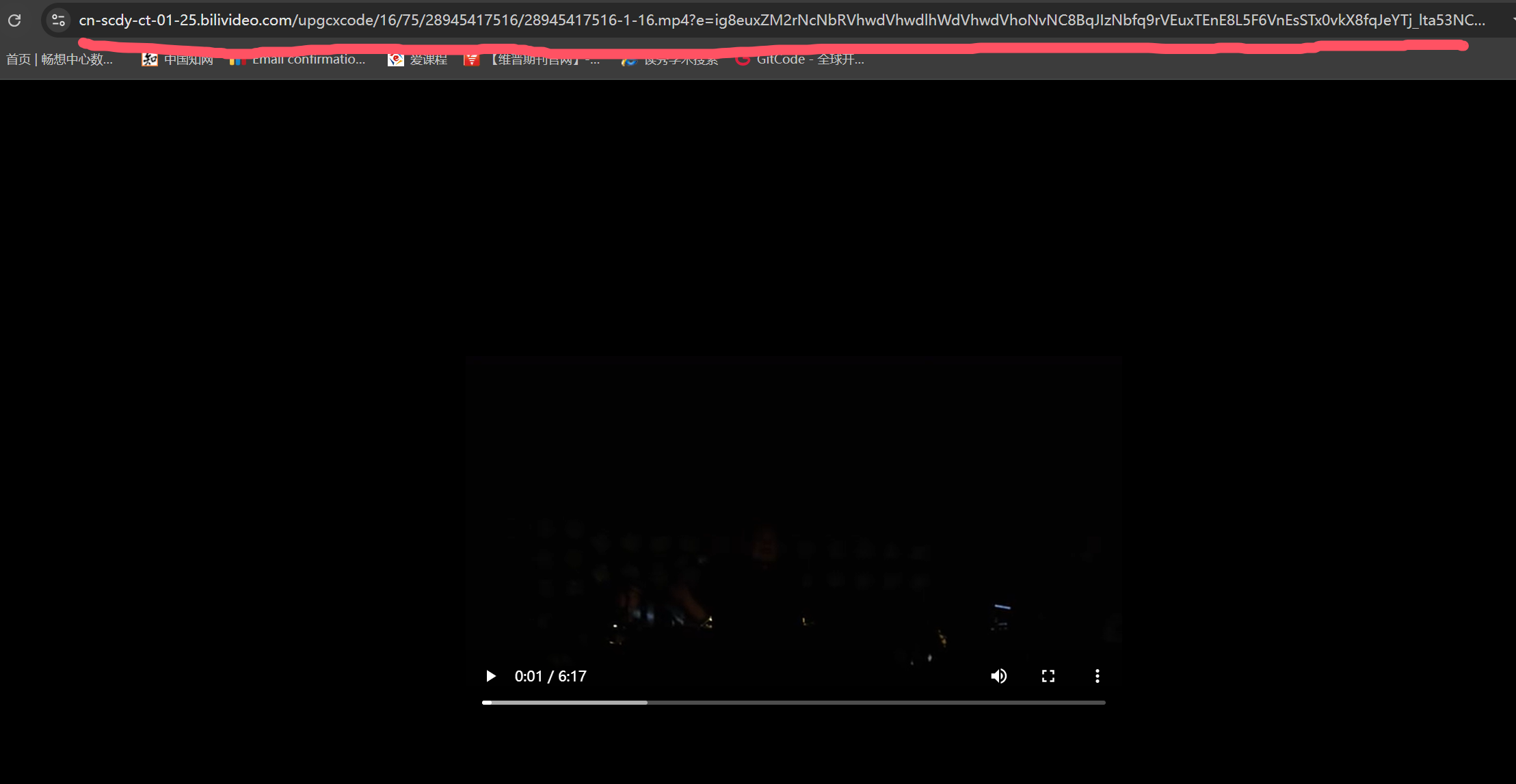
此时我们只需将这段网址复制下来即可,这时我们便找到了视频的真实网址,方便后续的爬取
url = 'https://cn-scdy-ct-01-25.bilivideo.com/upgcxcode/16/75/28945417516/28945417516-1-16.mp4?e=ig8euxZM2rNcNbRVhwdVhwdlhWdVhwdVhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1745385383&gen=playurlv2&os=bcache&oi=3657865050&trid=00007338cea3dfd54be8b26822993fe35ef5h&mid=0&platform=html5&og=hw&upsig=349e7f4243d9cb00dc10e65d46668d7f&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=88625&bvc=vod&nettype=0&f=h_0_0&bw=36692&logo=80000000'
二、完整可运行代码
import requests
# 定义要下载的视频文件的 URL
url = 'https://cn-scdy-ct-01-25.bilivideo.com/upgcxcode/16/75/28945417516/28945417516-1-16.mp4?e=ig8euxZM2rNcNbRVhwdVhwdlhWdVhwdVhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1745385383&gen=playurlv2&os=bcache&oi=3657865050&trid=00007338cea3dfd54be8b26822993fe35ef5h&mid=0&platform=html5&og=hw&upsig=349e7f4243d9cb00dc10e65d46668d7f&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=88625&bvc=vod&nettype=0&f=h_0_0&bw=36692&logo=80000000'
# 定义请求头,模拟一个安卓手机上的 Chrome 浏览器进行请求
# 这样做是为了避免有些网站会对非浏览器的请求进行限制
h = {'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Mobile Safari/537.36'}
# 发送 HTTP GET 请求到指定的 URL,并附带请求头信息
# requests.get 方法会返回一个响应对象,存储在变量 r 中
r = requests.get(url,headers=h)
# 设置响应内容的编码为根据内容自动检测到的编码
# 不过对于视频文件,编码设置在这里其实没有实际作用,因为视频是二进制数据
r.encoding = r.apparent_encoding
# 这行代码被注释掉了,它的作用是打印请求的状态码
# 状态码可以帮助我们判断请求是否成功,例如 200 表示成功,404 表示未找到资源
# print(r.status_code)
with open('csdn博客爬取视频.mp4','wb') as f:
# 将响应对象中的二进制内容写入到文件中
# r.content 是响应的二进制内容,对于视频文件,我们需要以二进制形式保存
f.write(r.content)三. 关键技术点说明
2.1 请求头伪装(Headers)
- 作用:通过
User-Agent模拟浏览器环境,突破基础反爬限制 - 扩展建议:可添加
Referer、Cookie等字段应对高级反爬策略
2.2 二进制写入模式
-
wb模式:视频/图片等非文本资源必须使用二进制写入,否则会导致文件损坏 - 文件路径:建议使用绝对路径,避免路径错误
四、注意事项
- 法律合规:下载前确认资源版权状态,遵守网站
robots.txt协议 - 反爬应对:可添加随机延时、代理IP池等进阶方案
- 资源识别:通过浏览器开发者工具(Network标签)获取真实视频地址
- 文件管理:大规模下载时建议添加文件重命名逻辑,避免覆盖
- 爬取过程:运行代码时可能因为配置不同而爬取速度不同,尤其是较大的视频爬取时间可能较长,需耐心等待
总结
以上就是今天要讲的内容,本文仅仅简单介绍了requests库的使用,爬取的视频可供我们网络不好时(车站)消遣使用,如有不足还请指出

















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









