






 本文分析了LendingClub的贷款数据,包括公司经营规模、坏账率、贷款人特征与违约率的关系。13年贷款坏账率为15.6%,15-17年经营规模停滞。贷款人中,按揭和租住者占比高,年收入平均为8万美元,负债收入比低。年收入、信用等级和房屋所有权与违约率负相关,而负债收入比、低信用产品数量与违约率正相关。
本文分析了LendingClub的贷款数据,包括公司经营规模、坏账率、贷款人特征与违约率的关系。13年贷款坏账率为15.6%,15-17年经营规模停滞。贷款人中,按揭和租住者占比高,年收入平均为8万美元,负债收入比低。年收入、信用等级和房屋所有权与违约率负相关,而负债收入比、低信用产品数量与违约率正相关。
开门见山
目录:
1 背景介绍
2 基本数据处理
3 公司总体分析
4 贷款人分析
5 用户特征与违约率的关系
结论:
没有特别提到年份的地方,默认是18年。
公司:
从贷款数量上来看,07年到15年,经营规模发展得很快,但是15年到18年,经营规模没有明显提高,尤其15年到17年,基本没有进步。
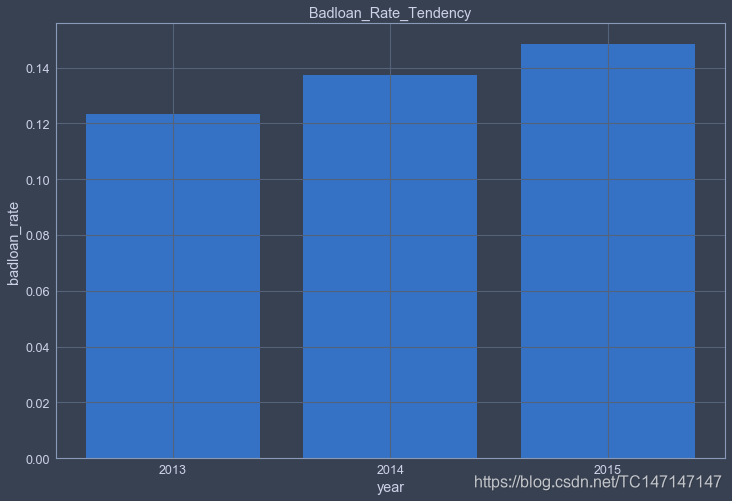
13年的整体坏账率15.6%,13年到15年的3年期贷款坏账率逐年上升趋势明显。
从贷款规模上看,公司没有明显的淡旺季,年初偏低一点点。
公司对贷款人的信息并不是全部验证,可能由于公司对于申报信息未验证的贷款人审核更加严格,他们的违约率甚至低于信息已验证的贷款人。
贷款人:
住房以按揭和租住为主,两者合计占比超过85%。
工作年限偏低。
贷款人的平均年收入为8万美元,超过美国平均水平的两倍。贷款人的负债收入比不高,均值为21.9%,中位数为17.7%。单笔借贷金额比较集中在1到2万,中位数1.6万,最高也只有4万,贷款金额不高。
贷款人平均在用的信用产品数量为23。
贷款人特征与违约率的关系:
年收入越高,越不容易违约
负债收入比高于20时,违约率与dti正相关。但是也发现dti最低的十分之一,居然是违约率最高的人群。
工作年限对贷款人违约率的影响比较小,工作超过九年的贷款人违约率相对偏低,未填报工作年限的贷款人违约率较高。
当正在使用的信用产品数量较低时,违约率相对较高;当这个数量较高时,其与违约率关系不大。
能看出对信用评级比较差的,F、G这类的贷款人,还款期还没结束,就有超过10%会违约或拖欠还款。
相对于租房和已有房的贷款人,按揭买房的贷款人违约率低很多。
贷款目的:去除小样本类别后,small business的贷款人违约率最高。
背景介绍
LendingClub是美国最大的网络借贷平台,2006年成立,2014年12月在纽交所上市,以15美元发行,首日报收23.43美元,较发行价大涨56.20%。在18年年底跌至不到2.5美元,目前在10美元左右。
LendingClub的核心竞争力之一就是其成熟有效的基于FICO信用数据的风控模型。FICO信用分是由美国个人消费信用评估公司开发出的一种个人信用评级法,已经得到美国社会广泛接受。借款人提交贷款申请,LendingClub的系统会进行初步筛选,最终将借款人归入A至G共7个等级,每个等级又包含1至5五个子级,共有35个贷款等级。LendingClub会根据借款人的信用报告对每笔借款申请制定不同的借款利率,实行差别定价,等级越高,利率越低。
身为美国P2P龙头,LendingClub在上市前一直高速发展,2014年因收购Springstone而陷入巨额亏损,但其真正陨落是因为其创始人违规事件:LendingClub创始人Renaud Laplanche为达成2016年业绩目标篡改了两笔总额2200万美元贷款的申请日期,并将其违规出售给了机构投资者。2016年5月,Renaud Laplanche引咎辞职,直接导致其单日股价暴跌35%。
基本数据处理
这里用到的数据源在Kaggle上:https://www.kaggle.com/wendykan/lending-club-loan-data
或者去LendingClub官网也能找到,可以选择下载的具体年份,灵活一些,Kaggle只能全部下载。
这里我只选取了10个重要特征,原数据特征有140多个。
from IPython.core.interactiveshell import InteractiveShell
from jupyterthemes import jtplot
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from time import time
import datetime
#魔法函数
%matplotlib inline
#matplotlib 支持中文
#plt.rcParams['font.sans-serif'] = ['SimHei']
# matplotlib 正常显示负号
#plt.rcParams['axes.unicode_minus'] = False
#dataframe显示不换行
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 200)
pd.set_option('display.max_columns', 200)
#选择一个绘图主题与本身主题对应
jtplot.style(theme='oceans16')
#一个cell显示多个输出结果
InteractiveShell.ast_node_interactivity = "all"
data = pd.read_csv('PendingClubData.csv', header=0, parse_dates=['issue_d'])
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2260668 entries, 0 to 2260667
Data columns (total 13 columns):
# Column Dtype
--- ------ -----
0 issue_d datetime64[ns]
1 annual_inc float64
2 term object
3 loan_amnt int64
4 int_rate float64
5 verification_status object
6 home_ownership object
7 emp_length object
8 purpose object
9 grade object
10 total_acc float64
11 dti float64
12 loan_status object
dtypes: datetime64[ns](1), float64(4), int64(1), object(7)
memory usage: 224.2+ MB
| 字段名 | 具体含义 | 值集 |
|---|---|---|
| annual_inc | 贷款人申报年收入 | - |
| verification_status | 填报信息是否经过验证 | Verified/Source Verified/Not Verified |
| issue_d | 贷款发放月份 | - |
| dti | 债务收入比 | - |
| total_acc | 贷款人正在使用的信用产品数量 | - |
| home_ownership | 贷款人房屋使用类型 | MORTGAGE/RENT/OWN/ANY/OTHER/NONE |
| emp_length | 工作年限 | - |
| purpose | 贷款目的 | - |
| term | 还款时间 | 3年/5年 |
