




引言
在现代CAD/CAE应用中,处理大规模几何数据已成为常态。OpenCASCADE作为开源几何内核,虽然功能强大,但在处理百万级几何实体时往往会遇到性能瓶颈。本文通过实际案例展示如何利用多线程和多进程技术显著提升OpenCASCADE应用的性能。
基础概念
并行计算的优势
并行计算通过将任务分解为多个子任务并在多个处理单元上同时执行,能够显著减少计算时间。对于几何计算密集型任务,并行化的加速比可接近处理器的核心数量,即S=T1Tp≈pS = \frac{T_1}{T_p} \approx pS=TpT1≈p,其中T1T_1T1是单线程执行时间,TpT_pTp是ppp个线程的执行时间。
OpenCASCADE的线程安全性
OpenCASCADE的几何对象在创建和操作时通常是线程安全的,前提是不同线程操作不同的几何对象。共享资源(如标准输出)需要通过互斥锁进行保护,确保线程安全。
示例1:基础多线程点云处理
// point_cloud_parallel.cpp
#include <gp_Pnt.hxx>
#include <chrono>
#include <iostream>
#include <thread>
#include <vector>
#include <random>
#include <cmath>
using namespace std;
using namespace chrono;
// 生成随机点云
vector<gp_Pnt> generate_point_cloud(size_t num_points) {
vector<gp_Pnt> points;
points.reserve(num_points);
random_device rd;
mt19937 gen(rd());
uniform_real_distribution<> dis(-100.0, 100.0);
for (size_t i = 0; i < num_points; ++i) {
points.emplace_back(dis(gen), dis(gen), dis(gen));
}
return points;
}
// 单线程处理
void single_thread_processing(const vector<gp_Pnt>& points) {
auto start = high_resolution_clock::now();
double total_distance = 0.0;
gp_Pnt origin(0, 0, 0);
for (const auto& p : points) {
total_distance += p.Distance(origin);
}
double avg_distance = total_distance / points.size();
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
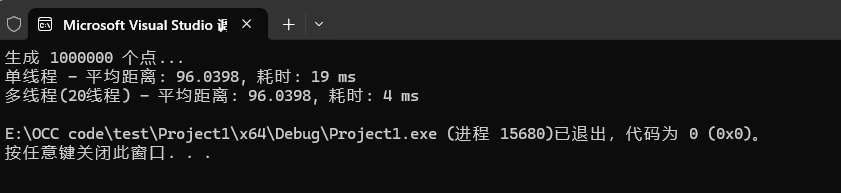
cout << "单线程 - 平均距离: " << avg_distance
<< ", 耗时: " << duration.count() << " ms" << endl;
}
// 多线程处理
void multi_thread_processing(const vector<gp_Pnt>& points) {
auto start = high_resolution_clock::now();
const size_t num_threads = thread::hardware_concurrency();
vector<thread> threads;
vector<double> partial_sums(num_threads, 0.0);
auto worker = size_t thread_id, size_t start_idx, size_t end_idx {
double local_sum = 0.0;
gp_Pnt origin(0, 0, 0);
for (size_t i = start_idx; i < end_idx; ++i) {
local_sum += points[i].Distance(origin);
}
partial_sums[thread_id] = local_sum;
};
size_t chunk_size = points.size() / num_threads;
for (size_t i = 0; i < num_threads; ++i) {
size_t start_idx = i * chunk_size;
size_t end_idx = (i == num_threads - 1) ? points.size() : start_idx + chunk_size;
threads.emplace_back(worker, i, start_idx, end_idx);
}
for (auto& t : threads) {
t.join();
}
double total_distance = 0.0;
for (double sum : partial_sums) {
total_distance += sum;
}
double avg_distance = total_distance / points.size();
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
cout << "多线程(" << num_threads << "线程) - 平均距离: " << avg_distance
<< ", 耗时: " << duration.count() << " ms" << endl;
}
int main() {
const size_t NUM_POINTS = 1000000;
cout << "生成 " << NUM_POINTS << " 个点..." << endl;
vector<gp_Pnt> points = generate_point_cloud(NUM_POINTS);
single_thread_processing(points);
multi_thread_processing(points);
return 0;
}
示例2:多线程几何体创建
// geometry_creation_parallel.cpp
#include <gp_Pnt.hxx>
#include <gp_Sphere.hxx>
#include <BRepPrimAPI_MakeSphere.hxx>
#include <TopoDS_Shape.hxx>
#include <GProp_GProps.hxx>
#include <BRepGProp.hxx>
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <mutex>
using namespace std;
using namespace chrono;
mutex cout_mutex;
// 创建球体并计算体积
