






笔记:
基于脑PET图像的疾病预测
说明: NC指代健康
MCI指代轻度认知障碍 数据文件格式为.nii
整体流程:
1、准备正数据集与负数据集→供以学习
2、数据图片预处理 ①去噪
②增强
③对其标准空间
④图像标准化
3、预处理后提取特征①逻辑回归
②CNN (1)卷积层
(2)池化层
(3)全连接层
③Vision Transformer
4、模型训练→使用CNN监督学习①材料:使用预处理后的PET图、检查
②训练法:梯度下降、反向传播
③输入CNN训练:调整CNN权重、偏置
5、模型评估与优化→用训练好的模型与测试集得出结果,最后对①准确率
②精确率
③召回率
④F1值
6、根据最后结果再对模型的参数进行调整
从基线方案中得出代码整体框架:
1、导入所需的库与工具
2、读取文件(测试集与训练集)并打乱顺序
3、定义对PET图像进行特征提取的函数
①先加载图像,再得到第一个通道的数据
②随机筛选10个通道来提取特征
③对图片计算统计值(非零像素、零像素、平均值、标准差等…)
④通过看是NC还是MCI,将特征值放在样品旁边
4、对训练集与测试集分别进行30次特征提取
5、用训练集的特征作为输入,训练集的类别作为输出,对逻辑回归模型训练