| loan_amnt | 贷款本金额 | - |
| grade | 信用等级 | A到G |
| loan_status | 贷款状态 | - |
| loan_status的值集 | 具体含义 |
|---|---|
| Fully Paid | 结清,完全到期还清 |
| Current | 正常还款,还未到最后一个还款期 |
| Charged Off | 坏账 |
| Late (31-120 days) | 逾期31—120天 |
| In Grace Period | 处于宽限期 |
| Late (16-30 days) | 逾期16—30天 |
| Default | 违约 |
| issued | 审批通过 |
观察是否有缺失值
data.isnull().sum()
issue_d 0
annual_inc 4
term 0
loan_amnt 0
int_rate 0
verification_status 0
home_ownership 0
emp_length 146907
purpose 0
grade 0
total_acc 29
dti 1711
loan_status 0
dtype: int64
看下债务收入比dti的缺失值是不是由于收入很低接近0产生的
data.loc[data['dti'].isnull(), 'annual_inc'].sum()
111.36
dti有缺失值1711行的所有annual_inc年收入加一起只有100万,可以认为是收入过低造成的dti缺失值,处理方法是:填充缺失值为该特征最大值。
total_acc和emp_length缺失值填充为0
annual_inc删除缺失值
data[['emp_length']] = data[['emp_length']].fillna('unknown')
data = data.loc[(data['annual_inc'].notnull()) & (data['total_acc'].notnull()), :]
data.loc[data['dti'].isnull(), 'dti'] = data['dti'].max()
data.isnull().sum()
issue_d 0
annual_inc 0
term 0
loan_amnt 0
int_rate 0
verification_status 0
home_ownership 0
emp_length 0
purpose 0
grade 0
total_acc 0
dti 0
loan_status 0
dtype: int64
填充缺失值后,把index转换为正常的从0开始依次增加1
data = data.reset_index(drop=True)
data.head()
| issue_d | annual_inc | term | loan_amnt | int_rate | verification_status | home_ownership | emp_length | purpose | grade | total_acc | dti | loan_status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-12-01 | 55000.0 | 36 months | 2500 | 13.56 | Not Verified | RENT | 10+ years | debt_consolidation | C | 34.0 | 18.24 | Current |
| 1 | 2018-12-01 | 90000.0 | 60 months | 30000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 44.0 | 26.52 | Current |
| 2 | 2018-12-01 | 59280.0 | 36 months | 5000 | 17.97 | Source Verified | MORTGAGE | 6 years | debt_consolidation | D | 13.0 | 10.51 | Current |
| 3 | 2018-12-01 | 92000.0 | 36 months | 4000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 13.0 | 16.74 | Current |
| 4 | 2018-12-01 | 57250.0 | 60 months | 30000 | 16.14 | Not Verified | MORTGAGE | 10+ years | debt_consolidation | C | 26.0 | 26.35 | Current |
data加特征‘year’和‘month’,方便后续统计分析
data['year'] = data[['issue_d']].apply(lambda x: x.dt.year)
data['month'] = data[['issue_d']].apply(lambda x: x.dt.month)
data.head()
| issue_d | annual_inc | term | loan_amnt | int_rate | verification_status | home_ownership | emp_length | purpose | grade | total_acc | dti | loan_status | year | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-12-01 | 55000.0 | 36 months | 2500 | 13.56 | Not Verified | RENT | 10+ years | debt_consolidation | C | 34.0 | 18.24 | Current | 2018 | 12 |
| 1 | 2018-12-01 | 90000.0 | 60 months | 30000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 44.0 | 26.52 | Current | 2018 | 12 |
| 2 | 2018-12-01 | 59280.0 | 36 months | 5000 | 17.97 | Source Verified | MORTGAGE | 6 years | debt_consolidation | D | 13.0 | 10.51 | Current | 2018 | 12 |
| 3 | 2018-12-01 | 92000.0 | 36 months | 4000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 13.0 | 16.74 | Current | 2018 | 12 |
| 4 | 2018-12-01 | 57250.0 | 60 months | 30000 | 16.14 | Not Verified | MORTGAGE | 10+ years | debt_consolidation | C | 26.0 | 26.35 | Current | 2018 | 12 |
增加特征更清晰的显示verification_status和loan_status
data['verify'] = data['verification_status']