void create_sphere_and_calculate(double radius, double x, double y, double z, int id) {
gp_Pnt center(x, y, z);
TopoDS_Shape sphere = BRepPrimAPI_MakeSphere(center, radius).Shape();
GProp_GProps props;
BRepGProp::VolumeProperties(sphere, props);
double volume = props.Mass();
lock_guard<mutex> lock(cout_mutex);
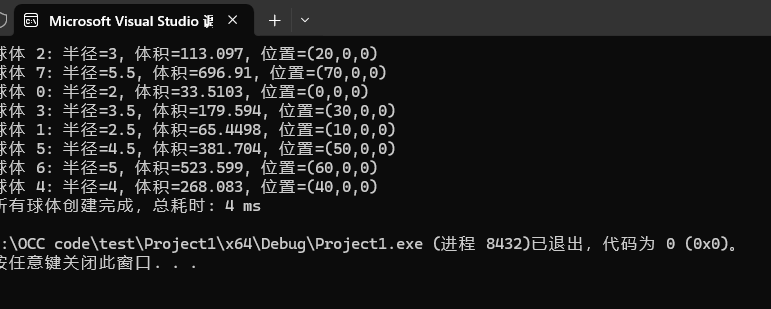
cout << "球体 " << id << ": 半径=" << radius
<< ", 体积=" << volume << ", 位置=(" << x << "," << y << "," << z << ")" << endl;
}
int main() {
const int NUM_SPHERES = 8;
vector<thread> threads;
auto start = high_resolution_clock::now();
// 创建多个球体
for (int i = 0; i < NUM_SPHERES; ++i) {
double radius = 2.0 + i * 0.5;
double x = i * 10.0;
threads.emplace_back(create_sphere_and_calculate, radius, x, 0, 0, i);
}
for (auto& t : threads) {
t.join();
}
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
cout << "所有球体创建完成,总耗时: " << duration.count() << " ms" << endl;
return 0;
}
示例3:动态负载均衡
// dynamic_load_balancing.cpp
#include <gp_Pnt.hxx>
#include <iostream>
#include <thread>
#include <vector>
#include <atomic>
#include <chrono>
#include <random>
using namespace std;
using namespace chrono;
// 生成测试点云
vector<gp_Pnt> generate_test_points(size_t count) {
vector<gp_Pnt> points;
random_device rd;
mt19937 gen(rd());
uniform_real_distribution<> dis(-50.0, 50.0);
for (size_t i = 0; i < count; ++i) {
points.emplace_back(dis(gen), dis(gen), dis(gen));
}
return points;
}
// 动态负载均衡处理
void process_with_dynamic_balance(const vector<gp_Pnt>& points) {
atomic<size_t> next_index(0);
const size_t total_points = points.size();
const size_t num_threads = thread::hardware_concurrency();
vector<thread> threads;
vector<size_t> processed_counts(num_threads, 0);
auto worker = int thread_id {
size_t current_index;
gp_Pnt origin(0, 0, 0);
while ((current_index = next_index.fetch_add(1)) < total_points) {
points[current_index].Distance(origin); // 模拟计算
processed_counts[thread_id]++;
}
};
auto start = high_resolution_clock::now();
for (size_t i = 0; i < num_threads; ++i) {
threads.emplace_back(worker, i);
}
for (auto& t : threads) {
t.join();
}
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
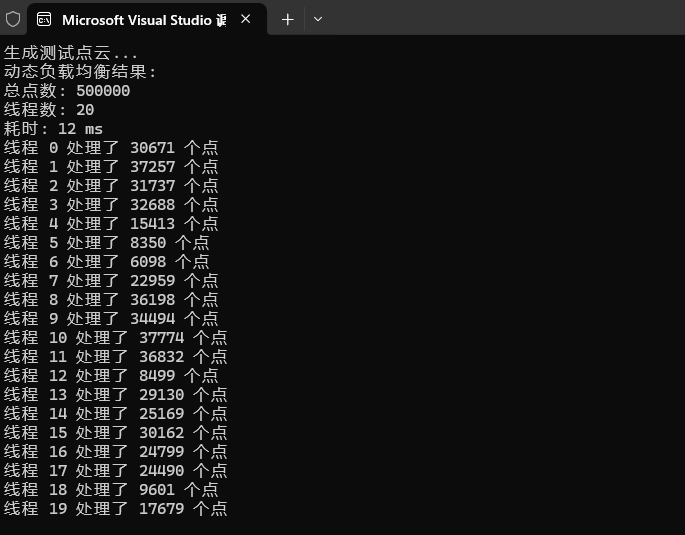
cout << "动态负载均衡结果:" << endl;
cout << "总点数: " << total_points << endl;
cout << "线程数: " << num_threads << endl;
cout << "耗时: " << duration.count() << " ms" << endl;
for (size_t i = 0; i < num_threads; ++i) {
cout << "线程 " << i << " 处理了 " << processed_counts[i] << " 个点" << endl;
}
}
int main() {
const size_t POINT_COUNT = 500000;
cout << "生成测试点云..." << endl;
vector<gp_Pnt> points = generate_test_points(POINT_COUNT);
process_with_dynamic_balance(points);
return 0;
}
示例4:多线程网格生成
// parallel_mesh_generation.cpp
#include <gp_Pnt.hxx>
#include <BRepPrimAPI_MakeSphere.hxx>
#include <BRepMesh_IncrementalMesh.hxx>
#include <TopoDS_Shape.hxx>
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <mutex>
using namespace std;
using namespace chrono;
mutex output_mutex;
// 生成球体网格
void generate_sphere_mesh(double radius, double x, double y, double z, double deflection) {
gp_Pnt center(x, y, z);