6、对测试集进行预测并转置,使每个样品有30次预测结果
7、将30次预测结果中次数最多的结果作为最终预测结果,存储于test_pred_label
8、生成DataFrame,其中包括了样本ID与对应预测结果
9、排序结果并保存于.csv文件中
Summary↑:
第1到3步是前期的准备工作,第4到7步为预测结果,第8到9为保存文件
我出现的问题:
(下面是对基线代码保存到本地时,我出现的问题)
# 生成提交结果的DataFrame,其中包括样本ID和预测类别。
submit = pd.DataFrame(
{
'uuid': [int(x.split('/')[-1][:-4]) for x in test_path], # 提取测试集文件名中的ID
'label': test_pred_label # 预测的类别
}
)上面是基线方案中截取的代码,我的本地环境运行时uuid这里出现了问题
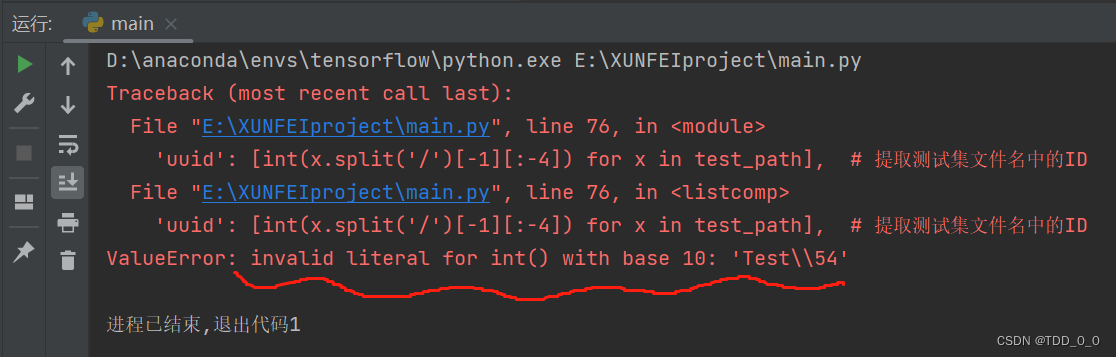
查阅资料知道是出现了字符串中有非数字内容,导致出错
通过调整代码发现原数据输出的非数字字符为下面图像↓
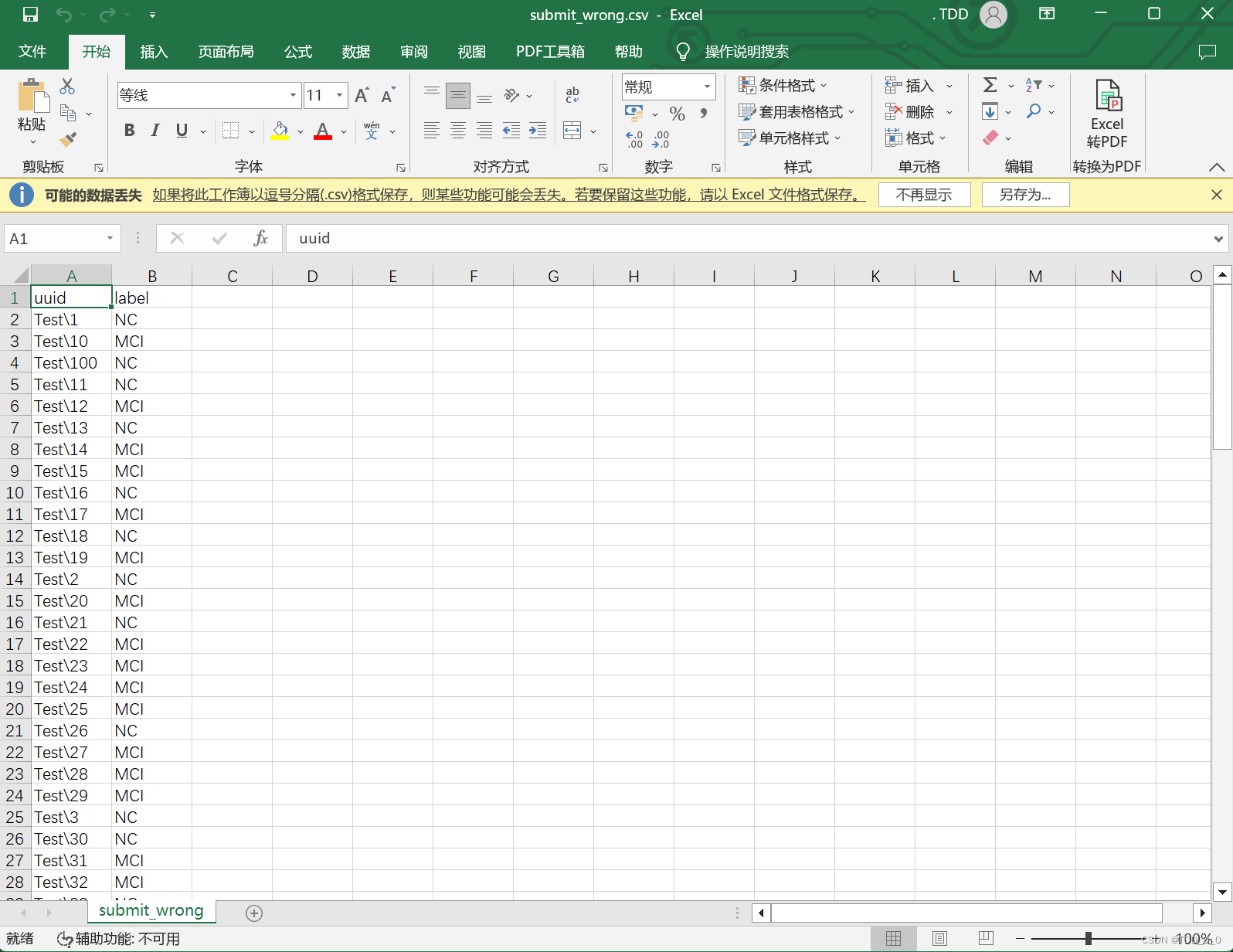