data['label'] = data['loan_status']
mapping_dict = {'label': {'Current': 0, 'Fully Paid': 0,
'Charged Off': 1, 'Late (31-120 days)': 1, 'Default': 1,
'Late (16-30 days)': 1, 'In Grace Period': 1},
'verify': {'Source Verified': 1, 'Verified': 1, 'Not Verified': 0}
}
data = data.replace(mapping_dict)
data.head()
| issue_d | annual_inc | term | loan_amnt | int_rate | verification_status | home_ownership | emp_length | purpose | grade | total_acc | dti | loan_status | year | month | verify | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-12-01 | 55000.0 | 36 months | 2500 | 13.56 | Not Verified | RENT | 10+ years | debt_consolidation | C | 34.0 | 18.24 | Current | 2018 | 12 | 0 | 0 |
| 1 | 2018-12-01 | 90000.0 | 60 months | 30000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 44.0 | 26.52 | Current | 2018 | 12 | 1 | 0 |
| 2 | 2018-12-01 | 59280.0 | 36 months | 5000 | 17.97 | Source Verified | MORTGAGE | 6 years | debt_consolidation | D | 13.0 | 10.51 | Current | 2018 | 12 | 1 | 0 |
| 3 | 2018-12-01 | 92000.0 | 36 months | 4000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 13.0 | 16.74 | Current | 2018 | 12 | 1 | 0 |
| 4 | 2018-12-01 | 57250.0 | 60 months | 30000 | 16.14 | Not Verified | MORTGAGE | 10+ years | debt_consolidation | C | 26.0 | 26.35 | Current | 2018 | 12 | 0 | 0 |
公司总体分析
贷款数量
data['year'].value_counts()
2018 495242
2017 443579
2016 434407
2015 421095
2014 235629
2013 134814
2012 53367
2011 21721
2010 12537
2009 5281
2008 2393
2007 574
Name: year, dtype: int64
从贷款数量上来看,07年到15年,经营规模发展得很快,但是15年到18年,经营规模没有明显提高,尤其15年到17年,基本没有进步,这也部分解释了为何LendingClub在14年年底上市时IPO价格为15美元,18年年底股价跌到了不到3美元。
坏账率
关注下LendingClub的坏账率,这里我们只看2013年,为什么不看最近的年份呢,因为LendingClub的贷款期限分为两种:3年期和5年期,13年发行的贷款都到期了,可以观察到最真实的坏账率,如果看18年的,那么只能看到宽口径的逾期率,意义不大,毕竟拖欠跟最终彻底跑路是两个意思。另外公司在12年对贷款人的信用门槛调低了一些,之后没有太大的调整,所以观察13年是比较合适的。
# 计算2013年贷款的坏账比率
data_2013 = data[data['year'] == 2013]
data_2013['loan_status'].value_counts()['Charged Off'] / \
data_2013['loan_status'].count()
0.15593336003679142
超过15%的坏账比率实在太高,当然LendingClub这类公司还会将出现坏账的贷款委托给专业催收公司,这些贷款金额并不是彻底的损失。我们可以比较一下13年到15年这三年的三年期贷款坏账比率,看是否有增高的趋势
data_2014 = data[data['year'] == 2014]
data_2015 = data[data['year'] == 2015]
badloan_2013 = data_2013[(data_2013['term'] == ' 36 months') & (data_2013['loan_status'] == 'Charged Off')
]['loan_status'].count()/data_2013[(data_2013['term'] == ' 36 months')]['loan_status'].count()
badloan_2014 = data_2014[(data_2014['term'] == ' 36 months') & (data_2014['loan_status'] == 'Charged Off')
]['loan_status'].count()/data_2014[(data_2014['term'] == ' 36 months')]['loan_status'].count()
badloan_2015 = data_2015[(data_2015['term'] == ' 36 months') & (data_2015['loan_status'] == 'Charged Off')
]['loan_status'].count()/data_2015[(data_2015['term'] == ' 36 months')]['loan_status'].count()
badloan_2013, badloan_2014, badloan_2015
(0.12325984346059628, 0.13726394783785445, 0.1484887330359886)
做个图直观地看下13到15年坏账比率趋势,可以看出是一个上涨的趋势,LendingClub公司对坏账的控制做的并不好,从这点来看,在15年爆出违规丑闻不是偶然的。16到18年因为没有统一比较的口径,就不展示了。
plt.style.use({'figure.figsize': (12, 8)})
plt.title('Badloan_Rate_Tendency')
plt.bar([2013, 2014, 2015], [badloan_2013, badloan_2014, badloan_2015])
plt.xticks([2013, 2014, 2015])
plt.xlabel('year')
plt.ylabel('badloan_rate')
淡旺季
LendingClub公司有没有淡旺季呢?