TopoDS_Shape sphere = BRepPrimAPI_MakeSphere(center, radius).Shape();
// 生成网格
BRepMesh_IncrementalMesh mesher(sphere, deflection);
lock_guard<mutex> lock(output_mutex);
cout << "生成球体网格: 半径=" << radius
<< ", 精度=" << deflection
<< ", 位置=(" << x << "," << y << "," << z << ")" << endl;
}
int main() {
const int NUM_OBJECTS = 6;
vector<thread> threads;
cout << "开始并行网格生成..." << endl;
auto start = high_resolution_clock::now();
// 创建不同精度的网格
double positions[6][3] = {
{0, 0, 0}, {20, 0, 0}, {40, 0, 0},
{0, 20, 0}, {20, 20, 0}, {40, 20, 0}
};
for (int i = 0; i < NUM_OBJECTS; ++i) {
double radius = 5.0 + i * 1.0;
double deflection = 0.5 + i * 0.1;
threads.emplace_back(generate_sphere_mesh, radius,
positions[i][0], positions[i][1], positions[i][2],
deflection);
}
for (auto& t : threads) {
t.join();
}
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
cout << "所有网格生成完成,总耗时: " << duration.count() << " ms" << endl;
return 0;
}
示例5:线程安全的几何操作
// thread_safe_operations.cpp
#include <gp_Pnt.hxx>
#include <gp_Vec.hxx>
#include <gp_Trsf.hxx>
#include <BRepBuilderAPI_Transform.hxx>
#include <TopoDS_Shape.hxx>
#include <BRepPrimAPI_MakeBox.hxx>
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <mutex>
#include <random>
using namespace std;
using namespace chrono;
mutex result_mutex;
vector<double> results;
// 线程安全的几何变换操作
void transform_geometry(int thread_id, double translation_x) {
// 每个线程创建自己的几何体
TopoDS_Shape box = BRepPrimAPI_MakeBox(10.0, 5.0, 3.0).Shape();
// 创建变换
gp_Trsf transformation;
transformation.SetTranslation(gp_Vec(translation_x, thread_id * 2.0, 0));
// 应用变换
BRepBuilderAPI_Transform transformer(box, transformation);
TopoDS_Shape transformed_shape = transformer.Shape();
// 计算体积(简单模拟)
double volume = 10.0 * 5.0 * 3.0; // 实际应该用BRepGProp
{
lock_guard<mutex> lock(result_mutex);
results.push_back(volume);
cout << "线程 " << thread_id << ": 变换完成,体积=" << volume << endl;
}
}
int main() {
const int NUM_OPERATIONS = 8;
vector<thread> threads;
cout << "开始并行几何变换..." << endl;
auto start = high_resolution_clock::now();
random_device rd;
mt19937 gen(rd());
uniform_real_distribution<> dis(5.0, 25.0);
for (int i = 0; i < NUM_OPERATIONS; ++i) {
double translation = dis(gen);
threads.emplace_back(transform_geometry, i, translation);
}
for (auto& t : threads) {
t.join();
}
auto end = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end - start);
double total_volume = 0.0;
for (double vol : results) {
total_volume += vol;
}
cout << "所有变换完成,总耗时: " << duration.count() << " ms" << endl;
cout << "总体积和: " << total_volume << endl;
return 0;
}
实际工程应用建议
内存管理优化
在多线程环境中,避免频繁的内存分配和释放。使用对象池或预分配策略来减少内存分配开销。
缓存友好设计
确保数据访问模式是缓存友好的。对于几何数据,可以使用SoA(Structure of Arrays)而不是AoS(Array of Structures)布局来提高缓存利用率。
异步I/O操作
对于文件读写等I/O密集型操作,使用异步I/O可以避免阻塞工作线程,提高整体吞吐量。
结论
OpenCASCADE结合多线程和多进程技术能够显著提升几何处理应用的性能。通过合理的任务分解、负载均衡和内存管理策略,可以实现接近线性的加速比。在实际工程应用中,需要根据具体场景选择合适的并行模式,并注意线程安全和资源管理问题。
多线程适用于计算密集型任务,如几何计算和网格生成;多进程适用于需要更好隔离性的任务,如批量文件处理。通过结合这两种技术,可以构建出高性能、高可靠性的CAD/CAE应用系统。
未来的工作可以探索GPU加速与OpenCASCADE的结合,以及分布式计算在超大规模几何处理中的应用,进一步推动几何计算性能的边界。


















 8305
8305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