显然是“Test\”这个字符串导致问题,这个时候我们查阅split函数的用法
具体可以参考Python中超好用的split()函数,详解_python split_捣鼓Python的博客-CSDN博客
或Python学习:split()方法以及关于str.split()[0]等形式内容的详细讲解_景墨轩的博客-CSDN博客
调整过后以下是我的修改方案:
# 生成提交结果的DataFrame,其中包括样本ID和预测类别。
submit = pd.DataFrame(
{
'uuid': [int(x.split('/')[-1][:-4].split("\\")[-1]) for x in test_path], # 提取测试集文件名中的ID
'label': test_pred_label # 预测的类别
}
)主要是对于Python中split的学习与应用
就可以输出一个标准的格式↓
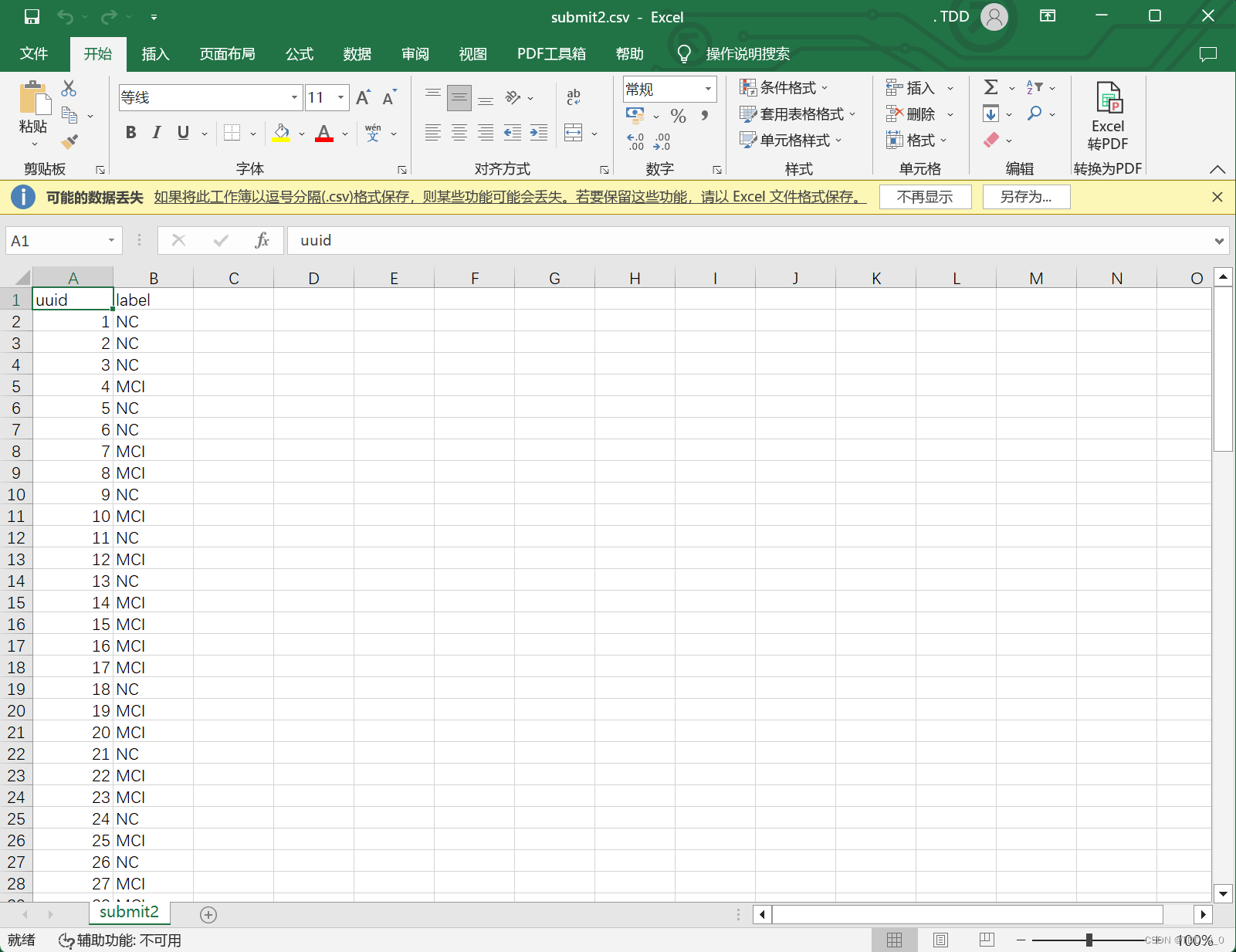
最后就完成本地环境的结果输出 !
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