data_2018 = data[data['year'] == 2018]
data_2018 = data_2018.reset_index(drop=True)
data_2017 = data[data['year'] == 2017]
data_2017 = data_2017.reset_index(drop=True)
data_2018_month = data_2018.groupby('month')['loan_amnt'].agg([
'count', 'sum']) # 贷款笔数与放贷金额
data_2018_month['avg'] = data_2018_month['sum']/data_2018_month['count']
f, (ax1, ax2, ax3) = plt.subplots(3, 1, sharex=True)
x = data_2018_month.index # 月份month
y1 = data_2018_month['count'] # 贷款笔数
y2 = data_2018_month['sum'] # 贷款金额
y3 = data_2018_month['avg'] # 平均每笔贷款的金额
sns.barplot(x, y1, ax=ax1)
ax1.set_xlabel('month')
ax1.set_ylabel('loan_count')
sns.barplot(x, y2, ax=ax2)
ax2.set_ylabel('loan_amount')
sns.barplot(x, y3, ax=ax3)
ax3.set_ylabel('loan_avg')
sns.despine(bottom=True)
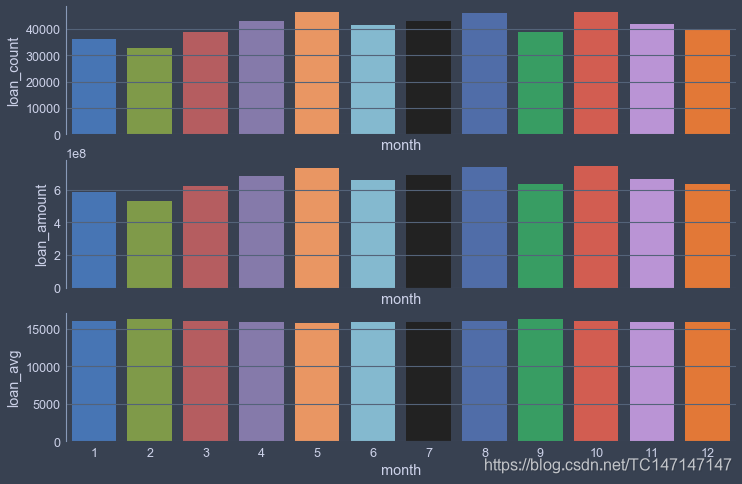
2018年每个月份的贷款笔数和贷款总额有小幅波动,但平均每笔贷款额是基本保持在16K不变的,可以认为贷款总额的波动是由于贷款笔数波动产生的。可以认为2018年Lending Club各月的业绩比较均衡,没有特别明显的淡旺季,可以说年初是偏淡季的,但是最高的5月与最低的2月也没有差出一倍。再看下2017年,确认下这种情况是2018年独有的还是正常情况。
data_2017_month = data_2017.groupby('month')['loan_amnt'].agg([
'count', 'sum']) # 贷款笔数与放贷金额
data_2017_month['avg'] = data_2017_month['sum']/data_2017_month['count']
f, (ax1, ax2, ax3) = plt.subplots(3, 1, sharex=True)
x = data_2017_month.index # 月份month
y1 = data_2017_month['count'] # 贷款笔数
y2 = data_2017_month['sum'] # 贷款金额
y3 = data_2017_month['avg'] # 平均每笔贷款的金额
sns.barplot(x, y1, ax=ax1)
ax1.set_xlabel('month')
ax1.set_ylabel('loan_count')
sns.barplot(x, y2, ax=ax2)
ax2.set_ylabel('loan_amount')
sns.barplot(x, y3, ax=ax3)
ax3.set_ylabel('loan_avg')
sns.despine(bottom=True)
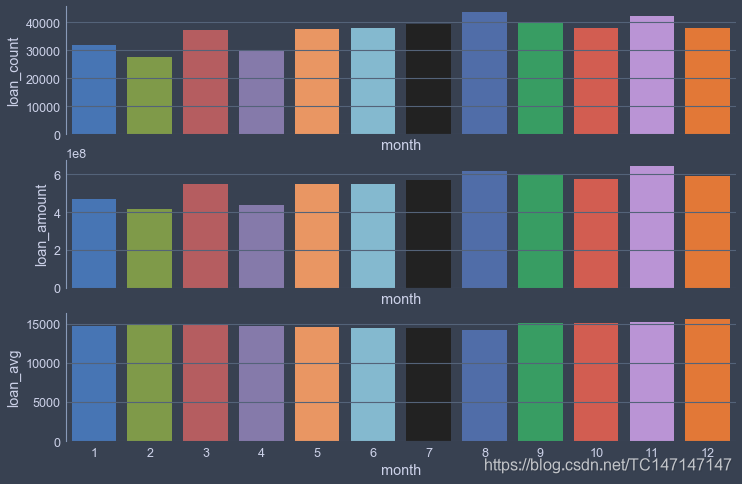
现在基本可以得出结论:LendingClub公司在借贷总额上没有明显的淡旺季,年初的借贷总额相对较少,每个月的每笔贷款平均金额比较固定。
信息验证
下面研究一下verify这个特征。对于贷款者自行申报的各种信息,LendingClub居然有不验证的情况,我们可以分析一下信息经过验证的贷款和未经过验证的贷款在是否违约上有没有差别,差别有多大。LendingClub的某高管曾说信息未验证的贷款,反而违约率更低,我们看下他说的对不对。
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.barplot(x='verify', y='label', data=data_2018)
plt.xticks([0, 1], ['未经验证', '经验证'])
plt.title('贷款人信息验证对违约率的影响')
plt.ylabel('违约率')
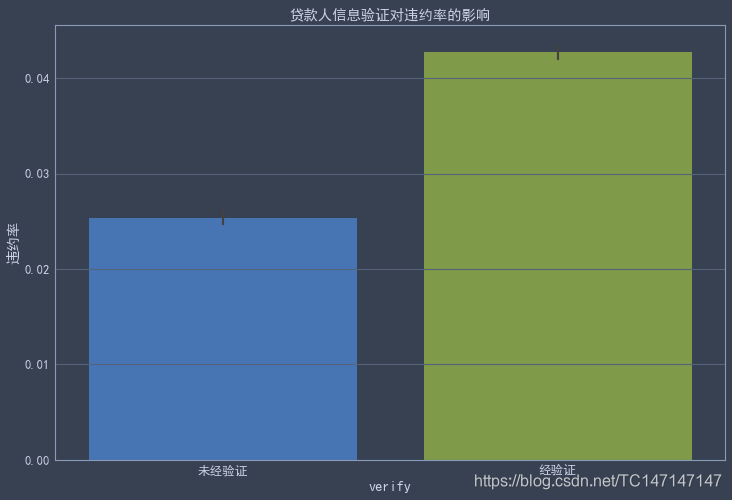
从图中可以得出反直觉的结论:信息未经过验证的贷款,违约比率反而相对低很多。从这个角度讲,部分贷款人的信息未经过审核验证并不会对公司业绩产生影响。
如何看待这个结论呢?我认为有可能是因为LendingClub公司对于贷款人信息未经验证的给予了更高的借款门槛,信用定级更严格。
贷款人分析
贷款人的房屋所有权情况
tmp = data_2018['home_ownership'].value_counts()
ratio = [tmp[i] for i in range(0, 4)]
idx = tmp.index.tolist()
plt.pie(ratio, labels=idx, autopct='%1.1f%%',
counterclock=False, startangle=90)
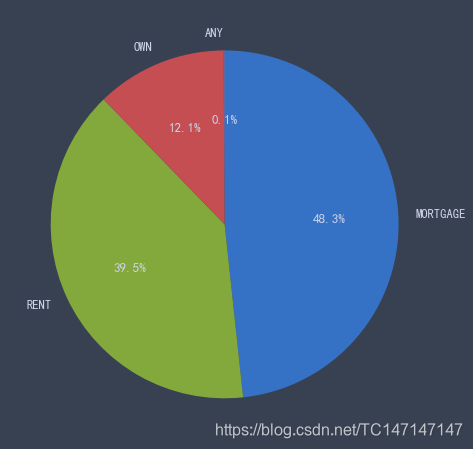
LendingClub的用户以按揭和租住为主,两者加一起超过85%。
贷款人工作年限
tmp = data_2018['emp_length'].value_counts()
ratio = [tmp[tmp.index[i]] for i in range(12)]
idx = tmp.index.tolist()
plt.pie(ratio, labels=idx, autopct='%1.1f%%',
counterclock=False, startangle=90)
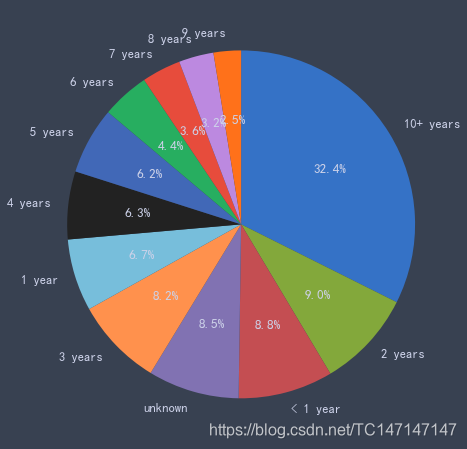
从图中看是占最大比例的是工作年限超过十年的人,但是考虑到其他贷款人的工作年限是按年来划分的,口径窄很多,实际上是工作年限越少,贷款人数占比越多,即工作年限与贷款人数占比为负相关的关系。
贷款人的收入、负债收入比、贷款金额
对于贷款人的贷款金额画密度图来观察。
sns.kdeplot(data_2018['loan_amnt'], shade=True)
<matplotlib.axes._subplots.AxesSubplot at 0x1d21ef7e0c8>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-veJTOydw-1583673430923)(output_52_1.png)]
data_2018[['annual_inc', 'dti', 'loan_amnt']].describe()
| annual_inc | dti | loan_amnt | |
|---|---|---|---|
| count | 4.952420e+05 | 495242.000000 | 495242.000000 |
| mean | 8.009399e+04 | 21.907394 | 16025.020394 |
| std | 8.887161e+04 | 51.037402 | 10138.075023 |
| min | 0.000000e+00 | 0.000000 | 1000.000000 |
| 25% | 4.600000e+04 | 11.440000 | 8000.000000 |
| 50% | 6.600000e+04 | 17.740000 | 14000.000000 |
| 75% | 9.600000e+04 | 25.090000 | 22000.000000 |
| max | 9.930475e+06 | 999.000000 | 40000.000000 |
贷款人的平均年收入为8万美元,相比于美国人2018年平均年收入3.6万,贷款人收入是偏高的,并没有想象中的都是穷人。贷款人的负债收入比的均值为21.9%,中位数为17.7%,也不算高。。这很可能是因为LendingClub公司在审核时门槛较高,所以真正的穷人因为没有还钱的可能所以被阻挡在外了。
从图表中可以看出单笔借贷金额比较集中在1到2万,中位数1.6万,最高也只有4万,相比于贷款人的平均收入8万,贷款金额不高。
贷款人在用的信用产品数量
data_2018[['total_acc']].describe()
| total_acc | |
|---|---|
| count | 495242.000000 |
| mean | 22.624151 |
| std | 12.104004 |
| min | 2.000000 |
| 25% | 14.000000 |
| 50% | 21.000000 |
| 75% | 29.000000 |
| max | 160.000000 |
贷款人平均在用的信用产品数量为23,中位数也相差不多,贷款人使用信用产品的数量偏多。
贷款人特征与违约率的关系
年收入
tmp = data_2018[['annual_inc','label']].copy()
tmp['inc_qcut'] = pd.qcut(tmp['annual_inc'],10)
sns.barplot('inc_qcut','label',data=tmp)
plt.xticks(rotation=45)
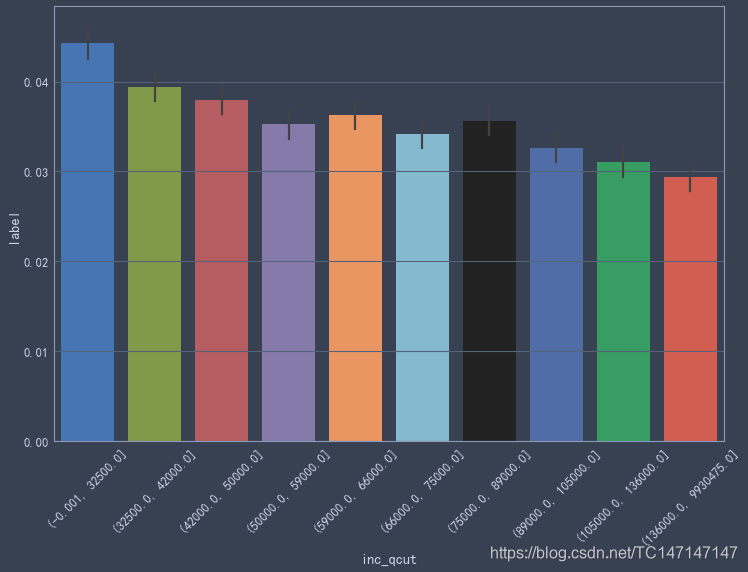
比较符合直觉,年收入越高,越不容易违约
负债收入比
tmp = data_2018[['dti', 'label']].copy()
tmp['dti_qcut'] = pd.qcut(tmp['dti'], q=10)
sns.barplot(tmp['dti_qcut'], tmp['label'])
plt.xticks(rotation=45)
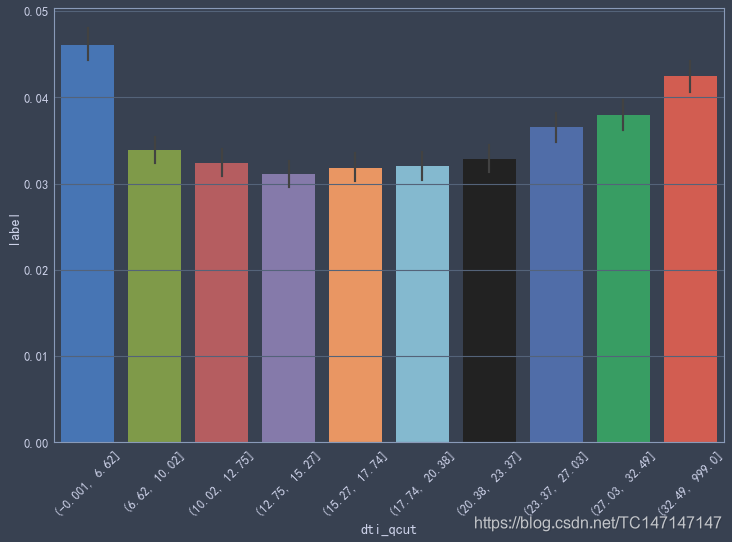
从图中可以发现dti高于20时,违约率与dti正相关。
但是也发现dti最低的十分之一,居然是违约率最高的人群,尝试改变分箱数量,发现q增大时,dti最低的部分一枝独秀,高得离谱,这里还不理解时为什么。
工作年限
sns.barplot(data_2018['emp_length'], data_2018['label'], order=[
'unknown', '< 1 year', '1 year', '2 years', '3 years', '4 years',
'5 years', '6 years', '7 years', '8 years', '9 years', '10+ years'])
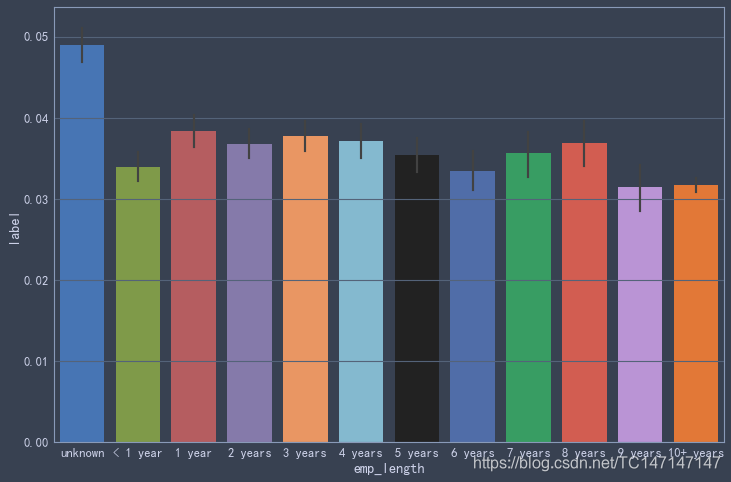
未填报工作年限的贷款人违约率相当高,而不同工作年限的贷款人违约率其实差不多,说明工作年限对贷款人违约率的影响比较小,工作超过九年的贷款人违约率相对偏低。
信用产品数量
tmp = data_2018[['total_acc', 'label']].copy()
tmp['acc_qcut'] = pd.qcut(tmp['total_acc'], 10)
sns.barplot(tmp['acc_qcut'], tmp['label'])
plt.xticks(rotation=45)
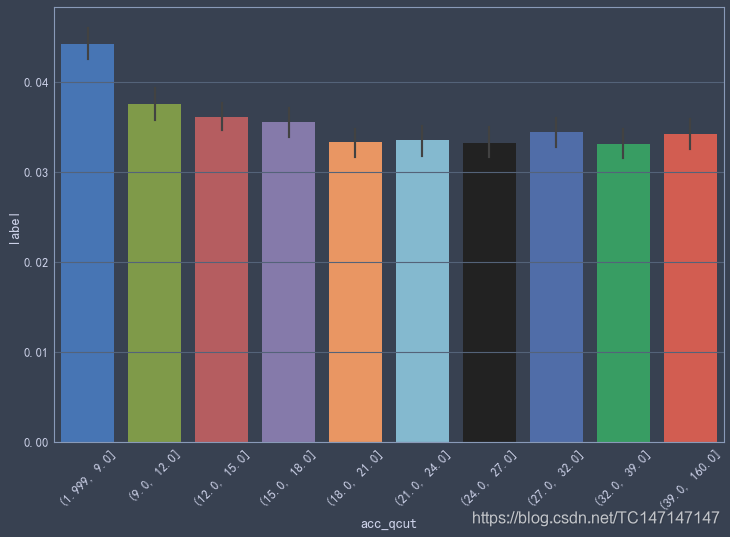
可以看出total_acc(正在使用的信用产品数量)与违约率关系不大,当total_acc数值较低时,违约率相对较高;当total_acc数值较高时,比如大于18时,违约率与total_acc关系不大,可能是信用产品偏多的贷款人,他们的信用经过其他产品的检验,违约率自然就偏低。
信用等级
sns.barplot(x='grade', y='label', data=data_2018, order=list('ABCDEFG'))
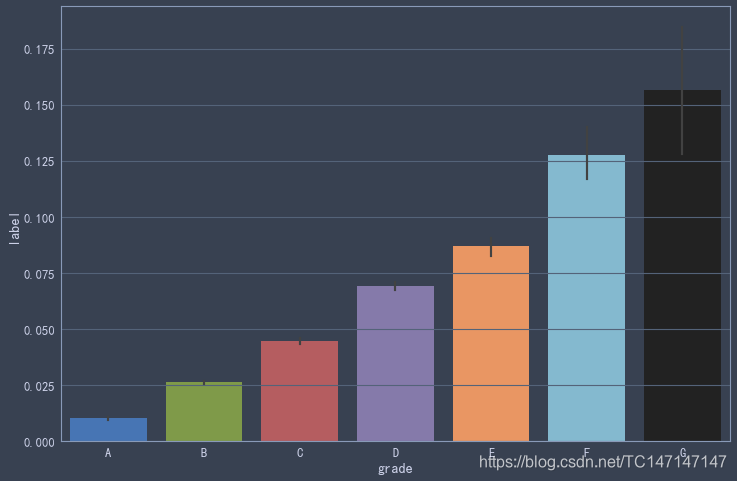
能看出对信用评级比较差的,F、G这类的贷款人,还款期还没结束,就有超过10%会违约或拖欠还款,可能你有疑问还有人敢借给他们吗,这里涉及到一个背景知识,在LendingClub平台上,投资人和贷款人并不是一对一的,一个投资人对应几十个贷款人,分摊了风险。
data_2018.head()
| issue_d | annual_inc | term | loan_amnt | int_rate | verification_status | home_ownership | emp_length | purpose | grade | total_acc | dti | loan_status | year | month | verify | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-12-01 | 55000.0 | 36 months | 2500 | 13.56 | Not Verified | RENT | 10+ years | debt_consolidation | C | 34.0 | 18.24 | Current | 2018 | 12 | 0 | 0 |
| 1 | 2018-12-01 | 90000.0 | 60 months | 30000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 44.0 | 26.52 | Current | 2018 | 12 | 1 | 0 |
| 2 | 2018-12-01 | 59280.0 | 36 months | 5000 | 17.97 | Source Verified | MORTGAGE | 6 years | debt_consolidation | D | 13.0 | 10.51 | Current | 2018 | 12 | 1 | 0 |
| 3 | 2018-12-01 | 92000.0 | 36 months | 4000 | 18.94 | Source Verified | MORTGAGE | 10+ years | debt_consolidation | D | 13.0 | 16.74 | Current | 2018 | 12 | 1 | 0 |
| 4 | 2018-12-01 | 57250.0 | 60 months | 30000 | 16.14 | Not Verified | MORTGAGE | 10+ years | debt_consolidation | C | 26.0 | 26.35 | Current | 2018 | 12 | 0 | 0 |
房屋所有权
tmp = data_2018[['home_ownership','label']].copy()
sns.barplot('home_ownership','label',data=tmp)
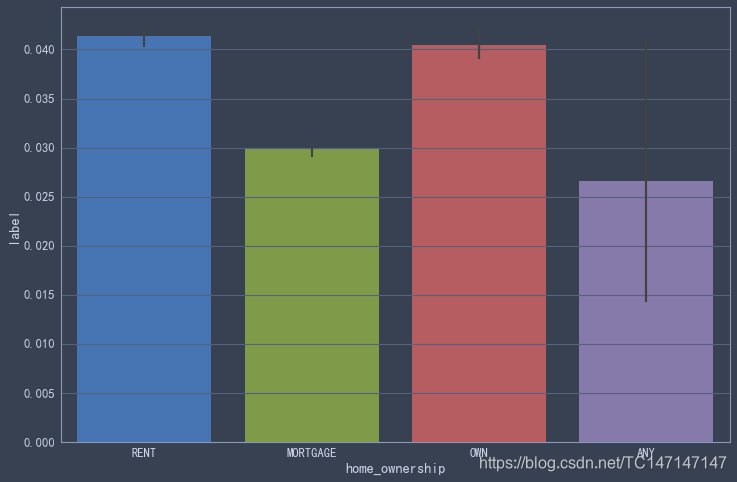
相对于租房和已有房的贷款人,按揭买房的贷款人违约率低很多,这是一个反直觉的结论。
贷款目的
tmp = data_2018[['purpose','label']].copy()
sns.barplot('purpose','label',data=tmp,ci=None)
plt.xticks(rotation=45)
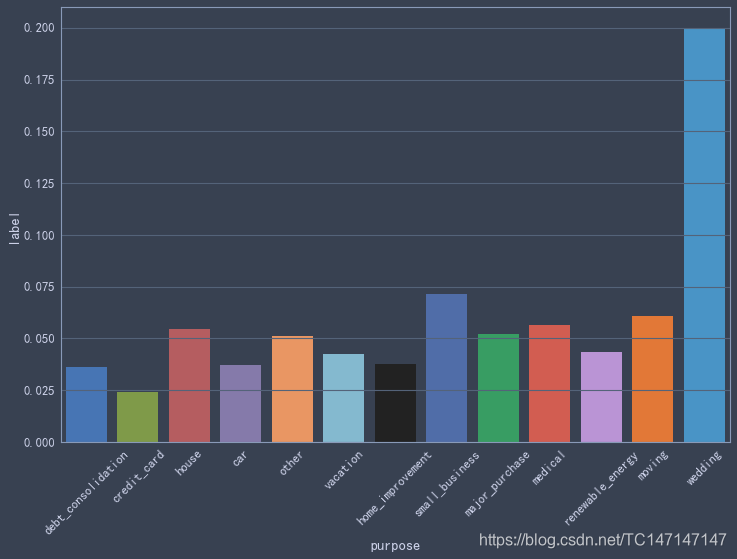
data_2018['purpose'].value_counts()
debt_consolidation 259642
credit_card 127702
other 35018
home_improvement 32748
major_purchase 11622
medical 6622
house 5430
car 4979
small_business 4583
vacation 3501
moving 3115
renewable_energy 275
wedding 5
Name: purpose, dtype: int64
虽然贷款目的是wedding的违约率最高,但是这个类型总共只有5人,样本量太小没有统计学意义。其他贷款目的的人数足够多,可以看到是small business的贷款人违约率最高,达到了7%。

















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









